
이전 포스팅을 통해
하지만 몇몇 포스팅들을 참고한 결과 네이티브한 Ubuntu 환경에서 작동함을 확인하였고
직접 Ubuntu 24.04를 설치하여 실제 ROCm을 구동해 보았다.

이번 포스팅에서는 ROCm을 통해
Colab 에서 운용되는
참고로
1. 신경망 벤치.
소스코드는 워낙 풀려있는게 많기에 GPT o1을 통해서 생성해 줬다.
검토해 봐도 큰문제가 없어 보이기에 그대로 사용하였다.
Code.py
import torch
import torch.nn as nn
import torch.optim as optim
import time
def main():
# GPU 사용 가능 여부 확인
if not torch.cuda.is_available():
print("CUDA가 사용 불가능합니다. ROCm이 제대로 설치되었는지 확인해주세요.")
return
device = torch.device("cuda")
print(f"사용 중인 디바이스: {torch.cuda.get_device_name(device)}")
# 대규모 신경망 정의
class LargeNet(nn.Module):
def __init__(self):
super(LargeNet, self).__init__()
self.layers = nn.Sequential(
nn.Linear(10000, 5000),
nn.ReLU(),
nn.Linear(5000, 5000),
nn.ReLU(),
nn.Linear(5000, 5000),
nn.ReLU(),
nn.Linear(5000, 1000),
nn.ReLU(),
nn.Linear(1000, 100)
)
def forward(self, x):
return self.layers(x)
model = LargeNet().to(device)
# 손실 함수 및 옵티마이저 설정
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 무작위 데이터 생성
batch_size = 128
input_size = 10000
output_size = 100
num_batches = 10000 # 총 배치 수
# 데이터 로더 대신 직접 생성
def get_random_batch():
inputs = torch.randn(batch_size, input_size, device=device)
targets = torch.randn(batch_size, output_size, device=device)
return inputs, targets
# 학습 시작
print("대규모 신경망 학습을 시작합니다...")
start_time = time.time()
for batch_idx in range(1, num_batches + 1):
inputs, targets = get_random_batch()
# 순전파
outputs = model(inputs)
loss = criterion(outputs, targets)
# 역전파 및 최적화
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 1000 == 0:
elapsed = time.time() - start_time
print(f"{batch_idx}번째 배치 처리 완료. 누적 시간: {elapsed:.2f}초, 현재 손실: {loss.item():.4f}")
end_time = time.time()
total_time = end_time - start_time
print(f"대규모 신경망 학습 완료. 총 소요 시간: {total_time / 60:.2f}분")
# 최종 손실 출력 (선택 사항)
# print(f"최종 손실: {loss.item()}")
if __name__ == "__main__":
main()신경망 학습을 진행하는데
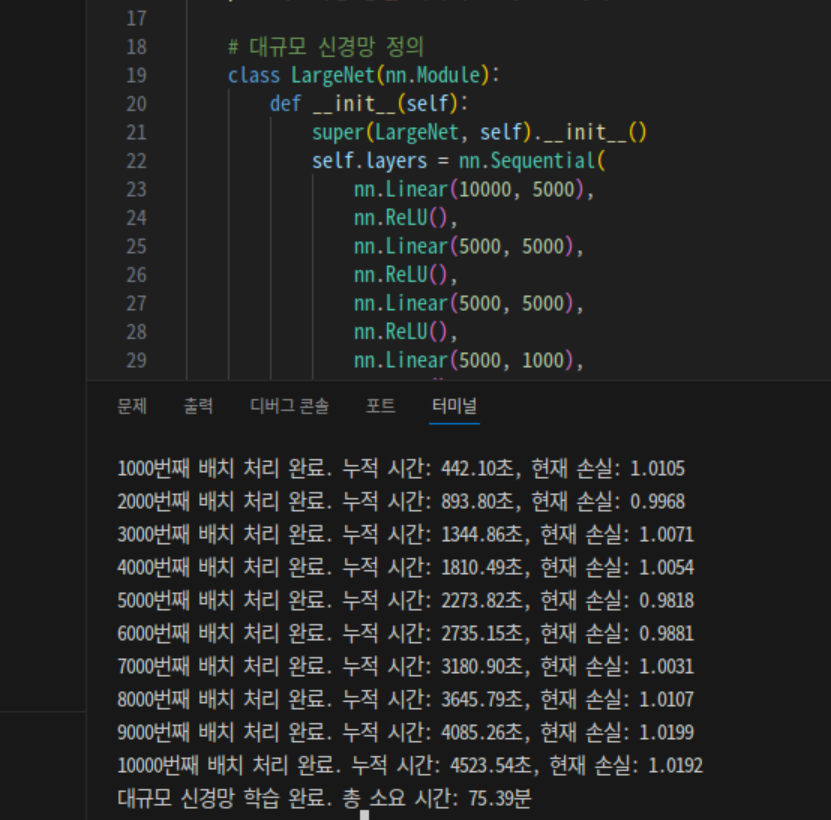
GPU 부하 확인 여부는
약 4.2GB 의 VRAM 을 사용하며, Graphic pipe 부하량 100% 를 보여준다.
