
1. 서론
wav2vec 2.0 은 2020년 Facebook AI 에서 발표한 논문으로서 음성변환 / TTS / ASR 분야에서 라벨링된 데이터가 많이 존재하지 않을 경우에도 성능을 극적으로 끌어올릴 수 있는 기술(wav2vec 2.0) 을 제안하는 논문이다.
이전 StarGANv2-VC 논문 리뷰에서도 살펴볼 수 있듯, 이러한 음성 변환/생성 기술에는 기본적으로 라벨링된 데이터를 통해 데이터를 학습하는 과정이 필요하다. StarGANv2-VC 에서는 ASR모델을 통해 간접적으로 음성변환 모델을 학습 하는데 사용한다. 실제로 StarGANv2-VC 논문에 사용되는 ASR 모델을 학습하는 코드를 보면, 관련되어 이미 Transcript 된 파일을 하나 확인할 수 있다. 코드를 훑어보니 이 ASR 학습 모델은 LJSpeech-1.1 데이터셋을 사용하고 있으며, wav2vec 이 적용되지 않은듯 보였다.(이는 StarGANv2-VC 가 STT 모델이 아닌, Voice Conversion 모델인 점도 영향이 있다, 아무래도 STT 보다는 Conversion 이 Label 정보를 더 적게 요구하는것이 사실.)

LJSpeech-1.1 데이터 셋의 경우 평균적인 녹음시간이 약 6.57sec 이므로, 해당 ASR 모델을 녹음하는데만 약 8.52시간의 라벨링된 데이터가 필요한것을 알 수 있다.
영어는 전 세계에서 가장 많이 사용하는(약 15억명) 언어이므로 음성 데이터 - 라벨링 데이터의 병렬 데이터를 찾는게 그다지 어렵지 않다. 한국어 역시 사용하는 인구가 최소 5천만이 넘으므로, 데이터를 구하려 하면 조금의 수고를 통해 구할 수 있지만, 인구가 더 적은 나라들의 라벨링 데이터는 구하기가 어렵다. 인구가 2천만 이하인 나라가 135개국이나 된다. 물론 그 나라가 제각각 다른 언어를 사용하는것은 아니지만 어쨋든 기본적으로 언어 모델을 학습하는데 있어 잘 라벨링된 데이터가 있는 언어는 많지 않다. 이것은 곧 그 언어의 음성을 인공지능 학습함에 있어 치명적인 어려움이 있다는 의미이다.
극단적으로 소수민족들의 언어는 데이터 수집 문제로 인해 TTS / ASR 을 제작하는건 불가능할 지경이며, 데이터가 없다 보니 인공적인 번역기를 만드는것 역시 불가능하다. 근본적인 원인은 '대량의 라벨링된 데이터' 가 필요하다는 것이다. 이 문제점을 해결한다면 제아무리 마이너한 언어라도 충분히 학습시킬 수 있을 것이다.
wav2vec 2.0 의 발상은 여기서 시작됐다.
2. 모델
전체적인 과정을 통해 보면 CNN 을 통해
여기서 추측해 보건데 나는 wav2vec(1.0) 의 논문을 살펴보진 않았지만. wav2vec 은 원시 오디오 데이터를 → 양자화 → Self-Attention(Transformer) 하는 순차적인 변환을 통해 문맥화된 표현을 학습하는 방식으로 설계된 것으로 추측한다. 반대로 wav2vec(2.0) 은 양자화와 문맥화된 표현을 순차적으로 학습하는것이 아닌 '동시에' 학습하는것이 차이점으로, 원시 오디오 데이터에서 → 양자화 및 문맥화된 표현을 동시에 학습 하는것이 차이점인 것이다.
여기서 '동시' 에 학습하는것과 '순차적' 으로 학습하는것의 차이가 애매하게 느껴질 수 있을 듯 싶다. 순차적인 방법은 양자화를 통해 이산적인 데이터로 변경하고, 이 변환된 데이터를 사용하여 Transformer 모델을 학습하는 방식으로 이뤄진다. 반면 동시에 학습하는 방법은 양자화와 Transformer 학습이 동시에 이뤄지며, 이는 논문 내에서 언급하듯 end-to-end 방식으로서 전체 시스템이 하나의 목적 함수를 최적화 하도록 설계 되었다는 차이점이 있다.
결론적으로 wav2vec 2.0 모델은 multi-layer convolution Encoder :
이하 논문에서는 총 3가지 소분류 챕터로 특징들을 설명하고 있다.
