
해당 논문은 OpenAI 에서 제작한 Whisper 라는 범용 목적의 음성 인식기를 제작하는데 있어서 사용된 논문이다.
1. Introduce
음성인식의 발전은 wav2vec 2.0 에 의해, unsupervised(unlabeled) pre-training 이 가능하게 됨으로 인해 기존에는 활용할 수 없었던 unlabeled 데이터를 생산적으로 사용할 수 있게 되었으며, unlabeled 데이터셋들이 빠르게 확장되는등 긍정적인 영향을 미쳤다.
하지만, 이러한 unlabeled 데이터로 학습된 encoder 는 고품질의 음성표현을 학습했지만, 해당 표현을 출력에 매핑하는 동등한 성능의 디코더는 부족한 실정이다. (ASR은 Encoder 와 Decoder 로 구성되며, 위에서 언급되는 wav2vec 2.0 역시 Encoder 역할을 한다.) 때문에 실제 음성인식 작업을 수행하려면 'fine-tuning(미세 조정) 단계' 가 필요하다. 그런데 이러한 ' fine-tuning' 작업은 숙련된 실무자가 필요한 복잡한 프로세스인 경우가 많기에 유용성을 크게 제한시킨다.
이미지 인식 분야에서 fine-tuning 단계를 거쳐 특정 데이터 세트에 대한 정확도를 9.2% 증가시켰지만, 이는 어디까지나 '해당 데이터셋' 에 국한된 이야기고, General 하게 정확도를 증가시키지 못한다는 맹점이 존재한다. 결론적으로, 특정 데이터 세트에서 '초인간' 을 달성하는 모델은 다른 데이터 세트에서 평가할 때 많은 오류를 발생시킬 수 있다.
결국, 음성 인식에서 unsupervised-pretrained 가 encoder 의 성능을 획기적으로 향상시켰지만, 비견되는 고품질의 pretrained decoder 가 존재하지 않다는 것이 현재 음성 인식 분야에서 유용성을 제한하는 중요한 약점이다. 때문에 현재 음성 인식 시스템의 목표는 decoder의 fine-tuning 을 필요로 하지 않고, 광범위한 환경에서 안정적이며, 즉각적으로 작동하도록 하는것이 목표이다.(즉 논문에서는 광범위하게 활용되려면 fine-tuning 자체를 지양해야 한다고 본다.)
추가로, 논문에서는 다른 논문들을 언급하며 한가지 증명된 사실을 이야기한다.
일반적으로 다수의 데이터 세트로 'supervised' 방식으로 pretrained 된 시스템은, 단일 소스에서 학습된 모델보다 더 높은 견고성을 보여주며, 더 효과적으로 일반화 되는 경향을 보인다. 하지만 근본적인 문제는 'supervised' 된 데이터 셋이 많지 않다는 데에 있다. 그나마 많은 supervised 데이터를 지닌 SpeechStew 는 기존 데이터셋을 혼합하여 만든 데이터 셋으로 총 5,140 시간의 감독된 데이터가 존재하지만 이 역시 매우 적은 양이다. 'unsupervised' 데이터 셋은 수백배에 달하는 1,000,000 시간의 데이터가 존재한다.

