대학생때 자연어 처리에 관해서는 상당히 깊게 생각해 본 터이라
전문가는 아니더라도 기초적인 지식에 대해서는 상당히 꿰뚫고 있으나,
이미지 처리에 관해서는 전혀 문외하기에 (대충 원리만 추측할 뿐)
OpenCV 예제중 Digit_svm 이 있기에 이를 분석하는 글을 작성 해 본다.
해당 글은 전문적인 분석이 아니며, 짧은 시간을 투자한 글이므로 정확하지 않을 수 있다.
지적 댓글은 언제나 환영이다.

우선 Digit_svm 이란 Digit = 숫자, SVM = Support Vector Machine 으로서
숫자의 패턴을 통해 숫자를 판별하는 방법을 배우는 OpenCV 의 예제이다.
보통은 Python 을 통해 많이 작업하는데 이 글은 C++ 기준으로 예제에 관해 간략하게 해설한다.
OpenCV 를 CMake 를 통해 빌드 후 프로젝트에 진입하면
(sample) digits_svm 이라는 프로젝트가 눈에 보일것이다.

해당 프로젝트의 main() 을 기준으로 설명 시작하겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
int main(int /* argc */, char* argv[])
{
help(argv);
vector<Mat> digits;
vector<int> labels;
load_digits(DIGITS_FN, digits, labels);
cout << "preprocessing..." << endl;
// shuffle digits
shuffle(digits, labels);
vector<Mat> digits2;
for (size_t i = 0; i < digits.size(); i++)
{
Mat deskewed_digit;
deskew(digits[i], deskewed_digit);
digits2.push_back(deskewed_digit);
}
Mat samples;
preprocess_hog(digits2, samples);
int train_n = (int)(0.9 * samples.rows);
Mat test_set;
vector<Mat> digits_test(digits2.begin() + train_n, digits2.end());
mosaic(25, digits_test, test_set);
imshow("test set", test_set);
Mat samples_train = samples(Rect(0, 0, samples.cols, train_n));
Mat samples_test = samples(Rect(0, train_n, samples.cols, samples.rows - train_n));
vector<int> labels_train(labels.begin(), labels.begin() + train_n);
vector<int> labels_test(labels.begin() + train_n, labels.end());
Ptr<ml::KNearest> k_nearest;
Ptr<ml::SVM> svm;
vector<float> predictions;
Mat vis;
cout << "training KNearest..." << endl;
k_nearest = ml::KNearest::create();
k_nearest->train(samples_train, ml::ROW_SAMPLE, labels_train);
// predict digits with KNearest
k_nearest->findNearest(samples_test, 4, predictions);
evaluate_model(predictions, digits_test, labels_test, vis);
imshow("KNearest test", vis);
k_nearest.release();
cout << "training SVM..." << endl;
svm = ml::SVM::create();
svm->setGamma(5.383);
svm->setC(2.67);
svm->setKernel(ml::SVM::RBF);
svm->setType(ml::SVM::C_SVC);
svm->train(samples_train, ml::ROW_SAMPLE, labels_train);
// predict digits with SVM
svm->predict(samples_test, predictions);
evaluate_model(predictions, digits_test, labels_test, vis);
imshow("SVM test", vis);
cout << "Saving SVM as \"digits_svm.yml\"..." << endl;
svm->save("digits_svm.yml");
svm.release();
waitKey();
return 0;
}
|
cs |
load_digits 을 통해 트레이닝 시킬 이미지를 가져온다.

