1. 서론
StarGANv2-VC 는 기존 StarGANv2 논문 기반하에 제작된 비병렬 음성 데이터의 다대다 Conversion 모델이다. 기존 StarGAN 이 '이미지' 를 대상으로 했다면 해당 논문은 '음성' 에 촛점을 맞춘것이 특징적이다.
만약 고전적인 음성 변환을 수행하려면 같은 Content 를 가진 Source 음성과 Target 음성 두 데이터가 모두 필요하다고 추측할 수 있다. 하지만 이 StarGANv2-VC 모델을 통해 음성을 학습시킨다면, 'Target' 데이터를 학습시킨 신경망을 Base로 Source 음성을 바꿔가면서 변경할 수 있다. 즉 '비병렬' 데이터만 있어도 유의미하게 데이터를 변환할 수 있다.
개인적으로 이 논문을 읽기까지 꽤 많은 배경조사를 진행했는데, 현재 2023년도 기준해서 유의미하게 사용되는 음성 변환모델은 크게 두가지로 AUTO-VC 와 StarGANv2-VC 모델이다. (+ Diff SVC, RVC 등등..)
두 모델 모두 Demo 를 제공하기에 들어보는 것이 좋다.
AutoVC Demo
AutoVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss - Audio Demo Kaizhi Qian*, Yang Zhang*, Shiyu Chang, Xuesong Yang, Mark Hasegawa-Johnson Source Code --> Code Traditional voice conversion Zero-shot voice conversion Code Our code is release
auspicious3000.github.io
StarGANv2-VC
Yinghao Aaron Li, Ali Zare, Nima Mesgarani
starganv2-vc.github.io
왜 AutoVC 가 아닌 StarGANv2-VC 논문을 리뷰 하냐면, AutoVC 측에서는 StarGAN(v1) 만을 대상으로 비교했을때 AutoVC 가 보다 성능이 좋다고 이야기 하고 있고, StarGANv2-VC 측에서는 AutoVC 까지 포함하여 비교 하였을때 본인들의 모델이 더 성능이 좋다고 주장 하였기에, 그점이 영향이 있었다. (추가로 내가 GAN 을 좋아한다.)
2. Abstract, Introduce
We present an unsupervised non-parallel many-to-many voice conversion (VC) method using a generative adversarial network (GAN) called StarGAN v2. Using a combination of adversarial source classifier loss and perceptual loss, our model significantly outperforms previous VC models. Although our model is trained only with 20 English speakers, it generalizes to a variety of voice conversion tasks, such as many-to-many, cross-lingual, and singing conversion.
...
초록서 말하는 내용은 "StarGAN v2 GAN(Generative Adversarial Network)을 사용하여 감독되지 않은 비병렬 다대다 음성 변환(VC) 방법을 제시한다." 이다.
참고로 many-to-many 라고 해서 이미 신경망을 학습 했으면 Source, Target 데이터 모두 사전에 학습되지 않아도 된다는 의미가 아니다. 나도 위 논문에서 "우리 모델 단 20명가지고만 학습시켰는데 뭐 안되는거 없이 다 잘됨 ㅇㅇ" 라고 해서 일단 학습만 시켜 두면 Source, Target 화자가 누군지는 상관이 없을줄 알았지만... 실제론 Source 는 아무거나 가능하지만 Target 데이터는 미리 학습되어 있어야 한다.
초록 이후 Introduce 에서는 이 논문이 왜 필요한지 상세히 설명하고 있다. 특히, 대부분의 Voice Conversion 방식들이 변환을 위해 '병렬(Source, Target 이 동일한 Content 를 지니는 음성)' 데이터를 필요로 한다는 문제점이 존재하다고 언급하고 있다.
더불어 기존 모델들이 Auto-encoder 방식으로 Voice Conversion 문제를 접근하곤 하였는데 이러한 방식들은 화자 의존적 정보를 제거하기 위해 신중하게 설계된 제약이 필요하다고 지적한다. 물론, GAN 방식 또한 문제점이 존재하는데, Discriminator 가 실제 데이터에서 의미 있는 기능을 학습할 수 있다는 보장이 없기 때문에 이러한 GAN을 통한 접근 방식은 변환된 음성과 대상 음성 간의 차이 또는 생성된 음성 왜곡과 같은 문제가 있는 경우가 많이 존재한다고 인정한다.(이 문제점은 AUTO-VC 논문에서도 언급한다)
StarGANv2-VC 는 기존 모델들과는 다르게 화자가 제한된 단일 언어 음성 데이터로만 훈련되었음에도 불구하고 다대다 변환, 언어 간 변환, 노래 변환을 포함한 다양한 음성 변환 작업이 가능하다고 말하고 있으며, 또한 다양한 화법을 가진 말뭉치를 훈련시킨다면 평이한 읽기 음성을 → 감정적인 연기 음성으로 변환하고, 흉성 음성을 → 가성 음성으로 변환하는것이 가능하다고 말하고 있다.