몇몇 다른 연구에서 'supervised' 데이터 셋을 더 크게 만드려는 노력을 하였고, 결국 30,000 시간의 데이터셋을 제작하는데에 성공했으나, 확장된 데이터셋(아마 여러 방법으로 Data Argumentation 하였을듯)은 엄밀히 깨끗한 고품질 데이터를 포기하고 제작되었다. 물론, 이러한 선택은 종종 적절한 선택이지만, 역시 문제는 그 분량으로 unsupervised 데이터셋보다 수백분의 1로 수준이다.
여기서 저자들은 그 격차를 줄이고, 약하게 감독된(weakly supervised) 음성 인식을 680,000 시간의 labeled audio 데이터로 확장하여 그 격차를 줄였다(이러한 접근 방식을 Whisper 라고 지칭) 이렇게 대규모로 훈련된 모델이 기존 데이터세트의 Zero-shot 으로 전송되어, 더이상 fine-tuning 이 필요하지 않음을 확인하였다.
이제 연구팀은 이러한 단순 데이터 셋의 '규모' 외에도, 영어 전용 음성 인식을 넘어, 약하게 감독된 사전 훈련의 범위를 '다국어' 및 멀티태스킹으로 확장하는데에 중점을 두고 있다고 언급한다. 위에서 기재한 680,000 시간의 오디오 중, 117,000 시간은 96개의 다른 언어들을 포함하며, 125,000 시간의 X → en 번역 데이터도 포함되어 있다.
여기서 핵심적인 계념은, 음성인식에 있어서 weakly supervised 가 과소 평가되었다는 점이다.
이렇게 서론(Introduce) 란은 끝나며, github 주소 역시 챕터 말미에 적어 두었다.
그런데 이 github 에서 재미있는 자료를 하나 확인할 수 있었는데, 바로 이렇게 완성된 whisper 의 '한국어' 인식 성능이다.
한마디로, 돌아이같은 CER 지표를 보여준다.
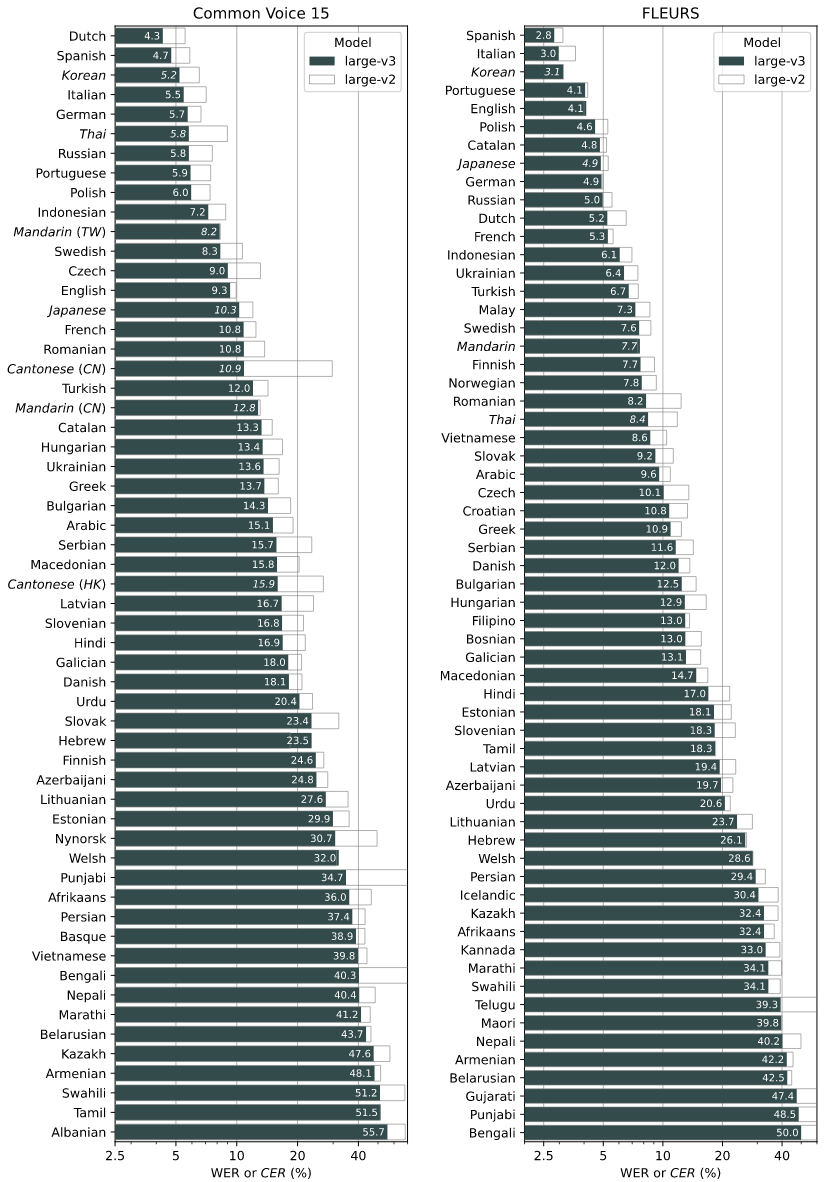
내가 개인적으로 수집한 Naver 사의 ASR의 경우 일반 청년 음성을 대상으로 한 CER 지표가 0.0311 이다. 이미 상용으로 사용되고 있으며, 한국에 본사가 위치한 Naver 사의 ASR 만큼 OpenAI 의 Whisper 모델의 정확도가 뛰어나다는 점이며, 더욱이 놀라운점은 이게 '한국어 전용' 으로 학습되지 않았다는 점이다. 정말 어처구니가 없을정도로 뛰어난 성능을 보여주는 모델이다.
해당 논문은 모델에 대해 새로운 관점을 제시하진 않았다.
일반적으로 널리 사용되는 Transformer 모델을 사용 하였지만.
데이터에 대한 새로운 접근법을 시사한 점이 특징이다.
2. Approach
2.1. Data Processing
저자들은 데이터 전처리 과정에 있어서 최소한의 접근 방식을 취한다고 언급한다. 기존 음성 인식에 대한 많은 작업들과는 달리 저자들은 발화와 발화 간의 매핑을 학습하기 위해 sequence-to-sequence 모델의 표현력에 의존하여 큰 표준화 없이 녹취록의 원시 텍스트를 직접 예측하도록 whisper 모델을 훈련시킨다. 이를 통해 음성 인식 파이프라인을 단순화할 수 있으며, 자연스러운 변환을 생성하기 위해 별도의 역 텍스트 정규화(ITN) 단계가 필요하지 않다는 장점도 있다.
이는 위에서 언급했던 고품질의 decoder 를 학습하는 것을 정면으로 타파하여, 전형적인 ASR 처럼 encoder-decoder 로 최종 텍스트를 출력하는 형태가 아니라 모델 자체가 모든 과정을 통합하여 최종적인 텍스트까지 출력한다.
데이터 세트는 transcript 와 쌍을 이루는 오디오로 데이터 세트를 구성하였다고 한다. 위에서 언급했듯 오디오 품질의 다양성은 모델을 견고하게 해 주는데 도움이 되지만, transcript 된 text 의 다양성은 유익하지 않다.(엄밀히 말해 weakly supervised 는 잘못된 transcript 된 text 역시 포함한다. 이러한 문제는 모델의 학습에 유용하지 않다는 의미.) 이를 해결하기 위해 transcript 품질을 향상시키기 위한 여러 자동화된 필터링 방법을 개발했다.
대부분 인터넷 상의 많은 transcripts 는 실제로 사람이 작성한 것이 아니라 ASR을 돌려서 만든 '출력물' 이다. 이러한 출력물들은 최근 연구 결과에 따르면 번역 시스템의 성능을 크게 손상시킬 수 있다. 때문에 이렇게 'machine-generated' 된 transcript 를 감지하기 위해 많은 휴리스틱을 개발했다고 한다.
이 방법은 기존의 많은 ASR 시스템이 복잡한 구두점(느낌표, 쉼표, 물음표) 문단의 공백 형식과 같이 오디오적인 신호에서만 예측하기 어려운 측면을 제거하거나, 정규화된 제한적인 하위집합만 출력하는 식으로 문제를 회피하는 성질을 보이며, 전체 대문자, 전체 소문자로 이루어진 transcript 를 작성하는 경향이 두드러지며, 대부분의 ASR 시스템에서 어느정도 수준의 역 텍스트 정규화가 포함되어 있지만, 단순하거나, 규칙기반이거나, 쉼표를 포함하지 않는 방식으로 처리된 경우에 이를 감지해여 해당하는 데이터셋을 훈련 데이터 세트에서 제거한다.

