
Conformer 는 ASR 모델중 하나로서, 나온지 어느정도 지난 모델이다. 2020년 Google에 의해 공개 된 논문이기에, 굳이 리뷰할 생각을 가지지 못했었지만, 여러 논문들을 리뷰해 보니 Whisper, Wav2vec 2.0 등에 비해 뒤쳐지는 모델도 아닐뿐더러 굉장히 많이 인용된다는 사실을 알게 되었기에 리뷰한다.
이 포스팅의 본문을 볼 때 해당 논문이 2020년에 작성된 논문이라는 점을 인지하고 보길 바란다. 현행 ASR 에서 필수적으로 인용되는 wav2vec 2.0 역시 2020년도에 작성된 논문이기에, conformer 에서는 그러한 배경을 반영하기 어려웠다.
1. Introduce
end-to-end ASR 시스템은 최근 몇 년간 큰 발전을 이루었다. RNN 을 기반으로 Audio Sequences 의 시간적인 종속성을 효과적으로 모델링 할 수 있었고, 그 후에 self-attention 을 기반으로 하는 Transformer 아키텍쳐가 등장하며 보다 먼 거리에 있어도 상호작용이 가능한 능력과 높은 훈련 효율성(transformer 는 병렬훈련이 가능)으로 한차례 발전 하였고, 그와 동시에 convolution 또한 ASR 에서 성공적으로 작동하는 등 여러 발전이 있었다.
그러나 self-attention 이나 convolution 을 사용하는 모델에는 각각 한계가 있다. transformer 는 장거리 global context 를 모델링하는데 유용하지만, 세분화된 로컬 기능 패턴을 추출하는 능력은 떨어진다. 반면 CNN 은 로컬 정보를 잘 활용하는 대신 global 한 특징을 추출하는 능력은 떨어진다.
local window 를 통해 shared position-based 커널을 학습해 translation equivariance 을 유지하고 edge, shape 와 같은 특징들을 캡쳐할 수 있다. 하지만 이러한 local 연결성을 활용하는데에 있어 한계점은, 만약 global 정보를 캡처하려면 더 많은 layer, parameter 가 필요하다는 점이다. 해당 문제를 해결하기 위해 CNN 에서는 residual block 에 squeeze-and-excitation 모듈을 사용하여 더 긴 context 를 캡쳐한다. 그러나 이러한 방식 역시 전체 sequence 에 대해 global 평균만을 캡쳐하므로, dynamic - global 한 context 를 캡쳐하는데는 여전히 문제가 있다. (즉 global 한 특징을 추출하려면 그냥 transformer 에 비해서 convolution 은 열세이다.)
이러한 상황 속에서 몇몇 연구자들이 발견한 점으로, convolution 과 self-attention 을 결합해 사용하면 성능이 개선 되는것이 확인되었다. 이를 통해 위치별 local feature 를 학습하고, global 상호작용을 이용하는것이 가능하다.
본 연구에서 ASR 을 모델을 제작하는데 있어 convolution 과 self-attention 을 유기적으로 결합하는 방법을 연구하였다. 저자들은 global, local 상호작용이 parameter 의 효율성을 위해 중요하다고 전제를 깔아둔 채 연구를 진행하였고, 이를 달성하기 위해 self-attention 과 convolution 의 새로운 조합을 제안한다.

저자들은 attention head 수, convolution kernel size, activation function, feed-forward 레이어의 배치 및 Transformer 기반 네트워크에 convolution 모듈을 추가하는 등 여러가지 변형및 시도를 거쳤고, 각각이 정확도 향상에 어떻게 기여하는지 밝혔다.