마지막으로 해당 챕터에서는 이 논문에서 도입한 특징들에 대해서 열거한다.
- 새로운 적대 소스 분류기를 도입하여 변환된 음성과 대상 음성 사이의 화자 정체성 측면에서의 유사성
- 자동 음성 인식(ASR) 네트워크
- 기본 주파수(F0) 추출 네트워크
위 세가지 내용은 아래 섹션에서 더 자세히 설명하겠다.
3. Method

- $X_{src}$ - source input
- $X_{ref}$ - reference input (style infomation)
- $\hat{X}$ - converted mel-spectrogram
- $h_{x}$ , $F_{conv}$ , $s$ - letent feature of the source
- $h_{sty}$ - style of the target
3-1. Style Encoder
mel-spectrogram $X_{ref}$가 주어지면 스타일 인코더 $S$는 도메인 $y \in Y$에서 스타일 코드 $h_{sty} = S(X_{ref} , y)$를 추출한다. 매핑 네트워크 $M$과 유사하게 $S$는 먼저 모든 도메인에서 공유 레이어를 통해 입력을 처리한다.
매핑 네트워크($M$)는 임의의 잠재 코드 $z$와 특정 도메인 $y$를 입력으로($M(z,y)$) Style Vector $h_{M}$을 생성한다.
도메인에 대해 다양한 스타일 표현을 제공하기 위한 것으로 사용되며, 이는 Style Vector $s$ 와는 다르다.
이렇게 생성된 스타일 벡터는 Generator 로 전달되어(Figure 1 에 나타나지 않음) 학습하는 데에 사용된다.
※ $s$는 단순 $X_{ref}$ 의 style 을 담은 vector 이다.
3-2. Discriminators
위 이미지를 살펴보면 고전적인 GAN 에서 보이는 단일 구성의 Discriminator 와는 다르게 두개의 Classifier 를 지닌 DIscriminators 를 가지고 있다.
- Real/Fake Classifier - 생성된 샘플이 '진짜' 인지 '가짜' 인지 판별하는 판별기로서, 생성기가 생성한 샘플과 실제 데이터 샘플간의 차이를 학습한다.
- Source Classifier - 추가로 도입된 판별기로 변환된 샘플의 'Source Domain' 을 학습한다. 해당 분류기는 변환 후에도 입력 도메인을 벗어나는 특징을 학습함으로써, 원래 도메인에 특징적이면서도 도메인에 불변인 특징에 대한 피드백을 제공할 수 있다.
3-3. Training Objectives
StarGANv2-VC 의 최종적인 목표는 도메인 $y_{src} \in Y$에서 샘플 $X \in X_{ysrc}$ 를 병렬적인 데이터 없이 대상 도메인 $y_{trg} \in Y$ 에 존재하는 샘플 $\hat{X} \in X_{ytrg}$ 로 변환하는 mapping $G:X_{ysrc} \rightarrow X_{ytrg}$ 를 학습하는 것이다
보다 쉽게 설명하면 아래와 같다. (도메인 = 스타일로 봐도 무방하다)
- $y_{src} \in Y$ - $Y$(가능한 모든 도메인 집합) 에 포함된 $y_{src}$(소스 도메인중 원소)
- $X \in X_{ysrc}$ - $X_{ysrc}$(소스 도메인에서의 샘플 집합) 에 포함된 $X$(샘플 집합)
- $y_{trg} \in Y$ - $Y$(가능한 모든 도메인 집합) 에 포함된 $y_{trg}$(타겟의 도메인이며, 변환하려는 목표 도메인)
- $\hat{X} \in X_{ytrg}$ - $X_{ytrg}$(타겟 도메인에서의 샘플 집합) 에 포함된 $\hat{X}$(타겟 도메인에서 변환된 샘플)
이하 아래는 훈련 방법을 나타낸다. mel-spectrogram $X \in X_{ysrc}$, 소스 도메인 $y_{src} \in Y$, 대상 도메인 $y_{trg} \in Y$ 가 주어지면 아래와 같은 손실 함수로 모델을 훈련한다.