추가로 audio의 'language' 를 비교하는 VoxLingua107 를 사용함과 동시에, Text 의 language 를 비교하는 CLD2 를 사용해서 두가지 language 가 일치하지 않으면 해당 데이터도 훈련 데이터 세트에서 제거하는 방식을 사용한다.
하지만 만약 transcript 가 영어인경우 위에서 말한 번역 훈련에 이용한다.(이는 VoxLingua107 에서 감지된 언어가 다른 언어인데 반해, CLD2 에서 감지된 언어는 영어인 경우를 의미하는듯.) 여기서 중복 및 자동으로 생성되는 콘텐츠의 양을 줄이기 위해 transcript text 의 퍼지 중복 제거를 사용한다.
추가로 오디오 파일을 time segment 내에서 발생하는 스크립트의 하위 집합과 쌍을 이루는 30초의 segment 로 분할한다. 이를 통해 음성이 없는 segment 를 포함해 모든 오디오에 대해 훈련하고 이 segment 를 음성 활동 감지를 위한 훈련 데이터로 사용한다. (이는 데이터를 보다 쉽게 관리하기 위해서 30초 단위를 둔듯 하다.)
마지막으로 추가 필터링을 위해 초기 모델을 교육한 후 훈련 데이터 소스에 대한 오류율을 수집하고, 낮은 품질의 데이터를 효율적으로 식별하고 제거하기 위해 높은 오류율과 데이터 소스 키의 조합으로 이러한 데이터 소스를 정렬하는 수동 검사(사람이 직접) 역시 수행하였다. 해당 검사는 부분적으로만 transcript 되거나 정렬이 불량한 transcript 뿐만 아니라 필터링 휴리스틱이 감지하지 못한 낮은 품질의 machine-generated text 가 남아있는 것 역시 필터링한다.
이에 더해 편집증적으로 오염을 피하기 위해 훈련 데이터 세트와 더 높은 중복 위험이 있다고 생각한 평가 데이터 세트 사이의 transcript 사이 중복 제거를 수행한다. (당연히 훈련과 평가 데이터간 같은 transcirpt 데이터가 있으면 generalized 한 학습이 된다고 보장하기 어렵다.)
이러한 과정은 순수히 훈련용 Data 정제하기 위해서 이뤄지는 과정이다.
2.2. Model
저자들의 작업의 초점은, 음성인식을 위한 대규모 supervised pre-training 을 연구하는 것이기 때문에, 이것을 모델의 개선과 혼동하지 않도록 off-the-shelf(기성의, 특수하게 만들어지지 않은 기존에 존재하는것을 나타냄) 아키텍처를 사용했다. 이 아키텍처가 잘 확장하여 사용하는것이 목적이기에, encoder-decoder transformer 를 선택하였다.
모든 오디오는 16,000Hz 로 재샘플링 되었고, 80채널 로그 크기의 mel-spectrogram 표현은 10밀리초의 스트라이드로 25밀리초 윈도우에서 계산된다.
추가로 feature normalization 을 위해서 훈련 데이터 세트 전반에 걸쳐 평균을 0, 입력을 -1 ~ 1 사이로 확장한다. encoder 는 필터 폭이 3개인 두 개의 컨볼루션 레이어로 구성된 작은 stem 과 두 번째 컨볼루션 레이어가 2개의 스트라이드를 갖는 GELU 활성화 함수로 입력표현을 처리한 뒤, sin 모양의 위치 임베딩이 시스템의 출력에 추가도니 후 인코더 트랜스포머 블록이 적용된다. 트랜스포머는 활성화 전 잔차 블록을 사용하고, 마지막 레이어 정규화가 인코더 출력에 적용된다. 디코더는 학습된 위치 임베딩과 연결된 입력 출력 토큰 표현을 사용한다. endoder 와 docoder 는 트랜스포머 블록의 폭과 수가 동일하다. 아래 그림 1 은 이러한 모델 아키텍처를 요약한다.