load_digits() 에서는 위에서 선언한 digits, labels 에 값을 할당해 주는 역할역시 수행한다.
여기서 사용되는 임시 이미지는 digits.png 라는 파일인데, opencv-master\samples\data 폴더 내에 존재한다.
가로 100, 세로 50 개의 숫자들로 총 5000 개의 숫자로 구성되어 있으며, 이를 각각의 숫자에 맞게 분류한다,
분류 체계에서는 split2d() 가 사용된다.
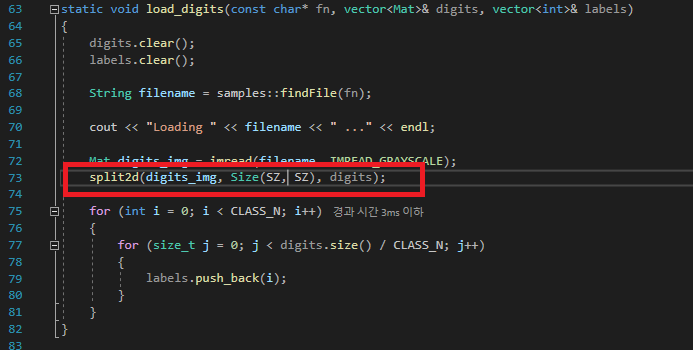
SZ 의 경우는 한 숫자가 차지하는 공간, 즉 CellSize 로서 20 이라는 상수값을 가지고 있다.
이미지가 2000 pixel * 1000 pixel 로 구성, 총 넓이는 = 2,000,000 Pixel
이를 CellSize 의 넓이에 해당하는 400 pixel 로 나누면 = 5000 이라는 값이 나오게 된다.
즉 커다란 이미지를, 기계학습을 위해 작은 이미지 단위로 '분류하는' 간단한 과정이다.

vector<Mat> digits; 의 경우는 분류를 위한 20 * 20 pixel 의 이미지를 담고 있고
vector<int> labels; 의 경우는 분류의 '답' 인 int 형의 숫자를 담고 있는 것이다.
인공지능의 기초를 학습한 사람이라면 '지도 학습' 은
문제에 대응하는 답이 존재해야 한다는 점을 알고 있을 것이다.
여기서의 Question - Answer 가 digit - label 이다.
그 다음 shiffle 함수를 통해서 섞는 과정을 거친다.
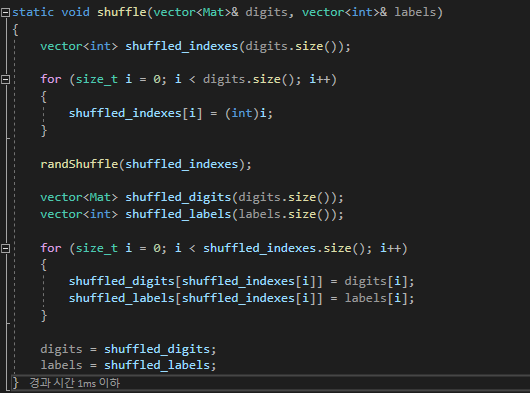
난수로서 섞어지는것이 아닌, 항상 일정하게 섞여진다.
다음으로 digits2 Vector<MAT> 을 선언한 후
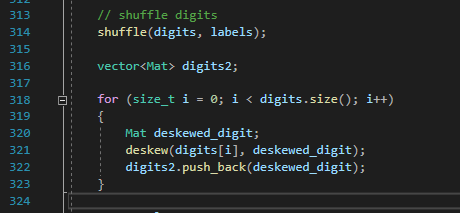
digits2 에서는 deskew 를 통해 '왜곡된' 이미지를 집어 넣는다.
여기서 '왜곡' 이란, 사람이 쓴 글자는 일정부분 '기울어져' 있는데, 이것을 바로 잡는것을 뜻하기도 한다.
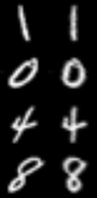
여기서 하나 재미있는 사실을 짚고 넘어가자면,
평상시 본인이 게임이나, 커뮤니티 가입을 위해 '숫자입력' 과 같은 행위들을 했을 것이다.
이를 캡챠(captcha) 라고 지칭하는데

이러한 captcha 중에선 '왜곡된 숫자' 를 기반으로 사용자를 판별하는 모델이 있다.
여기서 외곡을 'deskew' 와 같은 함수를 통해 글자들을 왜곡하고,