3-3-1. Adversarial loss
생성기는 mel-spectrogram $X$와 style vector $s$를 사용하여 적대적 손실을 통해 새로운 mel-spectrogram $G(X,s)$를 생성하는 방법을 학습한다.
$$\begin{flalign}
L_{adv} = &\mathbb{E}_{X}, y_{src} [logD(X,y_{src})] + \\
&\mathbb{E}_{X}, y_{src}, s[log(1-D(G(X,s),y_{trg}))] \\
\end{flalign}$$
여기서 $\mathbb{E}_{X}$는 입력 mel-spectrogram $X$에 대한 기대값을 나타내며, 모든 가능한 $X$ 값에 대해 평가되는 손실 함수의 평균을 의미한다. 그를 토대로 $\mathbb{E}_X, y_{src}$ 는 모든 가능한 입력과, 소스 도메인에 대한 평균 효과를 계산한다는 점을 알 수 있다.
$D(\cdot, y)$는 도메인 $y \in Y$에 대한 Real/Fake 판별기를 나타낸다. 따라서 $L_{adv} = \mathbb{E}_{X}, y_{src} [logD(X,y_{src})]$ 부분은 판별기 $D$가실제 샘플을 얼마나 잘 식별하는지 평가하고, $\mathbb{E}_{X}, y_{src}, s[log(1-D(G(X,s),y_{trg}))]$ 부분은 생성기 $G$에 의해 생성된 샘플을 얼마나 잘 식별하는지 평가한다. 두 평가값을 더해서 최종적인 Adversarial loss 의 값을 계산한다.
3-3-2. Adversarial source classifier loss
$$L_{\text{advcls}} = \mathbb{E}_{X} ,y_{\text{trg}},s \left[ \text{CE}\left(C\left(G(X, s)\right), y_{\text{trg}}\right) \right]$$
- $y_{trg}$ - 타겟의 도메인을 나타낸다.
- $G_(X, s)$ - 생성기 G에 의해 생성된 새로운 mel-spectrogram 을 나타낸다.
- $C$ - source classifier
- $CE$ - Cross-entropy loss function
$C$는 source 도메인의 특성을 보존하면서도 타겟 도메인과 더 유사한 샘플을 생성하도록 돕는 역할을 한다. 이는 생성기가 source 도메인의 특성을 보존하면서도 타겟 도메인과 더 유사한 샘플을 생성하도록 돕는다.
"classifier C with the same architecture as D that learns the original domain of converted samples. By learning what features elude the input domain even after conversion, the classifier can provide feedback about features invariant to the generator yet characteristic to the original domain, upon which the generator should improve to generate a more similar sample in the target domain. A more detailed illustration is given in Figure 2." (Page 2)
3-3-3. Style reconstruction loss
$$L_{\text{sty}} = \mathbb{E}_{X},y_{trg},s \left[ \left\| s - S(G(X, s), y_{\text{trg}}) \right\|_1 \right]$$
- $s$ - style vector
- $S$ - style encoder
- $|| \cdot ||_1$ - Calculate the difference between two vectors (absolute value)
Style reconstruction loss 는 생성된 샘플(target)에서 추출한 스타일이 source 의 스타일과 얼마나 일치하는지 평가한다.
3-3-4. Style diversification loss
$$\begin{flalign}
L_{\text{ds}} &= \mathbb{E}_{X},s_1,s_2,y_{\text{trg}} \left[ \left\| G(X, s_1) - G(X, s_2) \right\|_1 \right. \\
&\quad + \left. \left\| F_{\text{conv}}(G(X, s_1)) - F_{\text{conv}}(G(X, s_2)) \right\|_1 \right]
\end{flalign}$$
diversification 이라는 이름에서도 알 수 있듯 해당 손실은 생성된 샘플간의 평균 절대 오차(MAE)를 최대화 한다. 이는 생성기가 다른 스타일 코드를 사용할 때 서로 다른 스타일의 샘플을 생성하도록 유도한다. 또한 F0 특성 간의 차이역시 최대화 하여, 생성된 음성이 다양한 피치를 갖도록 한다.