2.3. Multitask Format
특정한 오디오 구간에서 어떤 단어가 발화되었는지 예측하는 것이 전체 음성 인식 문제의 핵심적인 부분이다.
이 문제는 광범위하게 연구 되었지만 이것이 유일한 부분은 아니다. 모든 기능을 갖춘 음성 인식 시스템에서는 음성 활동 감지나, 화자 분할,역 텍스트 정규화와 같은 많은 부분들이 포함될 수 있다. 하지만 이러한 구성 요소는 음성 인식과는 별도로 처리되므로, 모델 주변의 시스템이 모델보다 더 복잡해질 수 있다.
이러한 복잡성을 줄이기 위해 저자는 핵심 음성 인식 부분뿐 아니라, 전체 음성 처리 파이프라인을 단일 모델로 수행하려고 한다. 여기서 중요한 고려사항은 모델의 인터페이스로서, 동일한 입력 오디오 신호에 대해 수행할 수 있는 다양한 작업이 있다. 예로 - Transcript, 번역, 음성 활동 감지, 정렬, 언어 식별 등이 있다.
2.3. Training Details

저자들은 Whisper 의 스케일링 속성을 연구하기 위해 다양한 크기의 모델 제품군을 훈련한다고 한다.(표1 참조). 몇번의 epoch 동안 훈련만으로 과적합은 큰 문제가 되지 않으며, 데이터 증강이나 정규화를 사용하지 않고, 일반화와 견고성을 극대화하기 위해서 데이터 세트의 '다양성' 에 의존한다.(전체 훈련 하이퍼파라미터는 부록 F 참조)