1) Feature encoder
인코더는 계층 정규화 및 GELU 활성화 함수에 이어 temporal convolution 을 포함하는 여러 블록으로 구성된다. 인코더에 입력되는 원시 파형은 0 평균 및 단위 분산(unit variance)으로 정규화한다. 인코더의 총 stride는 트랜스포머에 입력되는 시간 단계 T의 갯수를 결정한다.
2) Contextualized representations with Transformers
feature encoder 의 출력은 Transformer 네트워크에 공급된다. 절대 위치 정보를 공급하는 고정 위치 임베딩 대신 상대적 위치 임베딩을 역할을 하는 것과 유사한 컨볼루션 레이어를 사용한다. 입력에 GELU가 뒤따르는 회선의 출력을 추가한 뒤에 layer normalization 을 수행한다.
참고로 여기서 Transformer 부분에서 '고정적인 위치 임베딩(fixed positional embeddings)' 대신 '상대적인 위치 임베딩(relative positional embedding)' 을 추가한다고 한다. 기존 Transformer 모델은 대부분 '고정적인 위치 임베딩' 을 사용함에 따라 유연성이 떨어졌다 이는 이전 포스팅 에서도 확인할 수 있는데 Positional Encoding 이 바로 그것이다. wav2vec 2.0 에서는 이러한 Transformer 모델의 '고정적인' positional embeddings(positional encoding 과 동일한 의미) 을 '상대적인' reletive positional embedding 으로 교체함으로서 보다 모델의 유연성을 강화했다.
이러한 차이점으로 인해 기대되는 효과로 기존에는 모델이 겪어보지 못한 문맥을 파악할 경우 비슷하거나 거의 동일한 문장 / 음성을 전혀 다르게 파악할 수 있는 문제를 해결할 수 있다. 예로 '노인' 의 경우 일반인보다 음성을 발화하는 속도가 늦고, 어눌한 경우가 있는데 이러한 상대적인 임베딩을 사용할 경우 같은 문장을 말하는 노인, 일반인의 음성 데이터가 근본적으로 같다는 사실을 기존 고정 위치 임베딩으로 학습한 것보다 더 명확히 파악할 수 있다.
추가로 특정 패턴에 집착하여 성급한 일반화를 진행하는 빈도가 고정 위치 임베딩보다 더 낮을 것으로 추측된다.
3) Quantization module
self-supervised training 를 위해서 feature encoder
이게 뭔 개소릴까?
하나하나 용어를 정리해 보자.
- self-supervised - 라벨링되지 않은 데이터들을 스스로 분류해 학습하는 인공지능 모델의 종류
- feature encoder - 원시 오디오를 입력받아 그 데이터의 특징을 추출한다. (여기서는 multi-layer cnn, 활성화함수, 계층 정규화 등을 통해 오디오의 특징을 추출하는 과정을 뜻함. (이렇게 추출된게 Transformer로..))
- codebook - 일종의 분류가능한 패턴중 '양자화' 된것, 음성의 주파수가 제각각이여 그 조합이 무한해 보이지만 나누다 보면 특정 이상의 분류는 무의미해 진다. 이 조합식이 든 묶음을 'codebook' 이라고 지칭한다. (1, 2)
- linear transformation - 개요적인 부분은 링크를 참조하길 바라며, 여기서는 선형 변환을 통해 특징 벡터를 가장 가까운 코드북 항목으로 양자화 하는 것으로 추측된다. (내용 포함 안되어있음)
추가로 gumbel softmax 라는 수식을 설명한다.
gumbel softmax 를 사용하여 양자화 모듈에서 codebook 항목을 선택하는 것을 완전히 미분 가능하게 만든다. 즉, 이를 통해 모델은 codebook 항목을 선택하는 확률분포를 학습할 수 있다. 원시 음성 데이터를 encoder 에 제공한뒤 출력된
추가로 forward pass 동안에
3. 학습
해당 모델은 pre training 단계에서 BERT 처럼 마스킹을 도입하였다. 해당 마스킹은 latent feature encoder 에서 일정 비율의 시간 단계를 마스킹한다. 학습 목표는 각 마스킹된 시간 단계에 대해 선택 항목 세트에서 올바르게 양자화된 잠재적 오디오 표현을 식별해야 하며 최종 모델은 라벨링된 데이터에서 미세 조정(fine-tuned)된다.
