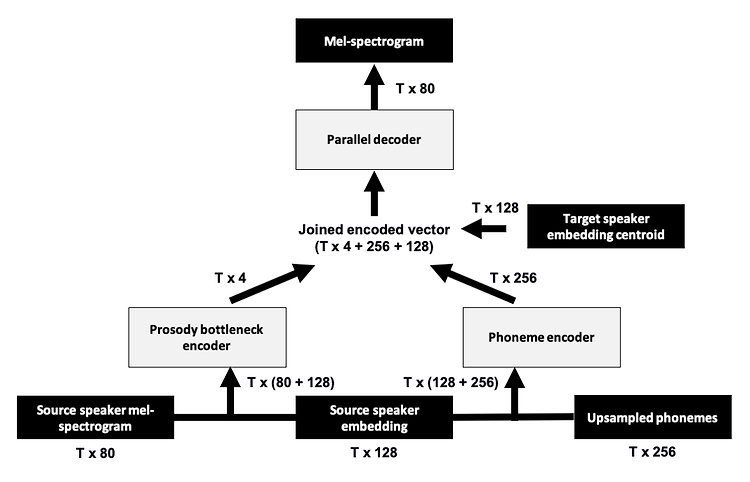
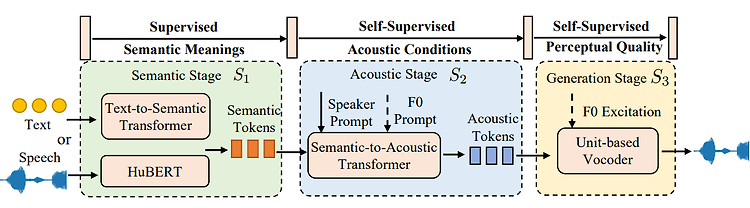
[리뷰] DeepSeek-V3 Technical Report
·
Artificial Intelligence/Article
해당 포스팅은 PC 환경에 최적화 되어 있습니다. DeepSeek 라는 중국의 스타트업에서 만든 V3 모델은, OpenAI의 4o 모델에 대응되는 모델로서, 그 성능이 4o와 유사하면서, 추론 비용이 압도적으로 저렴하기에 현재 AI 커뮤니티에서 큰 파장을 불러일으키고 있다.논문의 Abstract 란에서 바로 벤치마크를 살펴볼 수 있다. Transformer 모델인 만큼 전반적인 벤치마크 수준은 o1, R1 모델 대비 낮지만, 벤치로 식별하기 어려운 창의적인 대화에서는 더 높은 성능을 보여준다. 1. 소개최근 몇년간 LLM 모델은 진화를 거듭하면서 AGI에 다가가고 있다. 대표적으로 ChatGPT, Claude, LLaMA, Qwen 등을 꼽을 수 있다. 이러한 변화의 물결에 올라, DeepSeek 사는 ..