
1. CGAN 이란?
이전 포스팅에서 GAN이 무엇인지, 그 개념과 간단히 코드를 작성해 보았다. 이번 포스팅의 주제는 CGAN 이다.
이전 포스팅에서는 0~9 까지의 숫자를 임의로 랜덤하게 생성하는 Generator(생성기) 와 Discriminator(판별기) 를 생성하여 간단하게 GAN 모델을 구현해 보았다. 그런데 문제는 우리가 생성하는 데이터를 '지정' 할 수 없었다는 점이다.
즉, 숫자 '3' 만 출력하는 Generator 를 제작하는 것은 이전 포스팅만 보고는 불가능한 일이다. 때문에 해당 포스팅에서는 '특정한' 클래스를 훈련시킬 수 있는 Conditional(조건부) GAN 에 대해서 포스팅 하고자 한다.

2. CGAN 만들기
우리는 이전 포스팅에서 사용했던 파일을 이용해 조금의 수정만 거치고자 한다.
2-1 Discriminator
먼저 판별기(Discriminator)부터 수정한다.
Source Code - Discriminator - forward()
def forward(self, image_tensor, label_tensor):
# torch.cat() 는 단순히 하나의 텐서를 다른 텐서에 잇는 역할을 수행한다.
inputs = torch.cat((image_tensor, label_tensor))
return self.model(inputs)이 torch.cat() 는 단순히 하나의 텐서를 다른 텐서에 잇는 역할을 수행한다. 여기서는 기존 이미지 텐서는 278(28*28) 이며 레이블 텐서의 길이는 10 이므로 두 텐서를 이은 텐서의 길이는 794 이다.
여기서, 뒤에 잇는 레이블 텐서의 의미는 우리가 어떤 숫자를 뽑아낼 것인지 지정하는 숫자(0 ~ 9) 이다.
입력을 확장했기 때문에 신경망의 첫 번째 레이어 정의 시의 크기 역시 변경되어야 한다.
Source Code - Discriminator - self.model
# define neural network layers
# dataset 클래스로부터 반환된 이미지 텐서의 길이는 28*28=784 이며
# 레이블텐서의 길이는 10 이므로 (0~9까지의 숫자!) 두 텐서를 이은 길이는 794 이다.
self.model = nn.Sequential(
nn.Linear(784 + 10, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 1),
nn.Sigmoid()
)신경망의 크기는 기존 784 크기가 아닌 784+10 크기로 지정한다.
여기서 이 784+10 과 같은 표기가 매우 샤프하다고 느꼇는데, 실제로 뭐가 어떻게, 또 어떤 의미로 변경되었는지 매우 가시성있게 표기할 수 있기 때문이다.
추가로 train() 역시 변경한다.
Source Code - Discriminator - train()
def train(self, inputs, label_tensor, targets):
# calculate the output of the network
outputs = self.forward(inputs, label_tensor)
# calculate loss
loss = self.loss_function(outputs, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()해당 train() 에서 변경된것은 함수 첫 구문인 outputs 대입 구문 뿐이다. 위에서 수정한 forward() 의 입력 parameter 로 label_tensor 가 필요해서 바꾼것 뿐이다.
이와 같은 간단한 변경을 거친뒤 판별기를 테스트 해 볼 수 있다.
Source Code - Test Discriminator
D = Discriminator()
# 판별기 테스트
for label, image_data_tensor, label_tensor in mnist_dataset:
# 실제 데이터
D.train(image_data_tensor, label_tensor, torch.FloatTensor([1.0]))
# 생성된 데이터 (막무가내로 생성된 랜덤 이미지이니 당연히 정답셋을 0로 설정)
D.train(generate_random_image(784), generate_random_one_hot(10), torch.FloatTensor([0.0]))
2-2 Generator
Generator 도 마찬가지로 forward() 를 업데이트 한다
Source Code - Generator - forward()
def forward(self, seed_tensor, label_tensor):
# 시드와 레이블 결합.
inputs = torch.cat((seed_tensor, label_tensor))
return self.model(inputs)똑같이 입력값을 +10 증가시킨다.