초기 개발, 평가 과정에 있어 whisper 모델은 화자의 이름에 대해 거의 항상 잘못된 추측을 하는 경향이 있음을 발견했다. 이는 교육 데이터 세트의 많은 녹취록에 말하는 사람의 '이름' 이 포함되어 있기에, 모델이 이를 예측하도록 권장하기 때문에 발생한다. 때문에 이를 해결하기 위해 화자의 주석이 포함되지 않은 스크립트의 하위 집합에서 whisper 모델을 간략하게 fine-tuning 한다. (만약 '김민수' 라는 단어가 train 셋에 많이 있다면, '김민주' 라는 이름은 '김민수' 로 잘못 예측하게 될 수 밖에 없다. 이런 부분을 조절하기 위해 fine-tuning 한다.)
3. Experiments
3.1 Zero-shot Evaluation
Whisper의 목표는 특정 분포에서 고품질 결과를 얻기 위해 데이터 세트별 미세 조정 없이 안정적으로 작동하는 단일 구조의 강력한 음성 처리 시스템을 개발하는 것이다. 이 기능을 연구하기 위해 다양한 기존 음성 데이터 세트를 다시 사용하여 Whisper가 도메인, 작업 및 언어 전반에 걸쳐 잘 일반화할 수 있는지 확인했다. 저자들은 훈련 및 테스트 분할을 모두 포함하는 이러한 데이터 세트에 대한 표준 평가 프로토콜을 사용하는 대신 광범위한 일반화를 측정하기 위해 이러한 데이터 세트 각각에 대한 훈련 데이터를 사용하지 않고 제로샷 설정에서 Whisper를 평가한다.
음성 인식 연구는 일반적으로 WER(Word Error Rate)을 기반으로 시스템을 평가하고 비교한다. 그러나 문자열 편집 거리를 기반으로 하는 WER은 변환 transcript 스타일의 무해한 차이를 포함하여 모델의 출력과 transcript 간의 차이를 완화한다. 따라서 사람이 옳다고 판단할 수 있는 transcript 를 출력하는 시스템은 작은 형식 차이로 인해 여전히 큰 WER을 가질 수 있다. 이는 모든 transcript 에서 문제가 되지만 Whisper와 같이 transcript 형식의 예시를 관찰하지 않는 Zero-shot 모델에서는 특히 심각하다. (이는 다른 모델이 특정 Dataset에 대해 미세조정되고, 관찰된다는 의미를 뜻한다, 하지만 Zero-Shot 모델은 어떤 데이터셋에 노출될 지 모르니 최대한 General 한 포지션을 취하는데, 이로 인해 문제가 될 수 있다는 의미이다.)
인간의 판단과 더 나은 상관 관계를 갖는 평가 지표의 개발은 활발한 연구 분야이며, 몇 가지 유망한 방법이 있지만 음성 인식에 널리 채택된 것은 아직 존재하지 않는다.(그만큼 음성인식에 있어서 범용적인 한가지 평가방법을 제시하기에는 단점이 각각 존재한다)
저자들은 비의미론적 차이에 대한 부정적 판단을 최소화하기 위해 WER 계산 전에 텍스트를 광범위하게 표준화하여 이 문제를 해결하기로 선택했다. 개발한 텍스트 정규화기는 WER이 무해한 차이에 대해 Whisper 모델에 불이익을 주는 일반적인 패턴을 식별하기 위해 반복적인 수동 검사(고생 하셨습니다..)를 통해 개발되었다. 이를 통해 일반적으로 데이터 세트의 참조 전사체와 같이 공백이 있는 단어에서 수축을 분리하는 기이한 현상으로 인해 최대 50%의 WER 감소를 관찰했다. (부록 C에는 자세한 내용이 포함되어 있다.)
이하 부록 C 요약.
1. 일치하는 괄호 사이의 구문 제거([,]).
2. 일치하는 괄호 사이의 구문 제거((,)).
3. 다음 단어를 제거합니다: hmm, mm, mhm, mmm, uh, um
4. apostrophe(') 앞에 오는 공백 문자 제거.
5. 표준 또는 비공식적인 형식의 영어를 원래 형식으로 변환.
6. 숫자 사이에 쉼표(,) 를 제거
7. 숫자가 뒤따르지 않는 마침표('.') 를 제거
8. 텍스트에서 기호 및 발음 구별 기호를 제거한다. 여기서 기호란, M, S, P 로 시작하는 유니코드 범주의 문자를 뜻함.(통화, 백분율 기호 등은 제거하지 않음)
9. 숫자와 통화의 표현을 감지하고 아랍 숫자(e.g "Ten thousand dollars" → "$10000") 로 변경.
10. 영국 철자를 미국 철자로 변환.
11. 숫자 표현식(numberic expressions) 에 포함되지 않은 나머지 기호를 제거한다.
12. 연속된 공백 문자를 공백으로 변환.
1. 일치하는 괄호 사이의 구문 제거([,]).
2. 일치하는 괄호 사이의 구문 제거((,)).
3. 마커, 기호, 구두점 등을 공백으로 대체한다. (여기서 기호란, M, S, P 로 시작하는 유니코드 범주의 문자를 뜻함.)
4. 텍스트를 소문자로 변환.
5. 연속된 공백 문자를 공백으로 변환.
더하여 중국어, 일본어, 태국어, 라오어, 버마어 등 띄어쓰기를 사용하지 않는 언어는 모든 글자 사이에 띄어쓰기를 하여 문자오류율을 효과적으로 측정한다.
저자들은 위의 내용이 불완전한 해결책임을 인정한다. 때때로 의도하지 않은 또는 예상치 못한 결과물을 생성할 것이라는 점 역시 인지한다. 위의 결과로 나온 텍스트 형식이 어떤 측정에서도 더 "올바른" 것이라고 주장하지 않는다. 오히려 위의 절차는 악의 없는 문구 차이와 진정한 오역을 더 잘 구별하기 위해 고안되었다.
3.2 English Speech Recognition
2015년 Deep Speech 2는 LibriSpeech 테스트 클린 분할을 전사할 때 인간 수준의 성능과 일치하는 음성 인식 시스템을 보고했다. Deep Speech 2 논문 저자들은 "이 결과를 감안할 때, 우리는 더 이상 clean 음성에서 ASR이 더 개선될 여지가 거의 없다고 생각합니다."라고 결론 내렸다. 그러나 7년 후 LibriSpeech 테스트 에서 WER 지표는 5.3%에서 1.4%로 73% 더 떨어졌으며, 이는 보고된 인간 수준의 오류율 5.8%을 훨씬 상회하는 지표이다.
이는 분명 1.4%로 인간 수준이라는 5.8% 오류율을 훨 능가하는것임에도 불구하고, 까다로운 실제 환경에 비해 인간수준에 뒤쳐질 수 있다고 지적한다. → 즉 평가 방법 자체가 근본적으로 한 데이터 셋에 치중화된, 잘못된 것일 수 있다는 것을 시사한다.
인간과 기계의 행동 사이의 이러한 차이의 큰 부분이 테스트 세트에서 인간과 기계의 성능에 의해 측정되는 서로 다른 능력들을 혼동하기 때문이라고 의심한다. 이 주장은 처음에는 혼란스러워 보일 수 있지만 잘 생각해 보면, 인간과 기계가 train 받는 방식은 다르다는 점을 확인할 수 있다.
인간은 종종 연구 중인 특정 데이터 분포에 대한 감독이 거의 또는 전혀 주어지지 않은 작업을 수행하도록 요청 받는다. 따라서 인간의 성능은 분포 밖 일반화의 척도이다. 그러나 기계 학습 모델은 일반적으로 평가 분포에서 많은 감독을 받은 후에 평가되는데, 이는 기계의 성능이 분포 내 일반화의 척도임을 의미한다. 인간과 기계 모두 동일한 test 데이터에서 평가되지만 train 데이터의 차이로 인해 상당히 다른 두 가지 능력이 측정된다. (어린 아이가 어떻게 세상으로부터 train 데이터 세트를 얻는지 생각해 보자, 이는 기계의 train 과는 명백히 다르다.)
광범위하고 다양한 오디오 분포에 대해 훈련되고 Zero-Shot 설정에서 평가되는 whisper 모델은 기존 시스템대비 인간과 훨씬 더 잘 일치할 수 있다. 이것이 사실인지(또는 기계와 인간의 성능 차이가 아직 이해되지 않은 요인 때문인지) 연구하려면 whisper 모델을 인간 성능 을 지닌 fine-tuning 된 기계 학습 모델과 비교하고 어떤 것이 더 밀접하게 일치하는지 를 통해 확인할 수 있다.