Google 측은 이를 '사람' 이 판별하게 함으로써, 왜곡된 숫자에 대해 '지도학습' Train set 을 확보한다.
deskew() 를 거치며 실행된 이미지를 보면 '이게 왜곡된거 맞아?' 생각이 들텐데.
deskew() 에 float skew 가 왜곡률' 을 정하는 함수이므로, 해당 함수의 왜곡률을 극단적으로 바꿔 준다면
실제 왜곡이 되는 모습을 육안으로 확인할 수 있다.
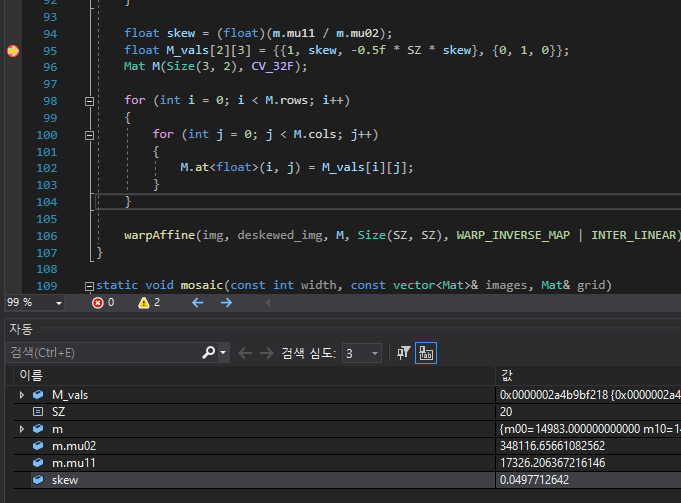
그에 상응되는 이미지
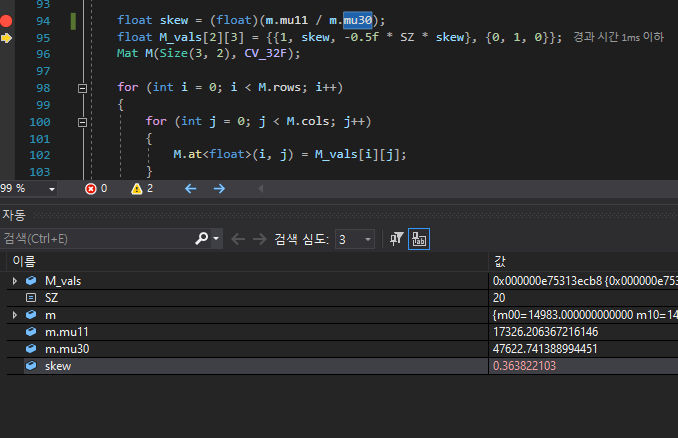
그에 상응되는 이미지, 알아보기가 힘든 글자들이 보인다.

물론 해당 deskew 함수는 해당 코드에서는 '사람이 쓴 기울어진 숫자' 를 똑바로 세우는데 사용되었지만
위와 같이 응용하여 기울어진 숫자를 사람들에게 제공하여, 이를 학습 train 으로 사용하는것도 가능하다.
그 후 preprocess_hog() 를 호출하는데,
Preprocessing_hog() 는 하단 포스팅을 참조하는것을 권장한다. 이미지 처리 알고리즘 중 하나이다.
[Image Processing] HOG Algorithm
참고자료 1 : http://sijoo.tistory.com/75 참고자료 2 : http://jangjy.tistory.com/163 참고자료 3 : http://web.mit.edu/vondrick/ihog/ (HOG Demo page) 참고자료 4 : https://en.wikipedia.org/wiki/Hist..
eehoeskrap.tistory.com
train_n 의 경우는 '학습 시킬 모델' 이다. samples.rows 의 0.9 값이니 4500 개를 학습 모델로,
500 개를 '판별 모델(테스트)' 로 사용하겠다- 라는 것을 추측 할 수 있다.
digit_test 에 digit2(왜곡, hog 적용한 vector).begin() + 4500 = 500 개 만큼의 test_set 을 집어 넣는다
해당 vector 는 train_set 으로 학습된 데이터의 정확성을 판별하는 데 이용 될 예정이다.
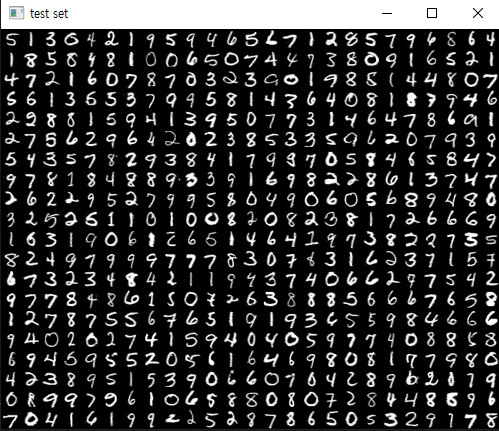
그 후 보이는 mosaic() 는 이러한 숫자 이미지를 하나씩 재 조립하여 하나의 Grid 를 만든다.
보다 쉽게 설명하면

