해당 논문은 진행중인 연구와 매우 밀접한 연관이 존재하여 읽게 되었다.
Amazon Alexa 팀에서 2021년 발표한 논문으로 Voice Conversion 을 통해 Data Augmentation 하여 TTS 를 제작, 데이터 부족 환경에서 VC로 생성된 데이터가 유용하게 사용될 수 있다고 가능성을 보여준 논문이다.
1. 요약
최근의 Text To Speech(TTS) 시스템은 매우 잘 작동하지만, 원하는 발화 스타일로 TTS 하려면 상당한 양의 녹음이 필요하다. 해당 논문에서는 불과 15분의 녹음으로 표현 스타일 음성을 구축하기 위해 새로운 3단계 방법론을 제시한다.
- 다른 화자의 원하는 발화 스타일의 녹음을 사용하여 Voice Conversion 을 적용해 Data augment 한다.(합성 데이터)
- 제작한 합성 데이터를 사용하여 TTS 모델을 훈련한다.
- 품질을 더욱 높이기 위해 해당 모델을 미세 조정한다.
평가 결과, 제안된 방법을 적용할 시 합성 음성의 여러 측면에서 증강되지 않은 모델에 비해 상당한 개선을 가져오는 것으로 확인되었다.
2. 소개
최근의 TTS 시스템으로 생성된 음성은 매우 자연스럽고, 음성의 품질 역시 향상되었지만, Tacotron 과 같은 모델들은 최소 10시간의 label-voice 쌍을 필요로 한다. 이러한 데이터를 수집하는 것은 비용적으로 큰 부담이 되는 작업이기에 대안이 필요하다.
문제를 해결하기 위해 저자원 TTS 에 초점을 맞춘 여러 연구는 다중 화자 모델링과 전이 학습을 통하여 제한된 데이터의 영향을 완화하려고 하였다. 이러한 방법으로 시스템의 품질을 향상시킬 수 있었지만, 부족한 데이터 문제를 해결하기 위한 유일한 방법은 아니다.
데이터 증강은 앞서 언급한 문제를 극복하기 위해 기계 학습의 여러 분야에 걸쳐 사용되어 왔다. 특히 컴퓨터 비전에서 더 나은 모델을 훈련하기 위해 합성 데이터를 만드는 것이 철저하게 조사되었으며, 이와 더불어 음성 분야, 특히 자동 음성 인식(ASR) 분야에서도 연구되어 왔다. 그러나 합성 음성 데이터를 만들기 위해 수많은 연구가 진행되었음에도 불구하고, 비표현 TTS(감정이나 톤 강세 등이 없는) 최종 목표에만 활용하는 것으로 보인다.
multi-speaker TTS 모델을 훈련시키고 이를 특정 target-speaker 에 대한 합성 데이터를 생성하는데에 사용하며, 이 합성 데이터를 다시 새로운 target-speaker TTS 모델을 훈련시키는데 사용한다. 이는 리소스가 적은 multi-speaker 모델이 target-speaker 에 대한 음성을 합성할 수 있다고 가정한다.(여기서 target-speaker 는 목표로 하는 화자의 목소리, 아마도 single-speaker 를 의미한다.)
multi-speaker TTS 훈련 → target-speaker 합성 데이터 생성 → 새로운 target-speaker TTS 모델 훈련
결론적으로 target-speaker 에 대한 데이터가 매우 부족한 상황(10min, 기존에는 10hour) 을 타파할 수 있는 새로운 3단계 방법론을 제시한다. 아래 Result 단에서는 이러한 방법론으로 생성된 데이터를, 직접 청취자들에게 평가받아 그 성능을 평가받는다.
3. 방법론
제안된 방법론은 3단계로 구성된다.
- VC 모델을 활용하여 합성 데이터를 생성한다.
- 새로 생성된 합성 데이터를 대상 화자 녹음과 함께 사용하여 최첨단 TTS 모델을 훈련한다.
- TTS 모델의 미세 조정을 수행하여 더 높은 품질을 달성한다.
이제 이러한 단계를 더 자세히 설명한다.
3-1. Data augmentation

저자들은 합성 데이터를 만들기 위해 Copycat 모델을 VC 모델로 활용한다.(즉, VC로 Data Augmentation)
해당 모델은 세분화된 운율 전달 모델로, 화자 신원을 변환하면서 소스 오디오에서 운율과 언어, 콘텐츠를 유지하는 것을 목표로 한다.
모델은 간단히 아래와 같이 3가지 요소로 구성된다.
- 음소의 잠재 임베딩을 학습하는 음소 인코더(phoneme encoder)
- 멜-스펙트럼에서 운율 표현을 분리하는 운율 병목 인코더(prosody bottlenect encoder)
- 음소 임베딩, 운율 표현 및 제공된 화자 임베딩이 주어지면 멜-스펙트럼을 생성하는 병렬 디코더(parallel decoder)
결과를 음소 인코더로 전달하기 전에 스피커 임베딩을 업샘플링된 음소에 연결하여 모델에 한 가지 수정 사항을 가한다. 이는 Speaker ID(개별 화자를 구분하기 위한 ID)에 따라 음소를 인코딩하는 데 도움이 되며, 따라서 VC 프로세스에 도움이 된다.
VC 모델은 하나 이상의 소스 스피커와 대상 스피커에 대해 훈련되어, $X$ 스타일의 표현 샘플을 소스 스피커 $S$에서 대상 스피커 $T$로 변환할 수 있다. 샘플은 녹음만큼 완벽하지는 않지만 여전히 우수한 품질이며 더 나은 TTS 모델을 훈련하는 데 도움이 된다.
3-2. TTS Model