3-1. Masking
인코더의 출력된 잠재 음성 표현(latent speech representations)을 마스크 하기 위해서 모든 시간 단계(time steps) 중에서 시작 인덱스로 사용될 시간 단계를 무작위로 선택한다. 이때 선택된 시작 인덱스로부터 연속적인
여기서 '마스크' 라는게 포토샵 등을 다뤄보지 않았다면 와닿지 않을 수도 있을 법 한데, 일반적으로 데이터의 특정 부분을 가리거나, 숨기는 행위를 의미한다. 특정 데이터 부분을 의도적으로 가려서 그 부분을 '보지 못하게' 하는 것이다. wav2vec 모델에서는 오디오의 특정 시간구간을 마스크하여 그 부분의 특성을 모델이 예측하도록 한다. 이를 통해 모델은 주변 정보나 문맥을 통해 누락된 부분을 추론하려고 시도한다. 이러한 마스킹은 모델이 근본적으로 데이터에 대해 더 깊은 이해를 할 수 있도록 도와준다.
3-2. Objective
결국 wav2vec 2.0의 목표는 pre training 동안 음성 오디오의 표현을 학습하는 것으로, 이는 대조작업
이러한 대조작업의 핵심적인 개념은 양성(positive) 샘플과 음성(negative) 샘플 사이를 극대화하는 방식으로 특징을 학습한다. 양성샘플은 유사하거나 관련이 있다고 간주되는 데이터 쌍을 나타내며, 음성샘플은 유사하지 않거나, 관련이 없다고 간주되는 데이터 쌍을 나타낸다.
이러한 대조작업을 통해 대조적인 손실값을 구하는데, 이를 통해 모델이 codebook 항목을 자주 사용하도록 장려한다.
외에도 논문에서는 Contrastive Loss 와 Diversity Loss 에 관해서 설명하고 있다.
- Contrastive Loss - 대조적 손실로 번역하며, 대조작업에서 주로 사용되는 손실 함수이다. 위에서 설명한 바와 같이 양성 샘플(관련있는 샘플) 간의 거리를 줄이고, 음성 샘플(관련 없는 샘플)간의 거리를 늘려 유사한 샘플을 잘 구분하게 하는 손실 함수이다.
- Diversity Loss - 다양성 손실로 번역하며, 모델이 특정 패턴에 의존하지 않도록 다양한 패턴을 학습하게끔 유도하는 손실 함수이다. wav2vec 2.0 에서는 codebook 항목들이 균등하게 고려할 수 있게 유도하는 용도로 해당 손실을 사용한다.
추가로 논문에서는 수식에 관해 기재하였으나, 여기서는 추가하지 않겠다. (중요도가 떨어지는것은 아니나 개인적으로 이해가 부족하며, 해당 모델을 사용하는데 개인적으로 여기까지 이해할 필요가 없다고 판단해서이다.)
3-3. Fine-tuning
논문서 self-supervised training 을 통해 모델을 pre training 한 후, 레이블이 있는 데이터를 사용해 모델을 Fine-tuning 한다. 이로 인해 사전 학습된 모델의 표현력을 활용할 수 있기에, 레이블이 있는 작은 데이터셋에서도 높은 성능을 달성할 수 있다.
보다 상세히 설명하면 pre training 모델은 어휘 개수를 나타내는
4. 결론
wav2vec 2.0 의 학습단계는 두 단계로 이뤄지는데, pre training 단계와, fine tuning 단계가 바로 그것이다.
- pre training - 라벨링되지 않은 대량의 음성 데이터로 모델을 학습하여, 원시 음성 데이터의 패턴을 학습한다. 이렇게 학습된 모델은 원시 음성 데이터의 구조와 패턴에 관한 정보를 이해하게 된다. (Feature Extraction, Contextual Representation, Quantization, Contrastive Loss, Diversity Loss 가 pre training 단계에서 이뤄짐.)
