Little Endian, Big Endian 에 대해 모르는 사람은 아래 포스팅을 참고하길 바란다.
리틀 엔디안 VS 빅 엔디안
먼저 둘을 비교하기에 앞서 엔디언이란 무엇인가? 엔디언(Endianness)은 컴퓨터의 메모리와 같은 1차원의 공간에 여러 개의 연속된 대상을 배열하는 방법을 뜻하며, 바이트를 배열하는 방법을 특히
genesis8.tistory.com
나는 15살때부터 프로그래밍에 입문하였으니, 놀면서 공부한 기간 8년 + 직업적으로 다룬 기간 2년해서
나름(???) 10년인데 ENDIAN 변환은 실무에 적용하려면 버벅이게 된다...
INT 가 4 바이트고, 1 바이트는 8 비트라는 기본적인 구조는 하도 외워서 개념적으론 알고 있지만.
이렇게 낮은 단위까지 고려하며 실무에 적용 할 일이 그리 많지 않기 때문이다.
그나마 백준같은 알고리즘 문제 풀다보면 Bit 단위까지도 다루게 되지만, 이때는 비트연산, shift 연산과 관련해서 쓰지
Endian 에 관해서 다루진 않기때문에 업무에 적용하려면 머릿속이 꼬인다.
그래서, 모호한 부분에 대해서 정리하기 위해 포스팅을 작성한다.
※ 예제 코드는 C++ 로 작성하였지만, 당신이 다루는 언어가 C#이든, JAVA 든 Rust 든 상관없이 포스팅은 유효하다.
1. Endian 의 개념은 'Byte' 단위에서 사용된다.
2 Byte 로 8,208 이라는 정수를 BIG_ENDIAN 으로 표현하면 아래와 같다.
0010 0000 0001 0000LITTLE_ENDIAN 으로 표현하면 아래와 같다.
0001 0000 0010 0000
이를 Visual Studio Code 에서 띄워보면
[위가 빅, 아래가 리틀]
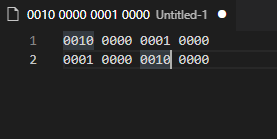
이처럼 나오는데, 8,208 이라는 숫자는 2BYTE 로 표현이 가능한 것을 알 수 있다.
여기서 ENDIAN 치환시에 서로 바뀌는 부분은

노란색과 빨간색 부분이 바뀌는 것이다.
위에서도 언급했지만 ENDIAN 에 적용되는 단위는 BYTE == 8 Bit 니까.
이를 Visual Studio 와 같은 IDE 에서는
BIG_ENDIAN == { 32, 16 }
LITTLE_ENDIAN == { 16, 32 }와 같이 표현 해 준다.
2. 변수에 삽입할때는 Little Endian 으로 삽입 하여야 한다.
x86 프로세서의 Endian 은 LITTLE_ENDIAN 이 기준이 된다.
ARM의 경우는 BIG_ENDIAN 으로도 운용이 가능하지만,
대부분 LITTLE_ENDIAN 으로 운용되니,
그냥 DRAM 내 변수에 '할당' 된다면 LITTLE_ENDIAN 으로 넣어주면 된다.
예를 들어, 위에서 언급했던 8,208 이라는 숫자를 INT 형에 삽입하기 위해서는
BIG_ENDIAN 기준인 { 0, 0 } + { 32, 16 } = { 0, 0, 32, 16 } 이 아닌,
LITTLE_ENDIAN 기준인 { 16, 32 } + { 0, 0 } = { 16, 32, 0, 0 } 으로 삽입 해 주어야 한다
#include <iostream>
int main()
{
char BIG_ENDIAN[4] = { 0, 0, 32, 16 };
char LITTLE_ENDIAN[4] = { 16, 32, 0, 0 };
int RESULT_BIG;
int RESULT_LITTLE;
std::memcpy(&RESULT_BIG, BIG_ENDIAN, sizeof(int));
std::memcpy(&RESULT_LITTLE, LITTLE_ENDIAN, sizeof(int));
std::cout << RESULT_BIG << std::endl;
std::cout << RESULT_LITTLE << std::endl;
}
C++ 은 BYTE 단위가 없으므로 char array 형식으로 표현한다. (잘 생각해 보면 왜 char [] 인지 알 수 있다)
다른 프로그래밍 언어에서는 byte[] 로 진행하면 된다.

빅 엔디안 값으로 삽입한 변수의 값은 제대로 출력되지 않는다.
반면 리틀 엔디안 값으로 삽입한 변수의 값은 올바르게 출력된다.
즉 BIG_ENDIAN 기준으로는
{ 0000 0000, 0000 0000, 0010 0000, 0000 1000 } == { 0x00, 0x00, 0x20, 0x10 } == { 0, 0, 32 16 }
LITTLE_ENDIAN 기준으로는
{ 0000 1000, 0010 0000, 0000 0000, 0000 0000 } == { 0x10, 0x20, 0x00, 0x00 } == { 16, 32, 0 0 }
같이 표현할 수 있다.
사람이 읽을때는 '빅 엔디안' 으로 읽으면 올바르게 8,208 이 나오지만,
컴퓨터 가 읽을때는 '리틀 엔디안' 으로 읽어야 올바르게 읽힌다는 사실을
명심하자.
추가적으로
#include <iostream>
int main()
{
int test = 8208;
char byte1 = test & 0x000000ff;
char byte2 = (test & 0x0000ff00) >> 8;
char byte3 = (test & 0x00ff0000) >> 16;
char byte4 = (test & 0xff000000) >> 24;
}위 코드를 통해서 8208 이라는 INT 형 변수를 BYTE 단위로 뽑아볼 수 있는데,

뽑아 보면 우리가 아까 배웠던
LITTLE_ENDIAN 순서인 { 16, 32, 0, 0 } 로 저장되어 있다.
3. 네트워크를 통해 넘어온 값을 바로 출력할 때는 ENDIAN 변환이 필요 없다.
위에서는 변수에 값을 '할당' 한 뒤에 출력 할려다 보니 LITTLE_ENDIAN 으로 처리했지만,
만약 네트워크를 통해 넘어오는 값을 직접 PRINT 찍어서 확인하려면
ENDIAN 변환이 필요 없다, 일반적으로 네트워크를 통해 전송되는 형식은 BIG_ENDIAN 이기 때문이다.
※ 물론 자체적으로 사용되는 내부망에서 LITTLE_ENDIAN 을 사용하고자 한다면, 상관없다.
CLASS 구조를 토대로한 데이터를 주고받을 때 굳이 BIG_ENDIAN 을 쓴다면
불필요한 배열 REVERSE 과정이 추가되기 때문이다.
어디까지나 변수에 값을 할당할 때 LITTLE_ENDIAN 이 필요 하다는 것을 상기하길 바란다.
'Programming' 카테고리의 다른 글
| COM 개체와 Thread 안정성 (0) | 2023.04.30 |
|---|---|
| 코딩 네이밍 규칙 (0) | 2021.07.22 |