Attention Is All You Need 는 Transformer 기술을 소개하는 논문으로서, 이전에 한차례 리뷰한 바가 있다.
이 중 CrossAttention 에 대한 한국어 포스팅이 많지 않아보여 작성해본다.

Transformer 는 Translation, VC, STT, TTS등 시계열 데이터를 처리하는데에 있어 사용할 수 있다. 즉 Decoder 의 출력은 Text 가 될수도 있고, Mel Spectrogram 형태가 될수도 있으며, 아마 '영상' 쪽으로도 출력을 내는게 가능할 것이다. (여기서는 번역을 기준으로 작성하겠다.)
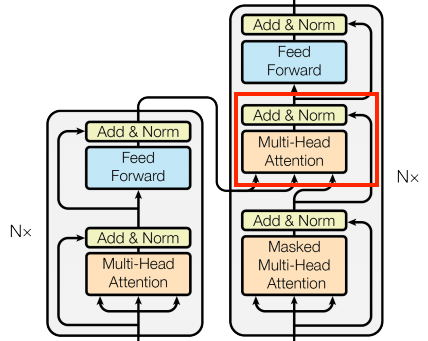
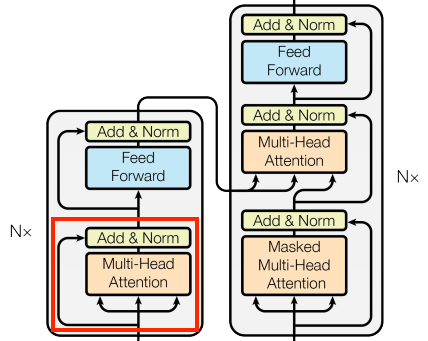
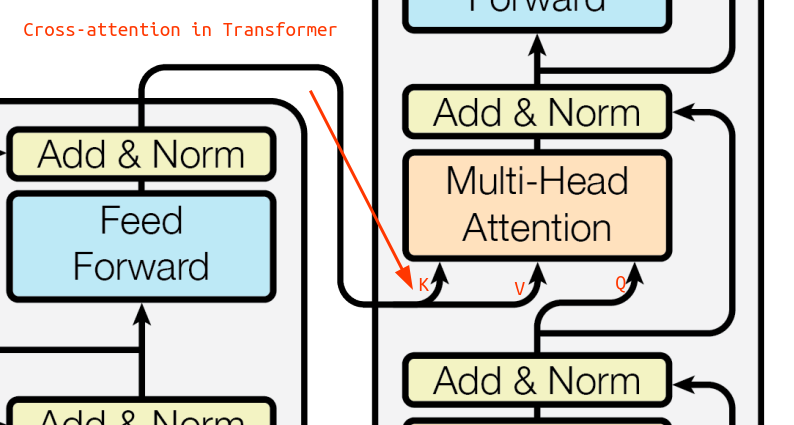
붉은박스로 표시한 CrossAttention 은 좌측의 Encoder 단에서 나오는 출력이, 우측의 Decoder 단으로 들어가는 구조이다.
먼저 코드를 살펴보자.
Source Code - CrossAttentionLayer
class CrossAttention(BaseAttention):
def call(self, x, context):
attn_output, attn_scores = self.mha(
query=x,
key=context,
value=context,
return_attention_scores=True)
# Cache the attention scores for plotting later.
self.last_attn_scores = attn_scores
x = self.add([x, attn_output])
x = self.layernorm(x)
return xCrossAttention 코드에서 Query 는 Decoder 단의 이전 Layer 로 부터 들어오며, Key 와 Value 는 Encoder 단에서 들어오는 형태이다. Key, Value 는 context 라는 같은 변수값을 할당한다는 것을 알 수 있다.
Source Code - GlobalSelfAttentionLayer
class GlobalSelfAttention(BaseAttention):
def call(self, x):
attn_output = self.mha(
query=x,
value=x,
key=x)
x = self.add([x, attn_output])
x = self.layernorm(x)
return x반면 SelfAttention 의 경우 Query, Key, Value 에 모두 같은값을 사용한다는 것을 알 수 있다.
CrossAttention 에 값이 어떻게 들어가는지 살펴보면 아래와 같다.
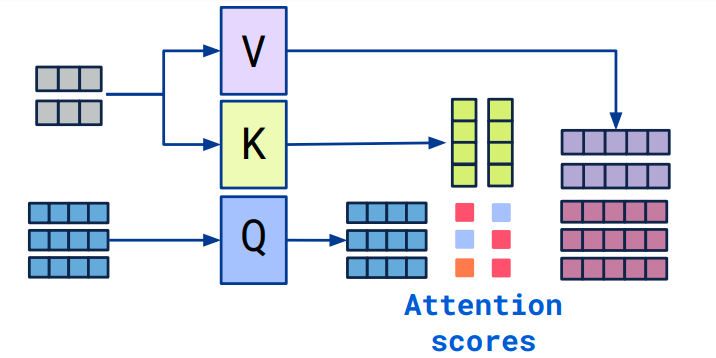
SelfAttention 에서는 Query $=$ Key $=$ Value 이지만.
Cross Attention 에서는 Query $\neq$ Key, Value 이다.
- Query - Decoder 의 이전 Layer 에서 전달되며, 현재 번역작업을 어디까지 진행하였는지 데이터를 가지고 있음.(current context) target 언어의 토큰값이 들어가게 됨.
- Key - Encoder 에서 Indexing 된 토큰들.(Source 언어의 값을 지님)
- Value - Encoder 에서 Indexing 된 토큰들. (Source 언어의 값을 지님)

여기서 먼저 Key 와 Value 를 곱함으로서 Source 언어에서 단어들간 어떤 관계가 있는지 찾은 뒤, 해당 결과를 다시 Query 값과 곱한다.(이 때 Query 값에는 Target 언어 Token 값이 존재.)
이 과정을 통해 Target 언어에 해당되는 Token 과 Source 언어에 해당되는 Token 의 연관성을 찾고,
다음에 올 단어를 예측해서 최종적인 번역 결과를 출력하는 것이다.
결론적으로 SelfAttention 과 CrossAttention 은 Input 을 제외하면 차이가 나지 않는다. (동일한 계산 방법)
하지만 Input, 목적에서 차이가 있으며 SelfAttention 은 번역작업 기준 Source 언어의 토큰별 관계를 파악하기 위해 진행한다면, CrossAttention 은 Target 언어와 Source 언어의 Token 간 관계를 파악하기 위해 사용된다.
'Artificial Intelligence > Basic' 카테고리의 다른 글
| 행렬 기초 (0) | 2024.04.17 |
|---|---|
| 모델 훈련시 Epoch 와 Steps 의 차이 (0) | 2024.03.05 |
| batch_size 란? (0) | 2024.03.05 |
| 인공지능에서 Parameter 란? (0) | 2024.01.27 |
| GAN의 최적 손실값 (1) | 2023.06.19 |