결론적으로 저자들이 제시한 Whiser Large V2 와, 기존에 wav2vec 2.0 으로 학습된 모델들의 LibriSpeech Clean 지표는 '동일하지만' 여러가지 평가 데이터셋 들을 통해 정확도를 조사해 보면 매우 큰 차이가 발생하는것을 알 수 있다.
이게 바로 Whisper 가 주장하는 대규모 Weakly Supervised 데이터셋으로 학습된 '단순한' Transformer 모델의 힘이다.
각 데이터셋에 대한 설명은 아래와 같다.
- LibriSpeech Clean: LibriSpeech 데이터셋 중에서 배경 잡음이 적은, '깨끗한' 음성 녹음들로 구성된 부분이다.
- Common Voice: Mozilla가 제공하는 다국어 음성 인식을 위한 대규모 데이터셋으로, 전 세계 자원봉사자들이 제공한 음성 데이터로 구성된다.
- TEDLIUM: TED 강연에서 추출한 음성 데이터셋으로, 다양한 연사들의 강연을 포함한다.
- CHiME6: '6th CHiME Speech Separation and Recognition Challenge'에서 사용된 데이터셋으로, 일상 환경의 잡음 속에서 녹음된 음성을 포함한다.
- VoxPopuli En: 대규모의 유럽 의회 연설 음성 데이터셋.
- CORAAL: 다양한 아프리카계 미국인의 음성을 포함하는 데이터셋으로, 음성 인식 시스템의 다양성과 포괄성을 높이기 위해 사용된다.
- AMI IHM: AMI(Meeting) 데이터셋의 일부로, 회의 환경에서 녹음된 음성을 포함한다.
- Switchboard: 전화 통화를 통한 대화를 포함하는 데이터셋이다.
- WSJ: 'Wall Street Journal' 음성 인식 프로젝트에서 사용된 데이터셋이다.
- LibriSpeech Other: LibriSpeech의 다른 부분으로, '깨끗한' 부분에 비해 다소 잡음이 많은 녹음들을 포함한다.
3.3 Multi-lingual Speech Recognition

해당 논문에서는 Whisper v2 기준한 타 언어들의 성능을 보여주고 있다. 한국어는 약 15% 정도의 오류율을 보여주고 있다.
여기서 저자들은 특히 특정 언어에 대한 훈련 데이터 양과 해당 언어에 대한 다운스트림(사전에 모델이 특정 작업에 대해 사전에 별도로 튜닝되지 않았더라도) 제로샷 성능 사이의 관계를 연구하는 데 관심이 있었고, 따라서 그림 3에서 이 관계를 시각화했다. 단어 오류율의 로그와 언어당 훈련 데이터 양의 로그 사이에 0.83의 강한 제곱 상관 계수를 발견했다.
이러한 로그 값에 대한 선형 적합에 대한 회귀 계수를 확인하면 훈련 데이터가 16배 증가할 때마다 WER이 절반으로 감소하는 것으로 추정된다. 또한 이러한 추세에 따라 예상보다 성능이 좋지 않은 측면에서 가장 큰 이상치 중 많은 것이 고유한 스크립트를 가지고 있으며 히브리어(HE), 텔루구어(TE), 중국어(ZH) 및 한국어(KO)와 같은 훈련 데이터 세트의 대부분을 구성하는 인도유럽 언어와 관련이 있는 언어라는 것을 관찰했다. 이러한 차이는 언어적 거리로 인한 전송 부족, 바이트 수준 토큰화기가 이러한 언어와 일치하지 않거나 데이터 품질의 변화 때문일 수 있다고 추정한다. (즉 언어적 특징에 대한 사전 전처리를 Open AI 팀이 잘 이해하지 못해서 그런걸 수 있다는 말.)