Source Code - Generator - self.model
# 네트워크의 첫 번째 레이어는 10개의 (0-9) 값을 다루도록 수정됨.
# 생성기인 만큼 해당 클래스 값을 입력받아 최종적인 출력 (784) 로 변환함.
self.model = nn.Sequential(
nn.Linear(100 + 10, 200),
nn.LeakyReLU(0.02),
nn.LayerNorm(200),
nn.Linear(200, 784),
nn.Sigmoid()
)train() 역시 마찬가지로 G.forward() 와 D.forward() 에 전달할 레이블 텐서값을 전달하도록 수정한다.
Source Code - Generator - train()
def train(self, D, inputs, label_tensor, targets):
# calculate the output of the network
g_output = self.forward(inputs, label_tensor)
# pass onto Discriminator
d_output = D.forward(g_output, label_tensor)
# calculate error
loss = D.loss_function(d_output, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()마지막으로 훈련시킨 Generator 에 대해서 특정 값을 뽑아내기 위한 함수를 제작하여 삽입한다.
Source Code - Generator - train()
def plot_images(self, label):
label_tensor = torch.zeros((10))
label_tensor[label] = 1.0
# 2행 3열로 이미지 출력
f, axarr= plt.subplots(2,3, figsize=(16,8))
for i in range(2):
for j in range(3):
axarr[i,j].imshow(G.forward(generate_random_seed(100), label_tensor).detach().cpu().numpy().reshape(28,28),
interpolation='none', cmap='Blues')
2-3 Train
만약 실습을 하고 있다면 해당 코드를 실행한 뒤 산책이라도 다녀오길 권장한다.
Source Code - train
%%time
# create Discriminator and Generator
D = Discriminator()
G = Generator()
epochs = 12
for epoch in range(epochs):
print ("epoch = ", epoch + 1)
# train Discriminator and Generator
for label, image_data_tensor, label_tensor in mnist_dataset:
# True 값에 대해 판별기 훈련
D.train(image_data_tensor, label_tensor, torch.FloatTensor([1.0]))
# 임의의 원핫 인코딩된 벡터를 레이블로 사용
random_label = generate_random_one_hot(10)
# False 값에 대해 판별기 훈련
# G의 기울기가 계산되지 않도록 detach() 함수를 사용. (생성기가 학습되지 않도록!)
D.train(G.forward(generate_random_seed(100), random_label).detach(), random_label, torch.FloatTensor([0.0]))
# train generator
G.train(D, generate_random_seed(100), random_label, torch.FloatTensor([1.0]))Output - train
...
...
...
epoch = 11
counter = 1210000
counter = 1220000
counter = 1230000
counter = 1240000
counter = 1250000
counter = 1260000
counter = 1270000
counter = 1280000
counter = 1290000
counter = 1300000
counter = 1310000
counter = 1320000
epoch = 12
counter = 1330000
counter = 1340000
counter = 1350000
counter = 1360000
counter = 1370000
counter = 1380000
counter = 1390000
counter = 1400000
counter = 1410000
counter = 1420000
counter = 1430000
counter = 1440000
CPU times: user 3h 54min 16s, sys: 12.9 s, total: 3h 54min 29s
Wall time: 39min 5s5600x 를 통해 학습한 결과 약 40분 남짓의 시간이 소요되었다.
2-4 Result

판별기의 loss 값은 0으로 수렴하지 않는데, 이는 매우 좋은 징조이다. GAN의 이상적인 손실값은 0가 아니기 때문이다. 적절한 손실값을 유지해 주면서 Generator와 Discriminator 가 박터지게 싸워줄수록 유의미한 데이터를 얻기 때문이다.
그리고 이미지 '생성' 부분 면에서 보면 Discriminator 의 loss 값이 하강했다가, 점진적으로 상승하는게 좋다. 이런면에서 Discriminator 점진적으로 미약하게 '증가' 하고 있으므로 좋은 징조이며, Generator 역시 평균 0 가 아닌채로 적절히 낮은 loss 값을 유지하고 있으므로 학습이 매우 잘 되고 있다는 의미이다. (결론적으론 loss 값이 균형을 이루는게 좋다)
이제 최종적인 결과를 살펴보자!