위 퍼즐처럼 아까 shuffle() 을 이용해 뒤섞어 놓은 이미지를 맞춘 것 이다.
그 후 이를 imshow() 를 이용해 form 을 띄워준다.
form 은 반드시 mosaic() 가 진행된 vector<Mat> 을 이용해 Mat 을 만들어 사용해야 한다.
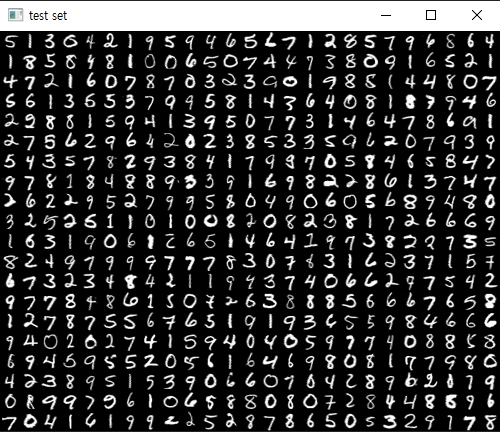
출력된 testSet,
아직 아무것도 진행하지 않았고 단지 '이걸로 이제 테스트 할거임, 테스트 할 표본이니까 함 봐봐'
라고 알려주는 화면이다.
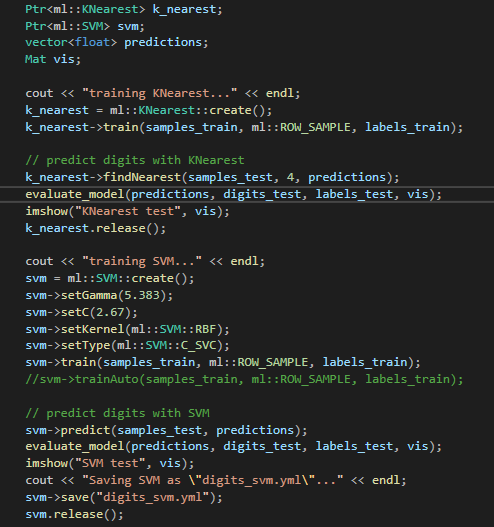
그 후 코드는 이제 본격적인 train set 제작, 및 test 코드이다.
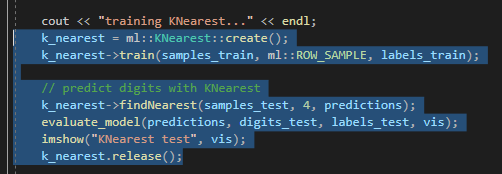
k-최근접 이웃 알고리즘 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 패턴 인식에서, k-최근접 이웃 알고리즘(또는 줄여서 k-NN)은 분류나 회귀에 사용되는 비모수 방식이다.[1] 두 경우 모두 입력이 특징 공간 내 k개의 가장 가까운
ko.wikipedia.org
최근접 이웃 알고리즘을 통한 train set 설정.
모델구현 -> release()
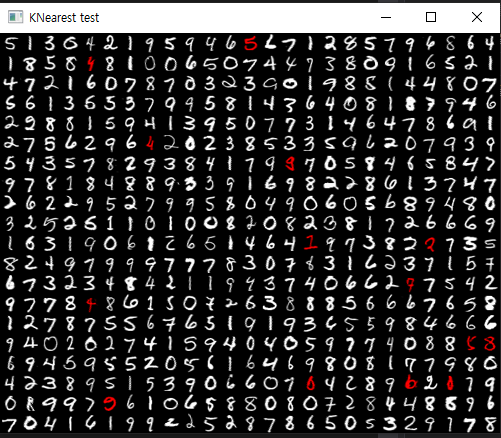
k_nearlist->findNearest(samples_test, 4, predictions) 를 거치고 나면 아까 지정했던
500개의 test set 에 대한 결과를 도출한다.
predictions vector 에서 그 결과를 살펴 볼 수있는데,
위 이미지에서 숫자 '5' 가 빨간색임을 보아 '잘못' 예측하였다는 의미인데,

