
Mozilla Common Voice
commonvoice.mozilla.org
Common Voice 데이터셋 + AI 모델로 여러 테스트를 거쳤는데
내가 원하는 방향의 결과가 나오지 않았고,
어떤 문제 때문일까 고심하던 차에 데이터 표본 자체를 신뢰할 수 없겠다는 결론을 내렸다.
그냥 원하는 결과 안나와서 땡깡부리는거 아니냐!
할 수 도 있겠지만 나름대로 근거가 있다.

우선 Common Voice 의 경우 Mozilla 제단에서 제공하는 음성 데이터 셋이다.
한국어를 비롯한 세계 여러 언어의 음성 데이터를 제공하며,
개인들이 직접 녹음할 수 있고, 이를 평가할 수 있다.
마치 Wikipedia 같은 방식이라고 볼 수 있다.
나는 개인적으로 Wiki 가 가진 시스템의 장점이 참 마음에 드는데,
결국 규모를 키우는데는 이만한게 없기 때문이다.
한국의 나무위키만 봐도 공감할 것이다.

하지만 아무래도 이런 시스템의 단점이라면 '정보의 정확성' 문제가 있다.
어느정도 자료조사의 기초를 공부한 사람이라면
위키 정보를 그대로 옴겨적는 일은 하지 않을것이다.
위키는 어디까지나 정보를 겉으로 핥는 용도이며,
그 겉핥기를 토대로 진위를 확인할 필요성이 있다.
보통 기사나, 논문 등을 확인한다.
Common Voice 측에서도 이런 문제를 인지 못 하고 있는것은 아니다.
때문에 Validated 라는 명목으로 사람들에게 '평가' 받은 데이터들을 'Validated' 로 분류하고 있다.

사실 나도 이거에 낚여서 3일정도 시간을 허비했는데,
이 Validated 를 곧이 곧대로 믿으면 안된다.
Common Voice 는 음성에 관해서 여러 메타데이터 정보를 제공하는데,
연령정보나, 억양과 같은 데이터를 제공한다.
나의 경우, 음성의 '연령' 메타데이터 정보가 굉장히 중요했다.
한국에서 개인정보는 다소 경시되는 경향이 있어서 연령, 지역, 성별 등 발화자의 부가정보를 쉽게 얻을 수 있지만
영어 데이터에서 이러한 메타 데이터를 얻기란 매우 힘들다.
그나마 영어 음성 데이터셋 중 Common Voice 에서 이런 연령 정보를
특정 범위 내에서 제공하기에 연구 자료로 사용 하려고 하였는데,
저 Validated 라는 말에 너무 무게를 둔 것 같다.
이쯤해서 서론은 집어치우고, Common Voice 의 문제점에 관해서 이야기 하겠다.
1. Validated 데이터셋의 검증 기준이 너무 느슨하다

위에서도 언급했듯이 이러한 데이터를 제 3자가 '평가' 한 데이터셋을
Validated 라고 말한다. 즉 '검증되었다' 라는 의미이다.
검증 방식 자체는? 옳다고 본다.
그런데 문제는 이게 과반수만 넘는다고 되는 투표도 아니고...
예시로, 어떤 음성 데이터에 대해서 3명중 2명이 '옳다' 고 투표하고
1명이 '옳지 않다' 고 투표한다면
해당 데이터셋을 Validated 라고 분류하면 안된다고 생각한다.
하지만 Common-Voice 에서는 ${2 \over 3}$ = 66% 정확도도 Validated 셋으로 간주한다...
그나마 이정도는 양반이고,
몇몇 자료들은 ${4 \over 7} =$ 57% 같은 상황이다.
예측해보건데
2표이상에 up_votes 비율이 50% 이상이면 Validated 되었다고 분류하는것 같다.
듣는 사람중에서 절반 가까이가 '이거 아닌거같은데?' 라고 말하는 음성을
어떻게 Validated 라고 이름붙여서 데이터셋으로 만드는지 잘 이해가 안된다.
2. 투표 수가 적다.