MLS = Multilingual Libri Speech 라는 뜻이며, VoxPopuli 역시 다른 Dataset 이름이다. 이래 지표들은 WER 지표를 나타낸다. 살펴보면 MLS 기준해서는 다른 모델들 대비 우월한 성적을 보여주지만 VoxPopuli 기준해서는 좋지 않은 결과를 보여준다.
3.4 Translation

해당 표에서 언급하는 high-resource 언어란 기계학습, 자연어 처리 분야에서 풍부한 데이터 자원이 있는 언어를 총칭한다. 아마 데이터의 양 순서대로 나열, 구분하였을 것으로 추측되며, 여기서의 지표는 WER이 아닌 BLEU 지표이다.
고자원의 언어일수록 번역 성능이 전반적으로 높고, 저자원일수록 전반적으로 낮아진다. whisper 는 중자원, 저자원 및 평균적으로 가장 우수한 번역 성능을 보여주지만, 고자원일 경우 Maestro 모델에 비해 낮은 성능을 보여준다.

그림 4에서는 언어당 번역 학습 데이터 양과 결과적으로 Fleurs에 대한 Zero-Shot BLEU 점수 간의 상관 관계를 시각화 하였다. 학습 데이터가 증가함에 따라 개선되는 추세가 분명하지만, 제곱 상관 계수는 음성 인식에 대해 관찰된 0.83보다 낮은 0.24 값을 보여준다.
3.5 Robustness to Additive Noise

White Noise 또는 Pub 노이즈가 오디오에 추가되었을 때 WER을 측정하여 whisper 모델과 14개의 LibriSpeech 교육 모델의 노이즈 견고성을 테스트했다. Pub 노이즈는 붐비는 레스토랑이나 펍에서 전형적으로 주변 노이즈와 불분명한 대화가 있는 보다 자연스러운 노이즈 환경을 나타낸다.
14개 모델 중 12개 모델은 LibriSpeech에서 사전 교육 및/또는 미세 조정되었으며, 나머지 2개 모델은 LibriSpeech가 포함된 SpeechStew와 같은 이전 작업과 유사한 혼합 데이터 세트에서 교육된 NVIDIA STT 모델이다. 주어진 신호 대 잡음 비율(SNR)에 해당하는 추가 노이즈 수준은 개별 예제의 신호 전력을 기반으로 계산된다.
그림 5는 추가 노이즈가 더 집약적일수록 ASR 성능이 어떻게 저하되는지 보여준다. 여기서 X축 'db'는 음성 대비 잡음의 비율을 나타내는것으로, 40db 일 경우 음성이 잡음보다 40db 정도 '크다는' 의미로 해석하면 된다. 즉, 평균적인 상황에서 whisper 는 높은 성능을 보여주고 있다.
다만, 일반적으로 잡음이 적은 환경에서 최고의 성능을 보여주는것은 conformer 라는것 역시 확인할 수 있다.
3.6 Long-form Transcription
이러한 Whisper 모델은 위에서 언급했듯, 30초 세그먼트로 분할하여 학습했기에, 더 긴 오디오 입력을 한번에 학습할 수 없다. 이는 짧은 발화로 구성된 대부분의 학술 데이터 세트의 문제가 아니라, 종종 몇 시간 동안의 오디오를 전사해야 하는 실제 응용 분야에서의 문제를 제시한다.
여기서 저자들은 30초 분량의 오디오 세그먼트를 연속적으로 전사하고, 모델이 예측한 타임스탬프에 따라 윈도우를 전환하여 긴 오디오의 버퍼링된 transcript 를 전사하는 전략을 개발했다.
이러한 긴 오디오를 안정적으로 transcript 하기 위해서는 모델 예측의 반복성과 log 확률을 기반으로 Beam Search 및 Temperature Scheduling 을 수행하는것이 중요하다는 것을 관찰했다.