Source Code - result
# 9 란에 원하는 숫자를 적어보자!
G.plot_images(9)
아래 이미지는 딱히 좋은 결과만 나온것을 추린것이 아닌, 곧바로 나온 결과를 첨부한다.
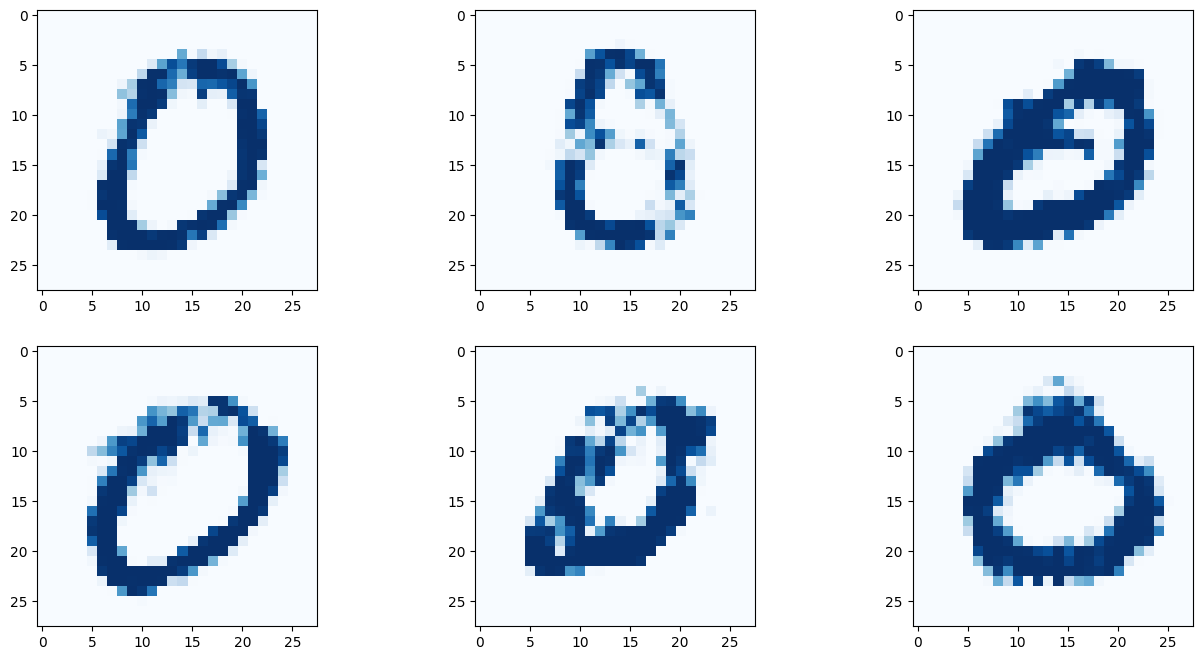
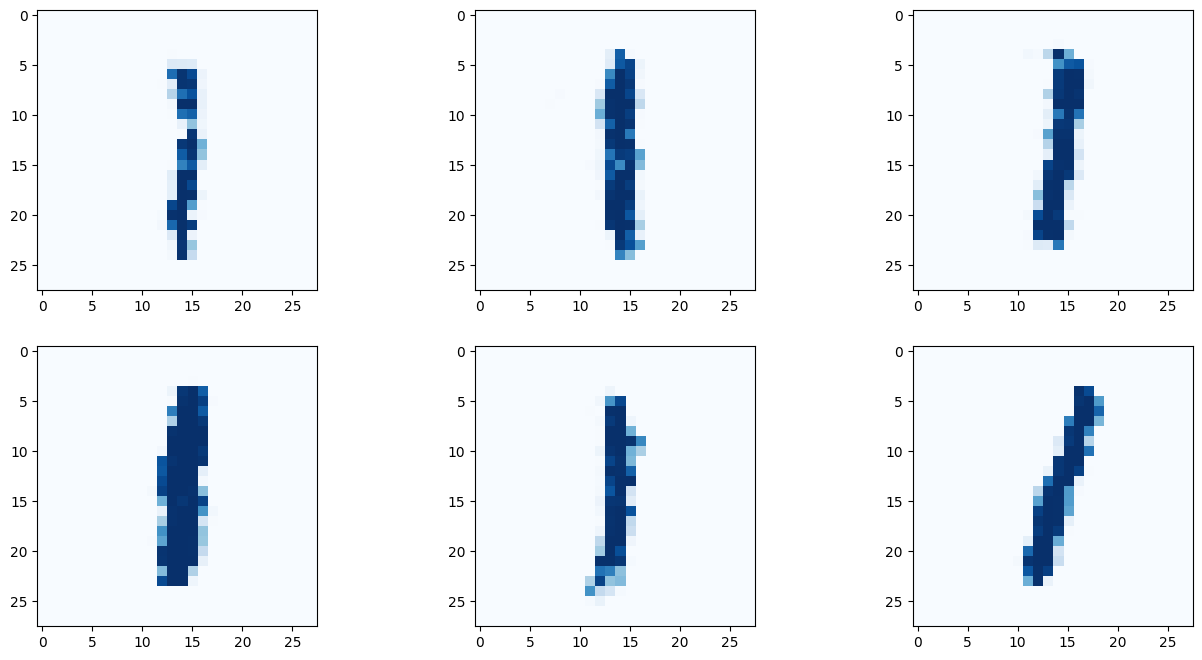