실제로 메모리 상에서 숫자 6 을 8로 잘못 예측하였다는 점을 알 수 있다.
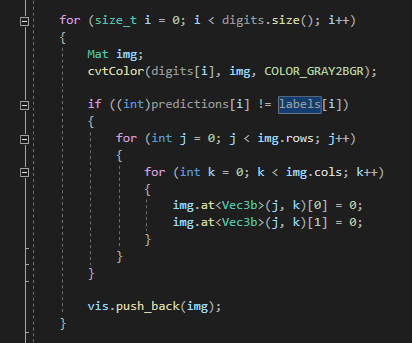
evaluate_model 함수에서는 아까 저장했던 testSet 의 '정답' 인 label 과
현재 우리가 예측한 predictions 값을 비교하여
잘못된 경우 색상을 교체한다.
최근접 이웃 알고리즘의 경우는, 특별히 설정 내역이 없는것 같다.
(있을수도 있다, 나는 이 알고리즘 동작 원리도 정확히 모른다)
그리고 SVM (서포트 벡터 알고리즘) 이다.

감마, C 와같은 학습과정에서 설정할 수 있는 셋팅값들을 변경할 수 있다.
여기서 필자가 주석으로 걸어둔 trainAuto 를 사용하면
여러번의 train 을 거친 후 최상의 Gamma, C 값을 설정 해 준다고 한다
K-Fold 교차검증
KFold 교차검증에 대해 알아봅시다.K개의 데이터 셋을 만든 후 K번 만큼 1) 학습, 2) 검증을 수행한는 방법위키 피디아 설명교차검증은 목적은 모델의 성능 평가를 일반화하는것모델의 성능을 직접
velog.io
설정된 파라미터를 봐서는 일종의 교차검증 알고리즘을 이용하는듯 싶다.
때문에 반복적으로 train_svm() 을 돌려 결과값을 비교하기때문에
그냥 train() 대비해서 시간이 오래 걸리는것을 알 수 있다.
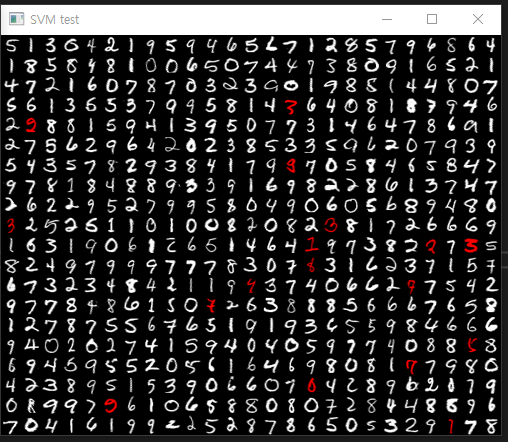
결과물 : 97.6% 의 정확도를 보여준다.
끝.
필자도 짧은 시간내에 굉장히 간단하게 분석한거라 추후 인공지능 분야로 진로를 잡으려면 한다면
추가적인 공부를 더 해야 할 것 같다
'Programming > C++' 카테고리의 다른 글
| [C++] openSSL Hash 사용법 (0) | 2021.05.12 |
|---|---|
| [C++] C# 측으로 Struct 를 UDP 로 전송 (0) | 2021.04.15 |
| [C++] TCP 통신 (0) | 2020.12.20 |
| [C++] 람다식 mutable 의 쓰임세. (0) | 2020.12.07 |
| [C++] push_back vs emplace_back 차이점 (2) | 2020.12.07 |