가능한 한 다양한 데이터 분포를 포괄하기 위해 다양한 길이와 녹음 조건의 음성 녹음으로 구성된 7개의 데이터 세트에 대한 긴 형태의 전사 성능을 평가한다. 살펴보면 TED-LIUM3 에서는 가장 우수한 성적을 보이며, 나머지 데이터 세트로 평가하였을 때는 Company B 정도 제외하고는 상회하는 성능을 보인다.
3.7 Comparison with Human Perfomance

Kincaid46 데이터 세트에서 25개의 녹음을 선택하고 5개의 서비스를 사용하여 전문가가 작성한한 transcript를 얻었으며, 그 중 하나는 컴퓨터 지원 Transcript 를 제공하고 나머지 4개는 전적으로 인간이 transcript 한 것이다.
whisper 는 인간수준의 성능을 보여주는것을 확인할 수 있다.
4. Analysis and Ablations
4.1 Dataset Scaling


Dataset 단위는 Hour 이며, 시간단위가 올라가면 올라갈수록 WER 지표가 낮아지는것과 BLEU 지표가 올라가는것 역시 확인할 수 있다.
4.2 Multitask and Multilingual Transfer
일반적으로 많은 언어에 대해 단일 모델을 공동으로 훈련할 때 학습간 간섭으로 인해 단일 언어 훈련보다 성능이 떨어지는 경우가 많다. 이것이 발생하는지 조사하기 위해서 영어 음성 인식에서만 훈련된 모델의 성능을 다중 작음 및 다국어 훈련 설정과 비교하고, Zero Shot 영어 음성 인식 벤치마크 제품군 전체에서 평균 성능을 조사하였다.
공동 훈련 설정에서 계산의 65%만 이 작업에 사용되기에, 영어 인식 작업에 훈련된 요소의 FLOPs(Floating Point Operations Per Second) 양을 조정한다.
FLOPs 를 조절함으로서 연구자들은 영어 음성 인식 작업에만 집중하여 훈련된 모델이, 전체 훈련 리소스 100%를 사용했을 때의 성능과 비교할 수 있다. 이런 방식으로 연구자들은 공동훈련이 모델의 성능, 특히 영어 음성 인식에 대해 어떤 영향을 미치는지 더 정확히 평가하는것이 가능하다.

결론적으로, 다른 언어의 데이터셋을 사용하더라도,
압도적인 데이터를 때려박으면 순수하게 영어 데이터셋만 사용한 것 보다 성능은 더 향상된다.
5. Conclusion
외에도 많은 것이 3-4 번 항목에 존재하지만, 성능에 관해서 이야기 하는 것이므로 생략하였다.
결론적으로 Whisper 는 지금까지 음성 인식 연구에서 Weakly Supervised 데이터가 과소 평가되었음을 시사한다. 저자들은 최근 대규모 음성 인식 작업의 주축이 되어온 self-training 기술 없이 결과를 달성하고, 크고 다양한 감독 데이터 세트에서 단순한 훈련방법으로, Zero-Shot 에 집중하는 것이 음성 인식 시스템의 견고성을 크게 향상시킬 수 있음을 보여준다.
6. 느낀점
해당 논문은 whisper v2 를 기준으로 작성된 논문이다. 2023년도 11월 경에 발표된 whisper v3 는 whisper v2를 사용해 수집된 weakly labeled 된 100만 시간의 labeled 데이터와, 그냥 labeled 된 400만 시간의 데이터를 통해 훈련되었다. 즉, 해당 논문(whisper v2)이 단지 68만 시간의 데이터로 처리되었음에 반해, 발전된 whisper v3는 500만 시간의(weakly + supervised) 데이터를 통해 학습된 것이다.
참고로 언급했듯, whisper v2 와 v3 간에는 어떠한 모델의 차이도 없다. 그냥 '데이터의 양' 차이라고 보면 된다. (pretrained)

이러한 whisper v3는 발표됨과 동시에 전체 ASR 중 최고성능을 달성했다.
해당 논문을 리뷰하면서 느낀 점이라면, 복잡한 모델을 쓰는 것 보다 단순한 모델을 쓰면서, 질 높은 데이터를 압도적인 양으로 때려박는것이 더 좋은 접근법일 수 있다는 것이다. 1만시간, 10만시간 단위의 데이터가 인간 입장에서 '충분한' 데이터로 보일지 몰라도, 사실은 그렇지 않다는 것이다. '100만시간' 단위의 어마어마한 데이터를 사용하는것이 쓸모없는 뻘짓이 아니라는것을 이번 Whisper 논문을 통해 Open AI 는 증명한 것이다.
다만, 충분히 잘 필터링된 weakly 데이터를 삽입해야 한다는 점은 명심하여야 한다. AI를 공부하면서 나도 최근 '모델' 에 집착하기 시작하였는데, 간단하고 획기적인 접근법을 Open AI 를 통해 배우게 되어서 뜻깊은 논문 리뷰였다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] Conformer (0) | 2024.01.22 |
|---|---|
| [리뷰] A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition (0) | 2024.01.11 |
| [리뷰] GAN(Generative Adversarial Networks) (0) | 2023.11.23 |
| [리뷰] wav2vec 2.0 (0) | 2023.08.21 |
| [리뷰] StarGANv2-VC (0) | 2023.07.29 |