- $G(X, s)$ - 생성기 $G$에 의해 생성된 샘플
- $s_1, s_2$ - 는 $\in S_{ytrg}$ 로서 도메인 $y_{trg} \in Y$ 에서 무작위로 샘플링된 두 개의 스타일 코드
- $F_{conv}$ - F0 특성을 추출하는 네트워크의 합성곱 계층의 출력
3-3-5. F0 consistency loss
$$L_{f0} = \mathbb{E}_{X}, s \left[\left\| \hat{F}(X) - \hat{F}(G(X, s)) \right\|_1 \right]$$
- $\hat{F}(X)$ - mel-spectrogram $X$의 정규화된 F0 값을 나타냄.
- $G(X,s)$ - 스타일 코드 s와 함께 생성기를 통해 생성된 샘플
F0 consistencty loss 는 생성된 음성이 원래 음성과 동일한 기본 주파수(F0)를 가지도록 한다. 수식을 보면 알 수 있듯, source F0 에서 Generator 를 통해 생성된 F0 의 차이($L_{f0}$) 를 계산한다.
3-3-6. Speech consistency loss
$$L_{\text{asr}} = \mathbb{E}_{X}, s \left[\left\| h_{\text{asr}}(X) - h_{\text{asr}}(G(X, s)) \right\|_1 \right]$$
- $h_{asr}$ - 음성에서 언어 특성을 추출하는 함수.
Speech consistency loss 는 변환된 음성이 soure 와 동일한 언어 content 를 갖도록 하기 위해서 사용된다 $h_{asr}$ 은 이러한 기능을 달성하기 위한 핵심 기능으로서 pre-tained joint CTC-attention VGG-BLSTM network 를 사용하여 음성의 특성을 추출한다. 수식을 보면 F0 consistency loss 와 마찬가지로 source 음성 특성 에서 Generator 를 통해 생성된 음성의 특성의 차이($h_{asr}$) 를 계산한다.
3-3-7. Norm consistency loss
$$L_{\text{norm}} = \mathbb{E}_{X},s \left[ \frac{1}{T} \sum_{t=1}^{T} \left| \left\| X_{\cdot,t} \right\| - \left\| G(X, s)_{\cdot,t} \right\| \right| \right]$$
- $T$ - 시간 차원의 mel-spectrogram 길이.
Norm consistency loss 는 생성된 샘플의 음성, 침묵 간격을 보존하기 위해서 사용된다.
이 손실 함수는 원본 음성과 생성된 음성의 각 시간 단계에서mel-spectrogram의 벡터의 크기를 절대값을 통해 비교한 뒤, 이를 모든 시간 단계에 대해 평균을 계산(${1 \over T}$) 하여 음성과 침묵 간격이 원본 음성과 일치하도록 한다.
이를 통해 원본 음성과 생성된 음성의 음성 - 침묵시간이 동기화 되므로 보다 자연스럽게 음성변환이 된다.
3-3-8. Cycle consistency loss
$$L_{\text{cyc}} = \mathbb{E}_{X},y_{\text{src}},y_{\text{trg}},s \left[ \left\| X - G(G(X, s), \tilde{s}) \right\|_1 \right]$$
- $\tilde{s}$ - 입력 소스 도메인($y_{src} \in Y$) 의 추정 스타일 코드.
Cycle consistency Loss 의 목적은 source 샘플을 target 도메인으로 변환한 후, 다시 source 도메인으로 변환했을 때 최종적인 결과가 원본 샘플과 일치하도록 하는것이다. 이를 통해 원본 샘플의 중요한 특성을 보존 하면서도 타겟 도메인의 스타일로 변환할 수 있다.
3-3-9. Full Objective
$$\begin{align}
\min_{G,S,M} &L_{\text{adv}} + \lambda_{\text{advcls}} L_{\text{advcls}} + \lambda_{\text{sty}} L_{\text{sty}} \\
&- \lambda_{\text{ds}} L_{\text{ds}} + \lambda_{f0} L_{f0} + \lambda_{\text{asr}} L_{\text{asr}} \\
&+ \lambda_{\text{norm}} L_{\text{norm}} + \lambda_{\text{cyc}} L_{\text{cyc}}
\end{align}$$
- $\lambda$ - 각 용어에 대한 hyper parameter를 의미.(해당 손실이 최종적으로 얼마나 영향을 미칠지 조절)
- $L_{adv}$ - Adversarial loss, 생성된 샘플이 실제 샘플과 얼마나 유사한가.
- $L_{advcls}$ - Adversarial source classifier loss, 생성된 샘플이 원래 도메인의 특성을 잘 보존하는지.
- $L_{sty}$ - Style reconstruction loss, 생성된 샘플이 원본 샘플의 스타일을 얼마나 잘 재현하는가.