2. Conformer Encoder
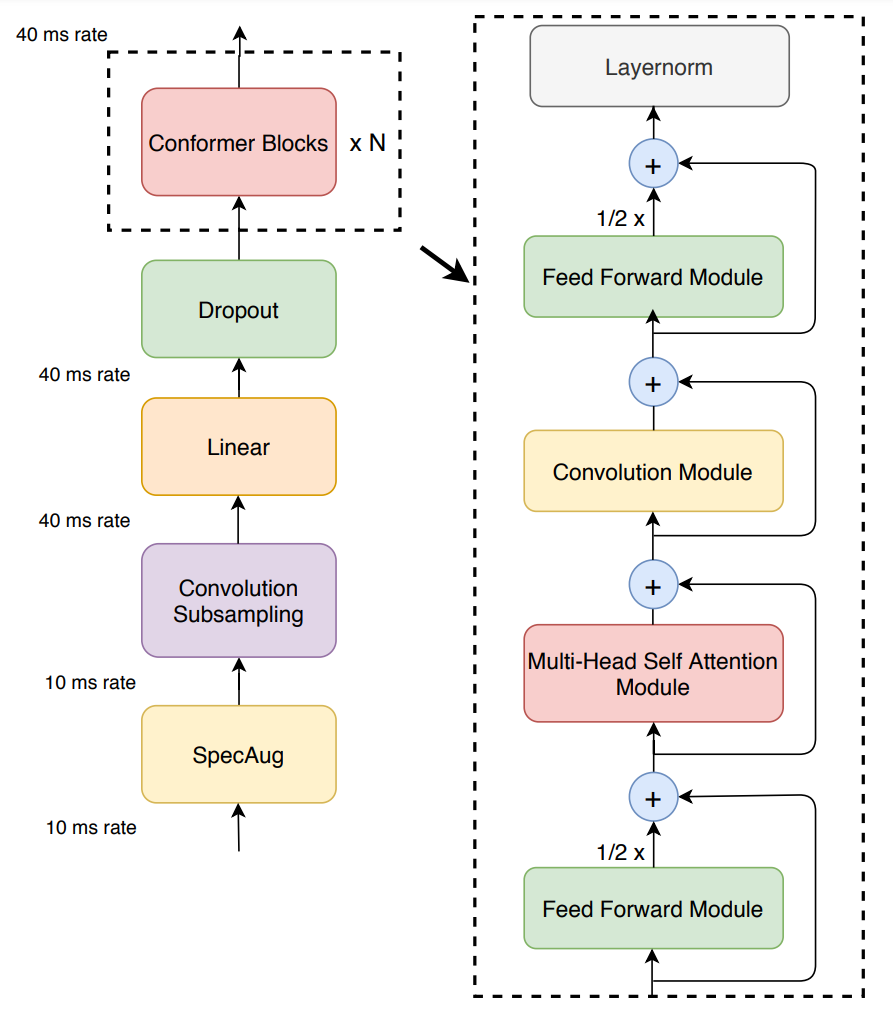
conformer 의 encoder 는 그림 1 과 같이 먼저 convolution subsampling layer 를 사용하여 입력을 처리한 다음 여러 conformer 블록을 사용하여 처리한다. 즉 기존 모델대비 해당 모델의 특징은 transformer block 대신에 conformer 블록을 사용한다는 점이다.
최종적으로 feed-forward 모듈, self-attention 모듈, convolution 모듈, second feed-forward 모듈로 구성된다. 아래 섹션에서는 해당 모듈들에 관해서 상세히 설명한다.
2.1. Multi-Headed Self-Attention Module
해당 섹터에서는 3가지에 관해서 이야기하고 있다.
- Multi-Headed Self-Attention(MHSA): Conformer 모델은 Transformer-XL에서 가져온 중요한 기술인 MHSA를 사용한다. 이는 모델이 입력 시퀀스의 다양한 길이에 대해 더 잘 일반화되도록 도와준다.
- Relative Sinusoidal Positional Encoding: Transformer-XL에서 유래된 방식으로. 상대적인 위치 정보를 포함하여 모델이 입력 시퀀스의 길이에 대한 변화에 더 잘 대응할 수 있도록 도와준다.
- Pre-norm Residual Units with Dropout: 훈련과 규제를 돕기 위해 pre-norm residual unit이 사용된다. 이는 더 깊은 모델을 효과적으로 학습하고 일반화할 수 있도록 도와준다.
transformer 모델에서 사용하던 Relative Sinusoidal Positional Encoding 을 동일하게 사용한다.
2.2. Convolution Module
Convolution 모듈은 GLU(Gated Linear Unit) 로 시작한다. 그 다음 single 1-D 깊이별 convolution layer 가 이어지는 형식으로 설계되어 있으며, 그림 2는 이러한 convolution block 을 보여주고 있다.
2.3. Feed Forward Module
transformer 아키텍처는 MHSA 뒤에 feed-forward 모듈을 배치하고, 두 개의 linear transformations 와 그 사이의 non-linear activation 으로 구성되어 있으며, 이러한 feed-forward 레이어 위에는 residual connection 이 추가되고 layer normalization 이 이어지는 형태를 띈다.
해당 논문에서 제안하는 Conformer 모델에서는 이러한 구조를 변형하여 수행하였다.
conformer에서는 pre-norm residual units을 따르며, layer normalization는 residual unit 내부 및 first linear layer 이전의 입력에 적용된다. 더하여 Swish activation function과 dropout이 적용되어 네트워크를 통제하는 데에 도움이 되었다. 이 구조는 feed-forward(FFN) 모듈을 설명하는 Figure 4에서 시각적으로 살펴볼 수 있다..