편의를 위해 GUI Ubuntu 를 사용하고 있기에, 평시 VRAM 사용량이 2.7GB 남짓이므로,
실질적으로 해당 코드를 구동하는데 사용되는 VRAM은 1.5GB 정도이다.
다음으로 Google Colab 에서
즉
참고로 동일 코드, CPU
무려
2. Whisper large v3
Whisper large v3 에서도 같은 방식으로 테스트를 진행해 보았다.
테스트 데이터는
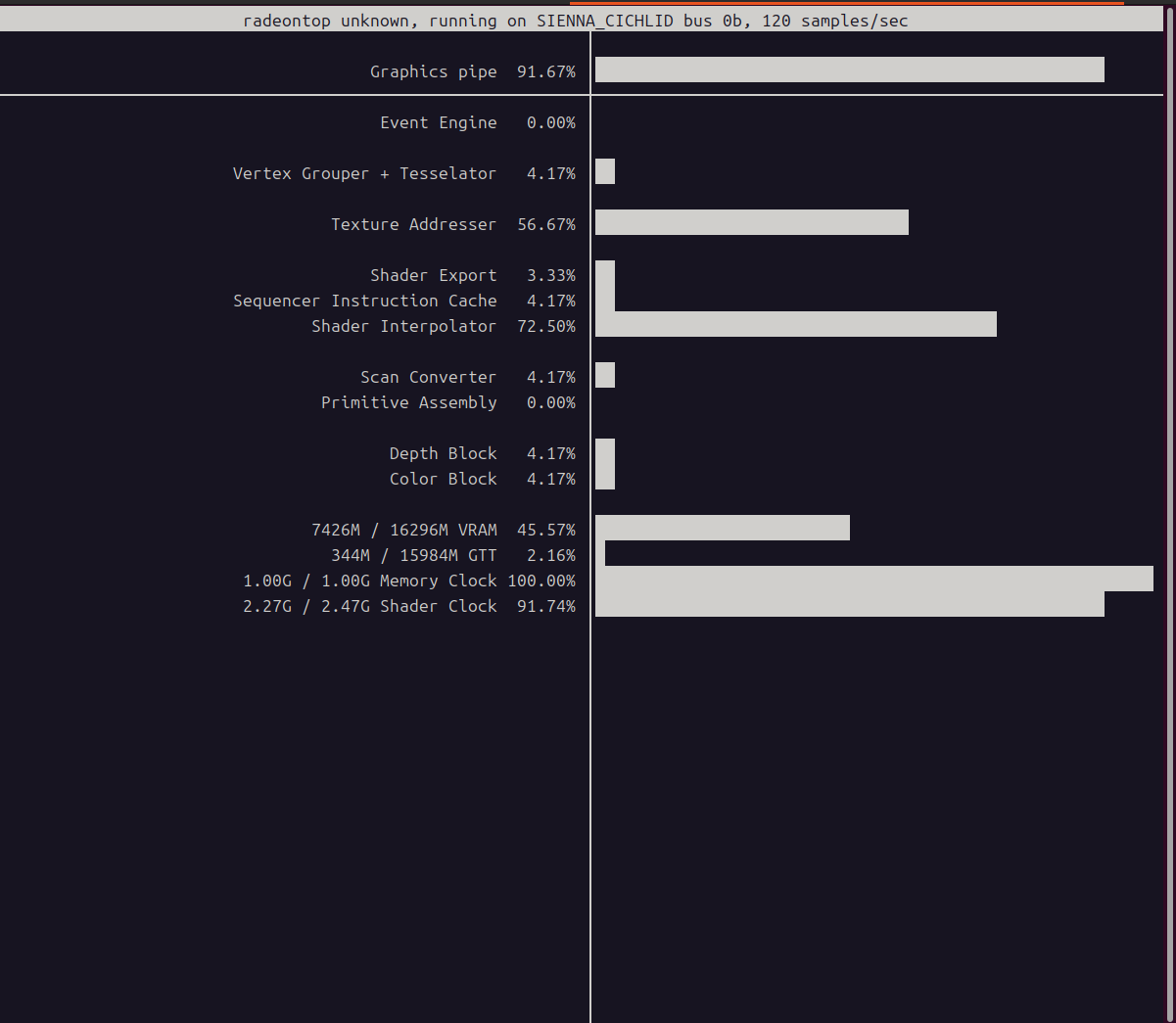
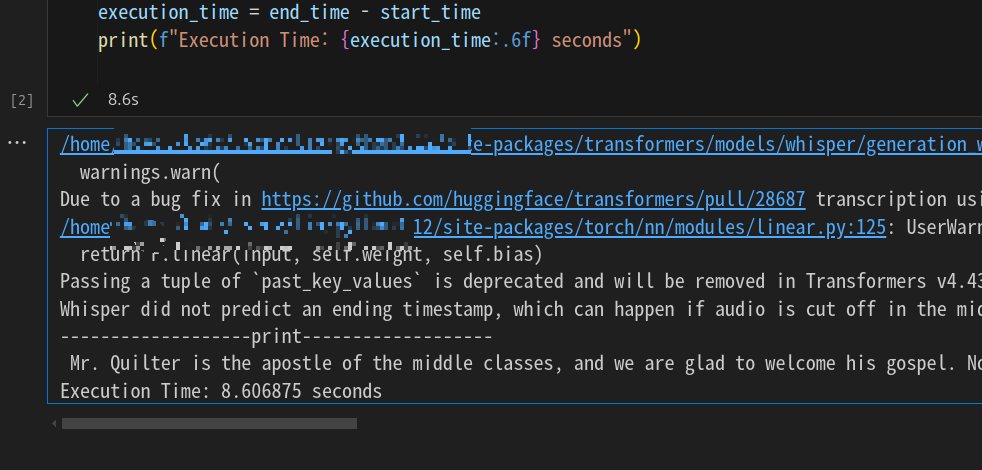
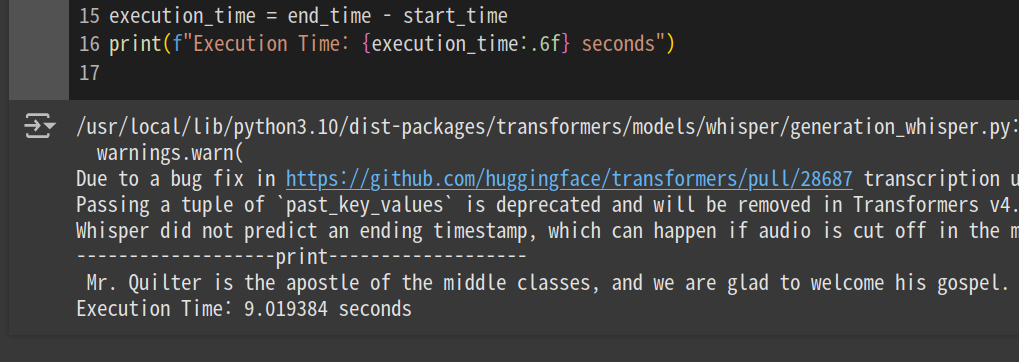
반면
3. Qwen2.5-7B-Instruct
Qwen 2.5 는 llama 와 같은 Open LLM 모델이다.