- $L_{ds}$ - Style diversification loss, 다른 스타일 코드로 생성된 샘플간의 차이를 최대화.
- $L_{f0}$ - F0 consistency loss, 생성된 음성이 원래 음성과 동일한 기본 주파수를 가지도록 함.
- $L_{asr}$ - Speech consistency loss, 생성된 음성이 원래 음성과 동일한 언어 특성을 가지도록 함.
- $L_{norm}$ - Norm consistency loss, 생성된 음성의 특성 벡터가 일정하도록 함.
- $L_{cyc}$ - Cycle consistency loss, source 샘플을 도메인으로 변환한 후, 다시 source 로 변환했을때 결과가 일치하도록 함.
Full Objective 는 논문 전체에 대한 수식을 나타낸다. 이는 수식에서 유추할 수 있듯, 생성기($G$), 스타일 인코더($S$), 매핑 네트워크($M$) 등 StarGANv2-VC 모델 전반에 걸쳐 얼마나 목적함수에 영향을 미치게 할 것인지 조절한다.
4. Experiments
해당 챕터에서는 어떻게 해당 모델 훈련하고, 평가하였는지 전반적인 실험 조건과 결과에 대해서 이야기 한다.
공정한 비교를 위해 VCTK 데이터 세트에서 보고된 동일한 20명의 선택된 화자의 데이터를 통해 기본 모델을 학습시키며, 추가로 '가성' 발성을 JVS 데이터세트틀 통해 학습하고, '감정' 에 따른 발성 역시 추가 ESD 데이터 세트를 통해 학습한다. 모든 데이터 세트는 24khz(24000hz)로 재 샘플링 되고, 훈련,검증,테스트 비율은 80%/10%/10% 비율이다.
외에 추가적인 학습 조건은 아래와 같다.
- Data Time Length - 2sec
- Learning Epochs - 150
- Optimizer - AdamW
- Learning Rate - 0.0001
Full Objective(Hyper Parameter) 에 해당하는 각각의 변수 값은 다음과 같다.
- $\lambda_{cls}$ - 0.1
- $\lambda_{advcls}$ - 0.5
- $\lambda_{sty}$ - 1
- $\lambda_{ds}$ - 1
- $\lambda_{f0}$ - 5
- $\lambda_{asr}$ - 1
- $\lambda_{norm}$ - 1
- $\lambda_{cyc}$ - 1
더하여 사전에 학습된 F0 모델은 100 epochs 동안 학습되었으며, ASR 모델은 80 epoch 동안 훈련되었다. (관련 내용을 더 자세히 알고 싶다면 논문 본문과 Github 를 참조하면 좋다)
4-1. Evaluations
더불어 평가 방법에 대해서 설명한다.
참고로 이러한 '생성형' 모델의 경우, subjective(주관적), objective(객관적) 평가방법이 존재하는데, 사실 저 '객관적' 인 평가 방법이라고 해도... 음... 검증 방법을 보면 썩 신뢰가 안갈달까. 이 objective 방법의 경우는 ASV(automatic speaker verification) 라는 방식을 사용하는데, 쉽게 설명하면 ASV는 화자의 음성이 A라는 사람의 음성이 맞는지 확인하는 기술이다.
그런데 저런 기술이 Bixby 나 Siri, Google Assistant 등에 모두 적용 되어 있을텐데 친구가 호출했을때 오작동하는 경험을 다들 해 보았을 것이다. 때문에 ASV가 어떻게 작동하는지 상세히 살펴보진 않았지만 저 ASV 라는 기술로 생성한 음성의 정확도를 평가한다는게 나로서는 좀... 신뢰가 안가서 사실 마음 한켠으로는 subjective 한 평가 방식에 좀 더 가중치를 두는 편이다. subjective 방식은 실제 설문조사를 통해 변환된 목소리가 얼마나 비슷한지 사람들에게 평가를 요청하여 점수를 매긴다.(물론 여기서 논문 저자가 양심적으로 조사 대상을 선정해야 한다는 문제가 있지만...)
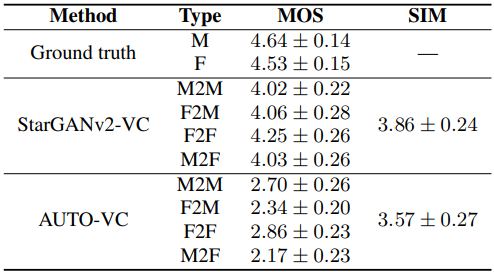
subjective 한 방법의 평가 측도로서 MOS(Mean Opinion Score) 가 있다. 일반적으로 1-5까지로 평가하며, 1은 가장 낮은 품질, 5가 가장 높은 품질이다. 일종의 '설문조사' 를 통해서 점수를 결정짓는다.