- fine tuning - 사전 학습된 모델을 라벨링된 데이터(표에서 보여지듯, 10min / 1hour / 10hour / 100hour ...)를 사용하여 특정 작업에 대해서 미세 조정한다. (모델 Transformer 상단(다음)에서 이뤄짐)
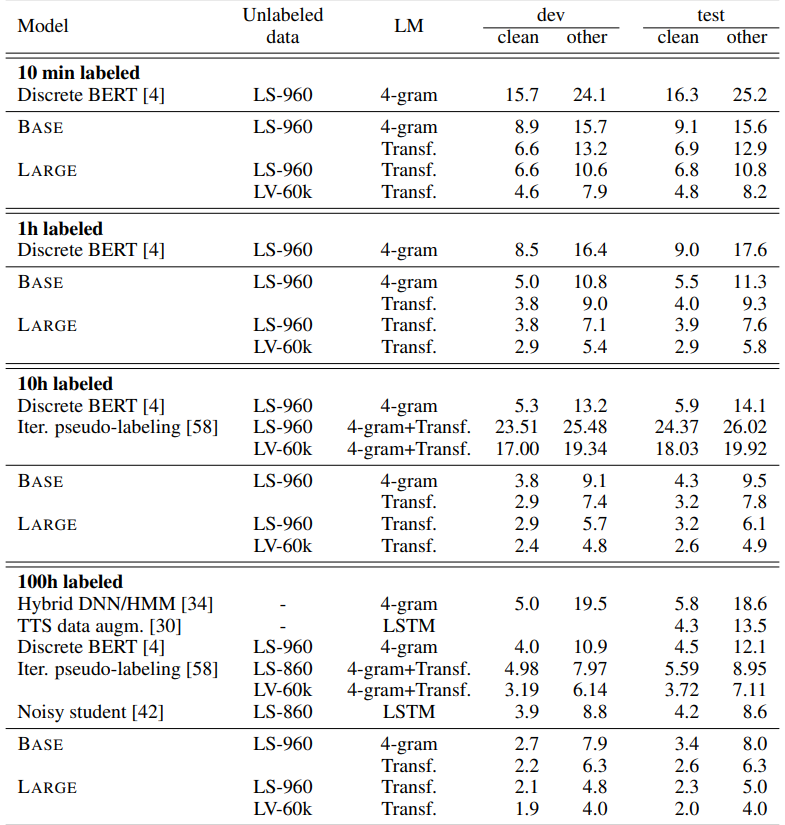
BASE / LARGE 부분이 wav2vec 을 사용한 결과를 나타낸다. 지표는 WER(Word Error Rate)로 나타내는데, WER의 계산식은 아래와 같다.
결국 WER 은
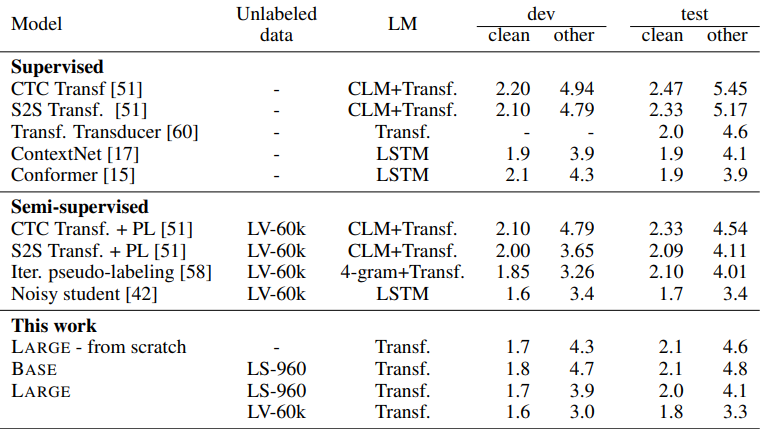
해당 논문은 wav2vec 2.0 을 제시하였으며, 이는 원시 음성의 잠재적인 표현을 마스킹하고, 양자화된 음성표현에 대한 대조 작업(contrastive task)을 해결한다. wav2vec 2.0은 라벨링되지 않은 데이터에 대한 사전 교육의 큰 잠재력을 보여주며, 레이블이 지정된 10분의 교육 데이터 또는 평균 12.5초의 48개의 녹음을 사용할 때 Librespeech 의 깨끗한 음성 / 기타 음성 부분에서 4.8 / 8.2 의 WER 을 보여준다.
특히 wav2vec 은 노이즈가 있는 음성에 대한 Librispeech 전체 벤치마크에서 혁신적인 결과를 달성하였다. 100시간 Librispeech 설정에서 라벨링된 데이터를 100배 적게 사용하면서 이전 최고 결관를 능가하는 퍼포먼스를 보여주었다.
wav2vec2.0 라고 해서 라벨링된 데이터가 필요하지 않은것은 아니다. 적은 라벨링 데이터가 주어졌을 때 다른 모델들 대비 압도적인 퍼포먼스를 뽐내지만, 데이터가 주어지면 성능이 더 올라가는것이 사실이다. 특히 960시간 학습세트, clean 데이터 기준으로는 Noisy Student 가 wav2vec2.0 보다 더 좋은 성능을 보여주기도 한다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] Robust Speech Recognition via Large-Scale Weak Supervision (0) | 2024.01.09 |
|---|---|
| [리뷰] GAN(Generative Adversarial Networks) (0) | 2023.11.23 |
| [리뷰] StarGANv2-VC (0) | 2023.07.29 |
| [리뷰] Style-Based GAN (0) | 2023.07.09 |
| [리뷰] PGGAN(Progressive Growing of GANs) (0) | 2023.06.24 |