중국 Alibaba 측에서 개발하였으며,
매 버전 업데이트 마다 동급의 llama 대비 우수하기에 좋아하는 AI 모델이다.
7B를 선택한 이유는, BF16 양자화 수준이 16GB VRAM 으로 구동가능한 한계치이기 때문이다.
아래 코드를 통해
Qwen 2.5 는 한국어를 지원하기에 프롬프트를 직접 한국어로 기입했다.
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
time_start = time.time()
prompt = "우주의 시작은 어떻게 시작되었는지 상세하게 설명 해 줄 수 있니?"
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
time_end = time.time()
print(response)
print(f"{time_end - time_start:.5f} sec")
생성 결과는 아래와 같다.
-RX6800-
우주의 시작, 즉 대폭발(The Big Bang)이 어떻게 일어났는지에 대한 우리의 이해는 여전히 진행 중이며 과학자들은 이 사건을 매우 복잡하고 미묘한 과정으로 설명합니다. 대폭발 이론은 우주의 시작과 그 이후의 발전을 설명하는 가장 잘 입증된 이론입니다. 그러나 이 주제는 아직 완벽히 이해되지 않은 부분이 많습니다.
### 대폭발 이론
1. **시작**: 약 138억 년 전, 우주는 무한히 작은 점(싱글톤)에서 출발했습니다. 이 점은 무한히 밀도가 높았고 온도도 무한히 높았습니다. 이 점에서 모든 시간과 공간이 시작되었습니다.
2. **확장**: 이 점에서 갑작스럽게 폭발하여 확장되기 시작했습니다. 이 확장은 초기에는 매우 빠르게 이루어졌습니다. 초기 몇 초 동안, 우주가 빛보다 빠르게 확장되었다는 개념이 존재하며, 이는 "루비코 경계"라고 불립니다.
3. **냉각과 구조 형성**: 초기의 높은 온도와 밀도는 시간이 지남에 따라 냉각되면서 물질의 구조를 형성하였습니다. 중성자, 프로톤, 엘리트론 등 원소들이 생성되었으며, 이들 원소는 더 나중에 별과 행성, 그리고 우리 같은 생명체를 이루는 원소로 발전할 것입니다.
4. **대칭성 깨짐**: 초기 우주에서는 다양한 대칭성이 있었지만, 시간이 지남에 따라 이러한 대칭성이 깨져서 우리가 경험하는 물리 법칙이 형성되었습니다.
5. **대폭발 이후의 역사**: 대폭발 이후 몇 억 년 동안, 중력으로 인해 물질들이 집합하여 별과 은하계를 형성했습니다. 지구는 약 46억 년 전에 형성되었으며, 생명은 몇 억 년 후에 나타났습니다.
### 현재 연구
- **다크 에너지와 다크 물질**: 현재 우주의 확장
-Tesla T4-
우주의 시작은 대폭발 이론, 즉 우주 대폭발 혹은 빅뱅 이론을 통해 설명됩니다. 이 이론은 현재 가장 널리 받아들여지는 우주의 초기 상태와 진화 과정에 대한 설명입니다. 하지만 이 이론은 매우 복잡하고 미지의 영역이 많습니다. 아래에 주요 내용을 간략히 설명하겠습니다:
1. **대폭발 이론의 기본 개념**:
- 약 138억 년 전, 우주는 초온고밀도의 상태에서 불어나기 시작했다.
- 이 초기 상태에서는 모든 물질과 에너지가 무한히 높은 온도와 밀도를 가진 점으로 존재했다.
2. **초기 상태**:
- 초기 우주는 매우 작은 공간 내에서 무한히 높은 온도와 밀도를 가진 상태였습니다. 이 상태는 '싱크로마시'(Singularity)라고도 부릅니다.
- 이 시점에서 물질과 에너지가 구분되지 않았으며, 시간과 공간 자체가 아직 존재하지 않았습니다.