SIM(Similarity) 은 생성된 음성 샘플이 원래 음성 샘플과 얼마나 유사한지 나타내는 척도이다. (논문 내부에서는 구체적으로 어떻게 계산하는지 설명이 없음)
논문에서는 이러한 subjective 한 평가를 위해서 영어권 사용자 46명에게 평가를 받았다고 한다. 1은 완전히 왜곡된 형태이며, 5는 완전히 자연스러운 상태. 그리고 올바른 평가를 수행하기 위해 임의적으로 인간이 이해가 불가능한 6개의 오디오를 첨부하여, 이 중 2개 이상이 2점 이상으로 평가 되었을 경우, 성실하게 조사에 응답하지 않았다고 보고 조사 대상에서 아예 배제하였다고 한다.
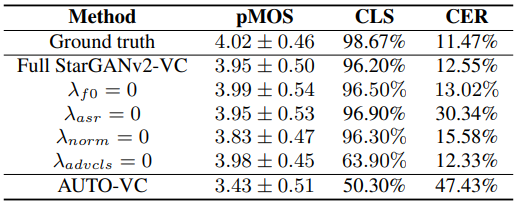
objective 한 방법의 경우 pMOS(Predicted Mean Opinion Score), CLS(Classification Accuracy) 와 더불어 ASV(Automatic Speaker Verification)를 통해 CER(character error rate)을 계산한다.
- pMOS - MOS의 예측된 값으로 알고리즘, 모델에 의해 계산되므로 객관적 지표로 평가됨.
- CLS - 스피커 인식 모델의 정확도를 나타냄.(통계적인 방법)
- CER - 음성 인식 모델의 문자 오류율을 나타내며 ASV를 통해 계산한다.
해당 논문에서는 이런 방법들을 통해 정확도가 AUTO-VC 보다 높다고 주장한다.
5. Conclusion
논문에서는 Tesla P100 GPU 를 통해서 테스트 하였고, Github 저장소에서는 아마 10GB 의 VRAM 이 필요할 것이라고 했지만 8GB 의 VRAM 을 가진 RTX3070 으로 약 2일간 모델을 학습시켜 보니 잘 작동 하였다. (아마 찾아보면 이미 학습된 모델이 있을텐데, 난 그냥 재미로 돌려봤다.)
몇가지 테스트 음성을 만들어 보았는데, 이미 모델에서 학습된 음성으로 변환하는건 매우 잘 되었지만, 위에서 언급했듯이 학습되지 않은 화자의 음성으로 변환 하는 데에는 정확도가 매우 떨어졌다.
해당 ASR은 '영어' 를 기준으로 학습 되었지만, 논문 내부에서는 일본어와 같은 다른 언어에서도 어느정도 유의미한 결과를 보인다고 하였기에, 나는 한국어로 몇몇 테스트를 거쳐 변환을 해 보았고, 실제로 완전히 자연스럽진 않지만 subjective 방법으로 약 3.5점 정도를 줄만 하였다. 만약 한국어로 StarGANv2-VC를 완벽히 적용하려면 한국어로 학습된 ASR 모델이 필요할 것이라고 저자는 이야기한다.
내가 직접 영어로 말한 음성을 학습된 다른 화자로 변경 하였을때는 subjective 4.5점 정도를 줄만큼 매우 자연스러웠다. 개인적으론 보이스피싱 등 불순한 의도로 활용이 충분히 가능할 정도로 정교하기에 꽤 위험한 기술이라고 느꼇다.
아래는 간단하게 내가 직접 녹음한 Source 음성을 Target 음성으로 Convert 해 보았다. StarGANv2-VC의 성능을 직접적으로 체감할 수 있을것이다.
Source Voice
Target Voice
Converted Voice
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] GAN(Generative Adversarial Networks) (0) | 2023.11.23 |
|---|---|
| [리뷰] wav2vec 2.0 (0) | 2023.08.21 |
| [리뷰] Style-Based GAN (0) | 2023.07.09 |
| [리뷰] PGGAN(Progressive Growing of GANs) (0) | 2023.06.24 |
| [리뷰] Attention Is All You Need (0) | 2023.05.12 |