대충 눈대중으로 말하려다가
그래도 비판글인데 명확히 해야겠다 싶어서 분석한 결과를 보여주면
up_votes
2 1455754
3 162601
4 126231
6 16095
5 8358
8 3529
7 2761
10 2337
...
...
down_votes
0 1508496
1 248787
2 21693
3 2294
4 741
5 313
6 137
7 77
8 51
9 33
10 24
11 24정도의 투표수를 보유중인데,
2건의 찬성 투표를 받은 음성파일을 과연 Validated 라고 말할 수 있을까?
심지어 총 Validated 데이터셋이 177만개이다.
근데 그 중 145만개(81%)가 단 2건의 투표만 받은것이다.
이걸 신뢰할 수 있겠는가?
물론 위에서 언급한 나무위키 등과는 다르게
어느정도 데이터 구축에 관심이 있는 사람들이 청취후에 투표한 것이지만
본질적으로 나무위키와 Common Voice 는 다를게 없다.
오히려 명확한 기준을 가진 단일 전문가가 분류한것이 훨신 나을것이다.
실제로 나는 데이터들을 확인중
2건의 찬성표, 1건의 반대표를 받은
Common_voice_en_71615.mp3
파일의 문제점을 발견하여 Mozilla 제단에 보고하였다.
해당 파일은 녹음 정지버튼을 누르지 못한 것으로 추정되는데
발화자가 문장을 말한 뒤에 약 6분 가량 음성파일이 끊어지지 않고
주변 대화소리가 들려오는 잘못된 파일이였다.
아니 이런 파일도 못 걸러진 데이터셋을 'Validated' 라고?
(당연히 용량부터 수십배 차이가 난다)
라는 생각이 들 수 밖에 없다.
3. MetaData 를 믿을 수 없다.
한국에서 수집되는 정보들은 보통 Metadata 를 같이 제공해 주는 경우가 많이있다.
특히 한국 AI hub 에서 제공되는 데이터들은
연령, 지역, 성별등 많은 메타데이터를 제공해 주는데
이런 정보들은 기관을 거쳐 검증된 정보만을 제공하는 것이다.
하지만
해외에서는 논문 검증용으로 사용되는 LibreSpeech 도 그렇고
Transcript 를 제외한 상세한 메타데이터를 제공해 주는 데이터셋은 찾기가 매우 어렵다.
특히 공개 데이터 세트에서는 거의 불가능하다고 보면 된다.
그래도 나는 연령 정보가 필요했기에 Common Voice 를 선택했던 것인데,
문제는 이 연령 메타 데이터도 믿을 수 없다는데에 있다.
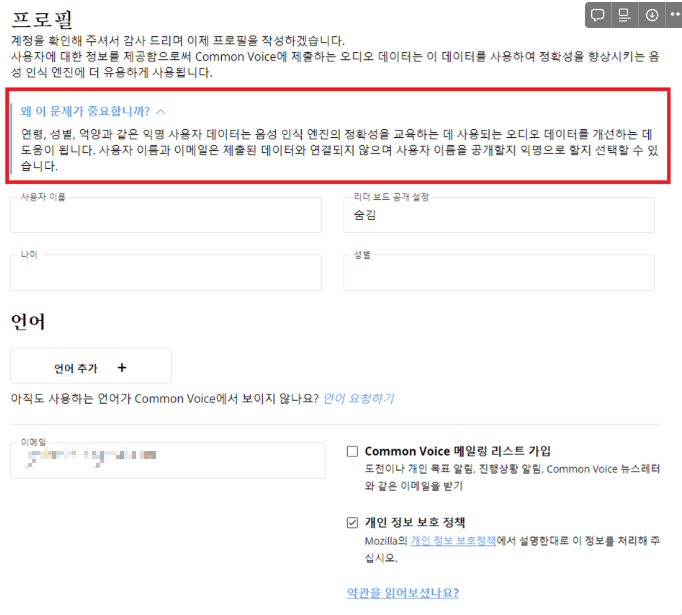
Common Voice 에 내 음성을 기여하다 보면
사용자에 대한 메타데이터를 기재할 수 있는 란이 있는데
여기에 아무 나이대, 아무 성별이나 입력해도
검증과정이 없다.