2.4. Conformer Block
저자들이 제안한 conformer 블록(그림 1) 에는 Multi-Headed Self-Attention 모듈과 convolution 모듈을 사이에 둔 두개의 feed-forward 모듈이 포함되어 있다.
이러한 샌드위치 구조는 transformer 블록의 원래 feed-forward layer를 attention layer 앞과 뒤의 두 개의 반단계 feed-forward 레이어로 대체하는 것을 제안하였다. 여기서 우리는 feed-forward 모듈에 반단계 Residual weights 를 사용한다. second feed-forward 모듈 뒤에는 최종으로 layernorm layer 가 위치한다.
수학적으로 이는 conformer
여기서 FFN은 feed-forward 모듈, MHSA 는 multi-head self-attention 모듈, Conv 는 convolution 모듈을 나타낸다.
해당 글에서는 적지 않았지만 논문에서는 이러한 구조 자체는 macaron-style(두개의 동일한 sub layer 사이에 다른 sub layer가 삽입된 구조를 지칭함.) 이라고 한다.(이는 macaron-net 에서 사용된 macaron-style 의 feed-forward 모듈로 제안되었다. 이를 conformer 에 적용한 것이다.) conformer 논문에서는 macaron-style 모듈을 사용하는것이 single feed-forward 모듈을 사용하는것 대비 상당한 개선을 가져온다는 것을 확인하였다.
추가로 논문에서는 convolution 과 self-attention 의 조합은 이전에 연구되었으며, 이를 달성하는데에는 다양한 방법이 존재한다고 언급한다. self-attention 을 사용하여 convolution 을 강화하는 다양한 옵션은 해당 논문의 '3.4.2. Combinations of Convolution and Transformer Modules' 에서 다루고 있으며, 결론적으로 연구진은 self-attention 모듈 뒤에 쌓인 convolution 모듈이 음성 인식과 전반적인 자연어 처리에 가장 적합하다는 것을 확인하였다.
2.5. 정리
최종적으로 그림 1. 을 보며 위의 내용을 정리 해 보자(다음 섹터는 실험 및 결과 섹터이다.)
최종적으로, Conformer 모델은 두개의 feed-forward 모듈 사이에 self-attention 과 convolution sub-layer(Conformer 내에 포함되어 있으므로 sub-layer 라고 지칭)를 삽입한 구조를 나타내며, 저자들은 이러한 형태가 가장 음성인식 & 자연어 처리에 있어 유용한 구조라고 결론 내린 것이다.
외에 Conformer network 에 입력하기 전에 처리하는 과정은 아래와 같다.
- SpecAug : SpecAugment이라는 데이터 증강 방법을 나타낸다.
- Convolution Subsampling : 입력 차원을 줄이기 위해 사용됨.
- Linear : linear layer를 나타낸다. linear layer는 입력 벡터와 가중치 행렬의 곱에 bias(편향) 벡터를 더하는 층이다.
- Dropout : 드롭아웃은 신경망의 과적합을 방지하기 위해 사용되는 정규화 기법이다. 드롭아웃은 학습 과정에서 임의로 일부 뉴런을 비활성화시킨다.
3. Experiments
3.1. Data
논문에서는 이렇게 완성된 Conformer 를 970시간의 LibriSpeech 데이터 셋으로 모델을 평가하였다고 한다.
논문 Experiments 섹터에서 mask 파라미터, 최대 time-mask 비율 등에 대한 정보 및,
Table 1 에서 Hyper parameter 에 대해 상세히 설명하고 있다.
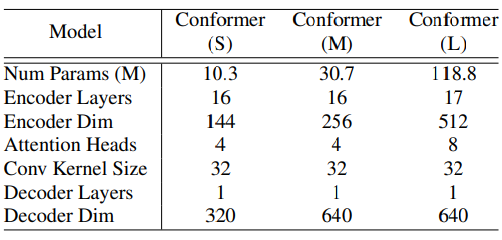
실제 모델을 개발, 운용할 때에는 중요할지 몰라도, 리뷰에서 크게 중요한 부분이 아니라고 생각하기에 생략하겠다.
3.2. Conformer Block vs. Transformer Block
Conformer Block 과 Trasformer Block 은 구조적으로 다르다.