3. **대폭발의 발생**:
- 어떤 이유로 인해 이 초온고밀도의 상태가 불어나기 시작했을 때, 초당 수십억 킬로미터의 속도로 확장되기 시작했습니다.
- 이 과정은 매우 빠르게 진행되었고, 초기 몇 분 동안에는 핵 합성 과정이 일어나서 중소량의 원소들이 형성되었습니다.
4. **확장 과정**:
- 대폭발 이후, 우주는 계속해서 확장하고 있습니다.
- 이 과정에서 온도가 낮아지고 밀도가 감소하면서 우주가 더 큰 공간으로 확장됩니다.
- 현재까지도 우주는 지속적으로 확장되고 있으며, 이 확장 속도는 가속화되고 있습니다.
5. **현재 이해도**:
- 대폭발 이론은 많은 실험과 관측 결과를 통해 검증되었지만, 여전히 많은 미지의 영역이 남아 있습니다.
- 예를 들어, 대폭발 이론은 우주의 초기 상태를 설명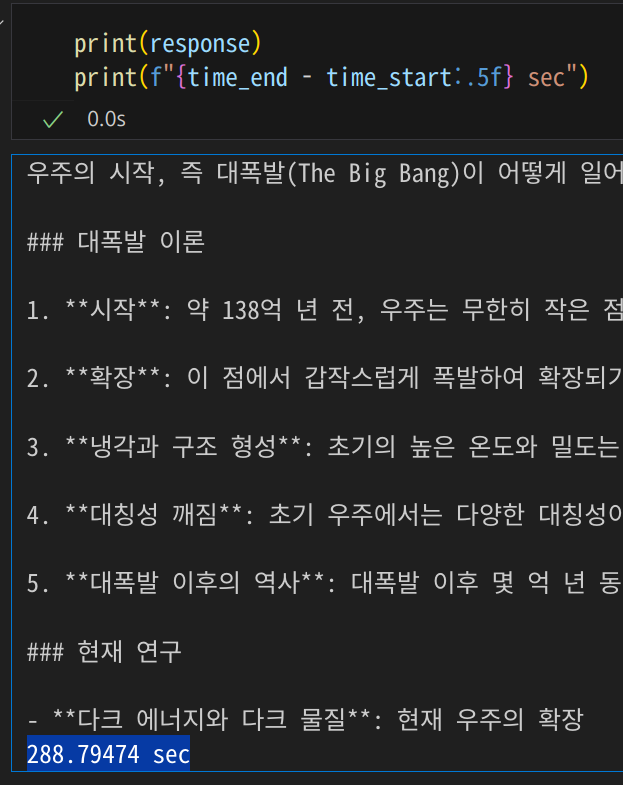

생성된 토큰수는 5% 미만의 차이를 보이며, 같은 Pre-Trained 모델을 기반으로 Inference 하는것이므로
답변 품질을 비교하는것은 무의미하다.
생성 시간 비교에 의미를 두어야 하며
4. 결론.
두가지 간단한 테스트 결과를 보면, ROCm 을 충분히 AI 공부용으로 사용할 수 있다고 생각한다.
다만
만약 반드시 Radeon 을 구입하여야 하는데 AI 역시 염두에 두고 있다면(이럴일이 있나 싶지만.)
공식적으로 지원되는
지원 GPU 들은 WSL2 와 함께 사용할 수 있어서 특히 더 유용하다.
그 외에 RDNA2 이상 버전의 GPU를 가지고 있는 사람들은
'이런 대안도 있구나' 정도로 봐주는편이 좋겠다.
5. Tensorflow 사용시 주의사항.
여담으로 현재
물론 24.04 도 출시된지 1년이 다 되어가니, 조만간 Tensorflow 를 지원하겠지만
2025년 상반기에 ROCm 을 사용할 계획이 있다면, 22.04 버전을 좀 더 권장드린다.
'Artificial Intelligence > Preferences' 카테고리의 다른 글
| docker: Error response from daemon: unknown or invalid runtime name: nvidia. (0) | 2024.01.01 |
|---|---|
| 윈도우에서 Tensorflow GPU 사용 (0) | 2023.03.23 |