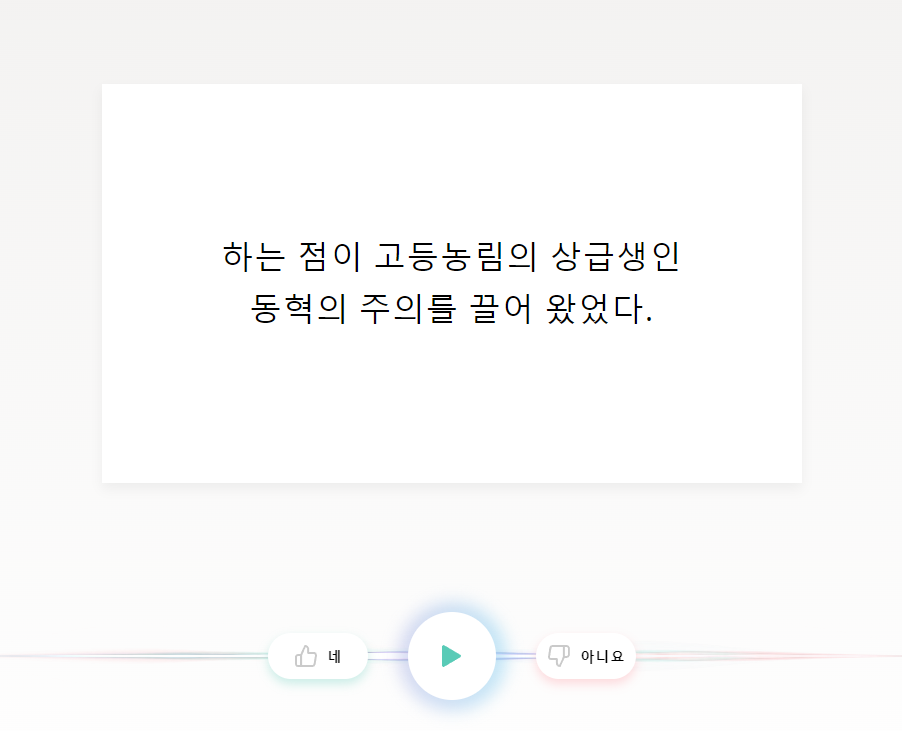
심지어 투표 과정에서도 메타데이터 정보에 관해서 평가자가 확인할 수 있는 것이 없다.
예로, 10대 여성이 장난이든 착오든 80대 남성으로 메타데이터를 잘못 기입했다고 해서
이걸 '평가자' 가 청취후 '메타데이터 잘못된거 같은데요?' 라고 할 수 없는것이다.
물론, 80대 남성같은 목소리를 내는 10대 여성이 없다는건 아니므로
애초에 명확한 검증방법 없이 이러한 메타데이터를 제공한다는 것 자체가 잘못되었다고 본다.
취지는 좋으나, 신뢰성을 떨어뜨리는 것이다.
4. 결론
물론 이건 2024년 1월 31일 기준으로 Common Voice 데이터셋을 신뢰하기 어렵다는 것이지
중장기적으로 Common Voice 의 정책 변경, 커뮤니티 활성화 등으로 인해
얼마든지 변경될 수 있다.
추가로 이러한 신뢰성은, 검증 기준이 잘못되어서 신뢰하기 어렵다는거지
내 느낌상 Transcript 기준 80% 이상은 올바르게 평가 된 것 같다.
현재 Validated 셋 기준해서 2,586 시간 정도의 데이터셋이 쌓여있는데,
보다 많은 사람들이 참여(특히 평가)해서 데이터셋을 유용하게 쓸 수 있으면 하는 바람이고,
나처럼 데이터셋을 찾아다니는 분들께 도움이 되었으면 좋겠다.
'Artificial Intelligence > Post' 카테고리의 다른 글
| [OpenAI] Superalignment (0) | 2023.12.15 |
|---|