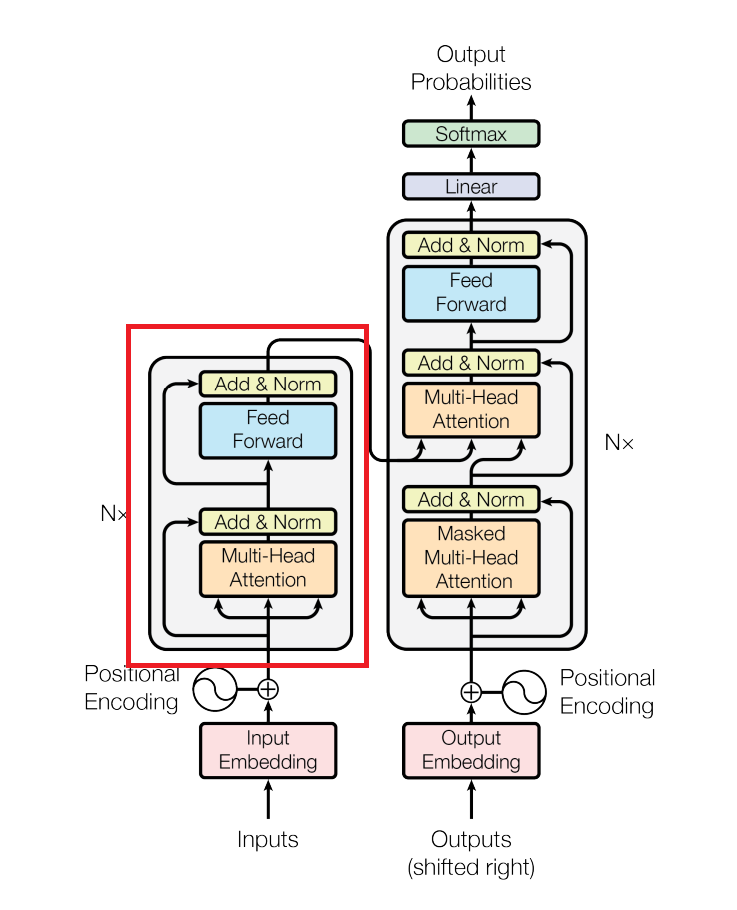
Transformer 는 encoder-decoder 구조로 되어 있으며 논문에서 비교하는 transformer 부분은 붉은 박스로 지정된 encoder block 부분이다.
결국 transformer block 시작부분에 feed-forward 모듈을 추가하고, multi-head attention 뒤에 convolution 모듈을 끼워넣은 형태가 바로 conformer block 이다.
저자들은 conformer block 을 transformer 블록으로 변형시키면서, parameter 는 변경하지 않음으로서 이러한 모델의 설계 차이가 어떠한 효과를 불러일으키는지 연구하였고, 그 결과가 표 3. 이다.
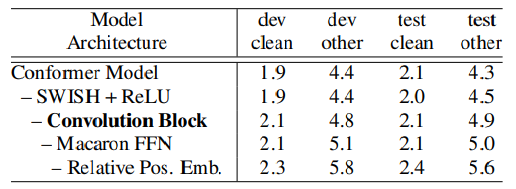
표의 첫번째 행이 conformer 블록이고, 가장 아래단이 transformer 블록을 통해 테스트한 결과물이라고 볼 수 있으며, 최종적으로 conformer 가 transformer 보다 모든 데이터 셋에서 우수하다는 점을 확인해 볼 수 있다.
그 외에도 논문에서는 여러 가지 테스트 결과표를 제공하고 있다. attention head 수를 변경하여 테스트한 것이라던지, convolution kernel size 를 변경하거나, macaron-net 에 좀 변형을 줘 본다든지 등등.. 흔히 새로운 모델을 개발할 때 '노가다' 짓을 한 결과표를 제공해 주고 있다.
4. Conclusion
결론적으로 해당 논문에서는 CNN 과 Transformer 을 구성요소를 결합하여 end-to-end 음성 인식 아키텍처인 Conformer 를 제안하였다.
LibreSpeech 데이터 세트에 대해서 이전 작업대비 더 적은 수의 parameter 를 사용 했음에도 불구하고 1.9%/3.9% (test/testother) 의 고무적인 성능을 달성하였다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] Low-resource expressive text-to-speech using data augmentation (0) | 2024.02.18 |
|---|---|
| [리뷰] Make-A-Voice (0) | 2024.02.15 |
| [리뷰] A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition (0) | 2024.01.11 |
| [리뷰] Robust Speech Recognition via Large-Scale Weak Supervision (0) | 2024.01.09 |
| [리뷰] GAN(Generative Adversarial Networks) (0) | 2023.11.23 |