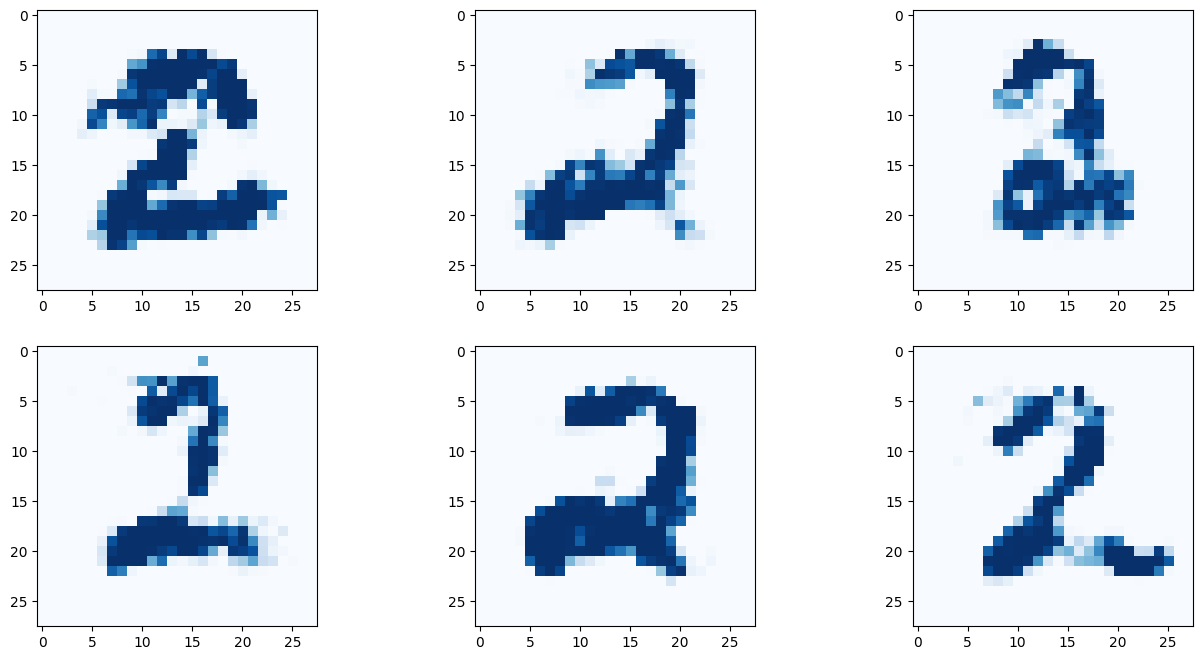
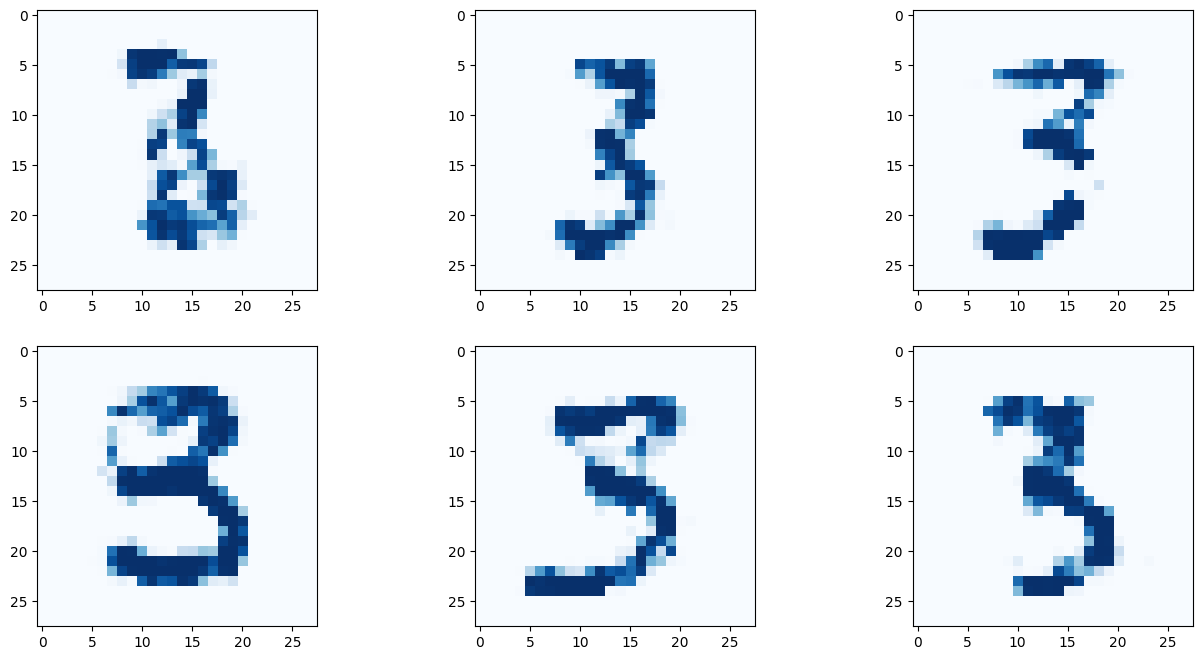

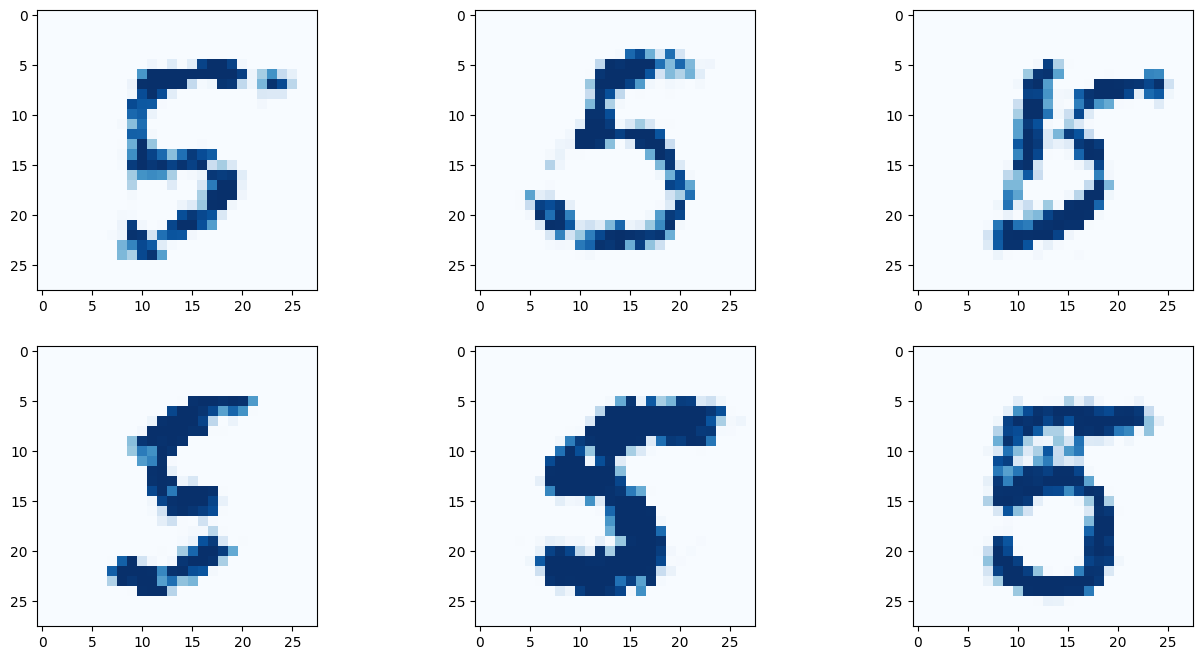
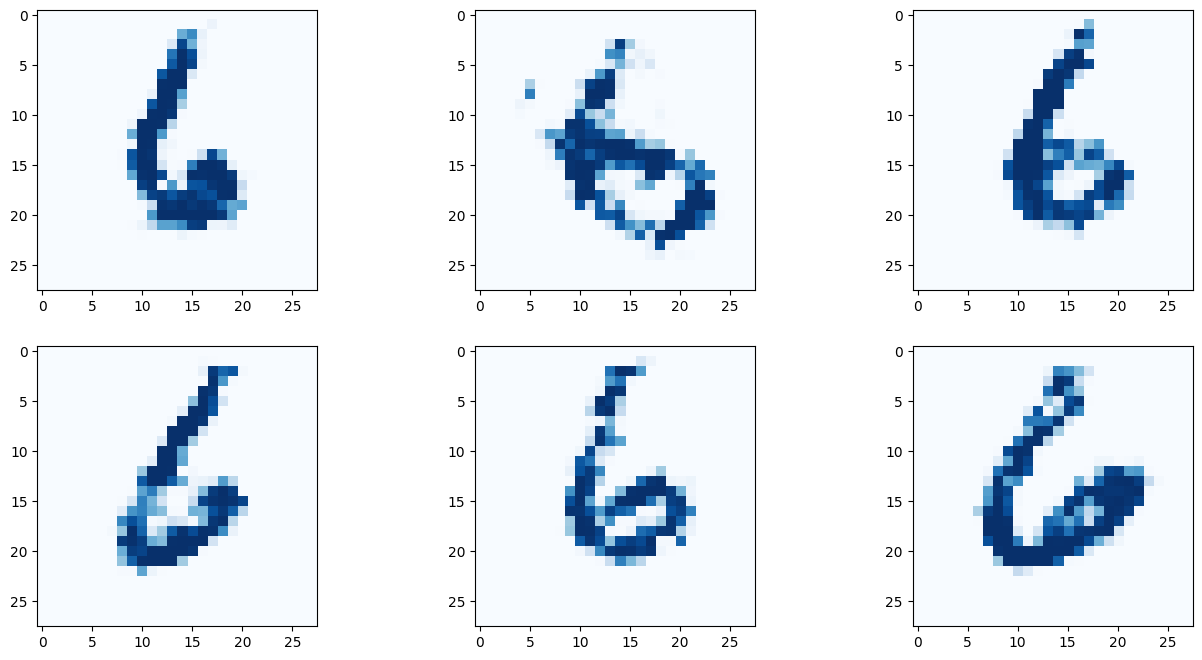
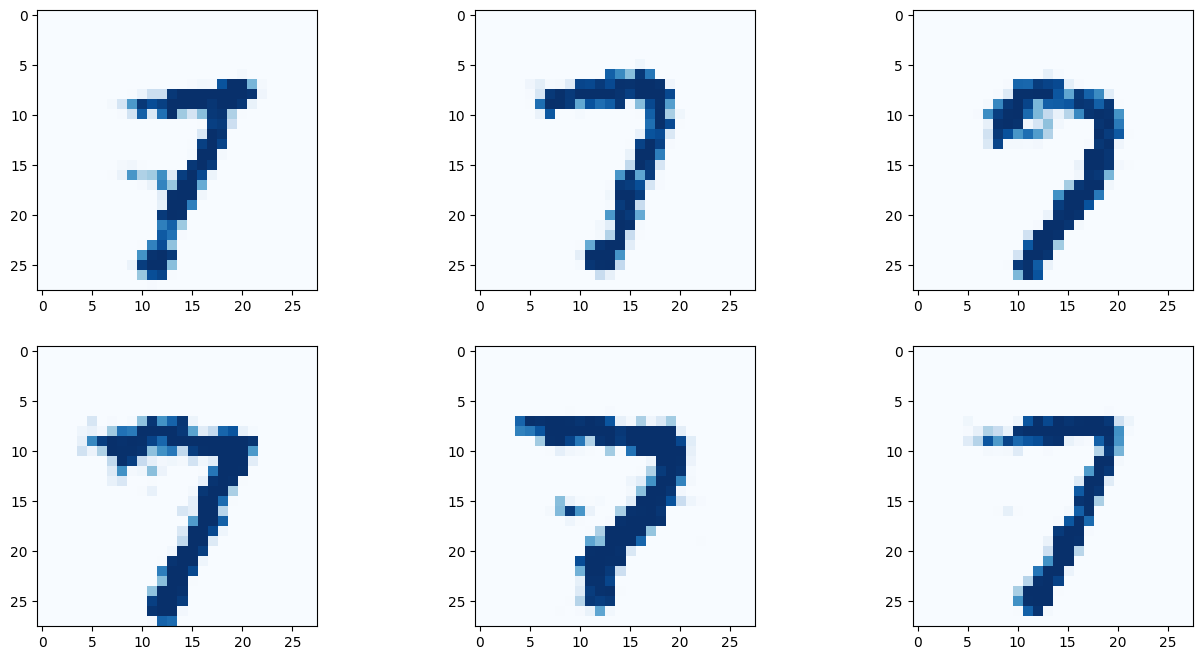
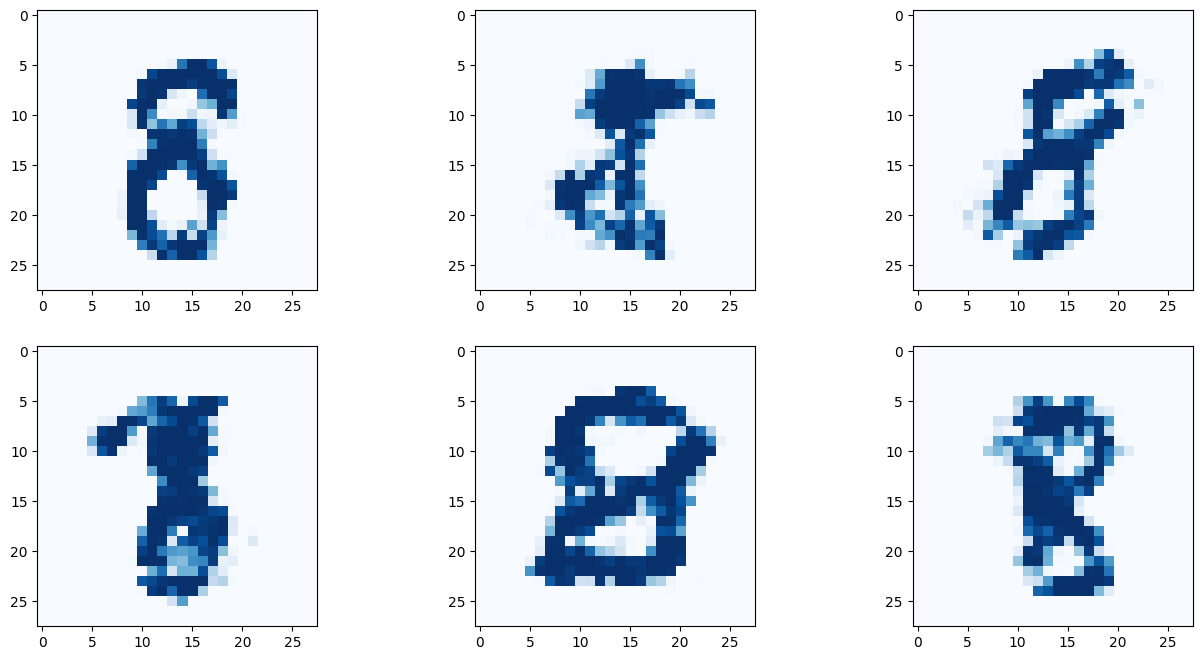
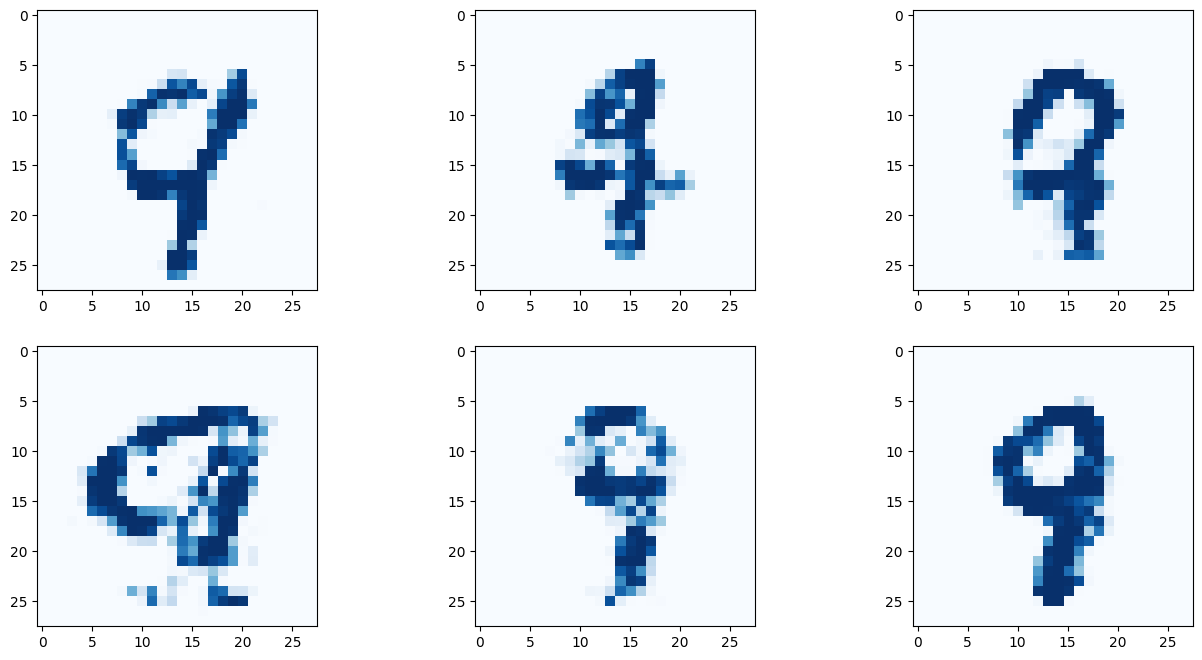
결과를 보면 간단히 작성한 코드만으로 유의미한 결과를 도출해 낼 수 있다! 몇몇 이미지는 사람이 쓴것과 구별할 수 없을 정도다!
3. 마치며
신기한 점은 조건부 GAN은 → 레이블 정보를 받지 않는 일반적인 GAN 대비해서 더 좋은 품질의 이미지 데이터를 생성한다는 점이다. 이러한 이미지 생성은 '그림을 생성하는 AI' 에도 적용 될 것으로 추측된다.
때문에 Stable-Diffusion 등을 사용할 때 흔히 Tag(Boy, Realistic, Soldier, etc...) 를 통해 생성할 이미지를 지정하곤 하는데, 아마 이러한 Tag가 plot_images(label) 란과 매칭되는듯 싶다. 즉, 이러한 태그를 통해 보다 높은 품질의 이미지를 낼 수 있는것이다. 이는 '선별' 학습 효과의 부산물로 인한 결과라고 생각된다.
'Artificial Intelligence > Basic' 카테고리의 다른 글
| 인공지능에서 Parameter 란? (0) | 2024.01.27 |
|---|---|
| GAN의 최적 손실값 (1) | 2023.06.19 |
| GAN이란? (이미지 숫자 생성) (0) | 2023.06.07 |
| 벨만 방정식(Bellman Equation) (0) | 2023.05.29 |
| 마르코프 결정 프로세스(Markov Decision Process) (0) | 2023.05.28 |