저자들의 TTS 시스템은 운율 캡쳐를 위해 VAE가 있는 Tacotron 과 같은 구조를 기반으로 한다.
다양한 시나리오에서 견고하게 운용하도록 multi-style single-speaker 혹은 single-style multi-speaker 모델을 훈련한다. 후자의 모델을 훈련할 때, decoder 수준에서 미리 훈련된 speaker embedding 을 추가시킨다(이미지 하단)
4. Result
평가 전반에 걸쳐 모델을 평가하기 위한 4가지 지표에 중점을 둔다.
- 신호 품질(샘플의 신호 품질은 얼마나 좋은가?)
- 스타일 적절성(샘플이 원하는 스타일과 일치하는가?)
- 자연스러움(샘플이 자연스럽게 들리는가?)
- 화자 유사성(샘플이 대상 화자와 유사한가?)
결국 TTS 는 Speech 된 결과를 평가해야 한다. 저자들은 이를 청취자들에게 샘플을 제공하는 방식으로 테스트 하였다고 한다.(MUSHRA 테스트)
뉴스 캐스터 데이터는 200개의 테스트 샘플을 확보하였고, 이를 테스트하기 위해 200명의 테스터를 모집하였다.
대화형의 경우 8개의 대상 화자의 50개 테스트 발화가 평가되며, 크라우드 소싱 플랫폼을 통해서 테스트 하였다.

- VC : Voice Conversion.
- FT : Fine Tuning
재미있는 점은 단순히 Base 데이터셋에 Fine-Tuning 만을 수행하였을 때 보다 Voice Conversion 을 통해서 데이터를 보강 하였을 때 더 높은 수준의 TTS 제작이 가능 하였다는 점이다. 여기에 두가지 방법을 결합 하였을 때 가장 좋은 점수를 보여준다는 것을 표 2 에서 확인할 수 있다.
여기서 저자들은 이러한 방법론이 데이터 양에 어떻게 영향을 받는지 비교하기 위해 데이터 축소(DR) 비 데이터 축소(NDR) 시나리오 간의 추가적인 평가를 진행하였다.
저자들이 작업 전에 추측하기론, DR은 NDR 대비 더 적은 데이터에 대해 훈련되기에 성능이 떨어질것으로 추측한다.
이제 결과를 살펴보자.

- Recs : speaker 의 원본 녹음본 (뉴스캐스터) 이므로, 사실상 해당 점수가 '만점' 으로 볼 수 있다.
- NDR : Recs 로 학습시킨 TTS 모델
- DR : 더 적은 데이터로 훈련시킨 TTS 모델
- Neutral : 중립적인 감정의 데이터로만 훈련시킨 TTS 모델
결론적으로 위 표에서는 DR+VC+FT 의 성능이 DR 보다 훨신 우수함을 나타낸다. 이는 꽤 중요한 증명 과정인데, VC 라는 AI를 통해 생성해 낸 데이터로 → 다른 AI 를 학습시켰을 때 성능이 증가될 수 있음을 보여주었기 때문이다.
마지막으로 저자들은 robustness(모델이 변화하는 환경에 강건하게 작동하는 능력) 한지 보기 위해 테스트를 진행하였다.
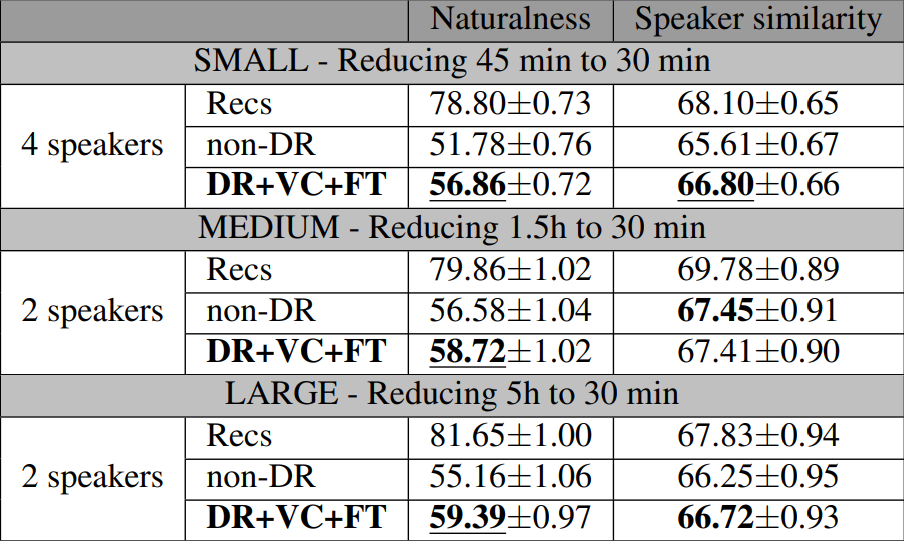
이를 통해 데이터가 '감소' 되었을때 효과를 비교할 수 있다. 여기서 좀 의아한 부분이 존재하는데, 결국 30min 의 데이터만 선택하다는데, 어떤 방식으로 선택하였는지 구체적으로 기재되어 있지 않다. 만약 3가지 실험 모델이 모두 동일한 30min 데이터로 학습되어 의미가 없을수도 있는것이다.
5. 느낀점
일단 뭐 아마존 팀에서 작성한 논문이니 의미가 없으리라 생각되지는 않지만, 논문에 몇몇 있어야될 정보가 존재하지 않는다는 느낌을 받는다. 특히 VC 기술을 사용했다고 하면서, 구체적으로 '얼마만큼의 데이터를 VC 했다' 라고 기재한 부분이 존재하지 않다.(사기업인 만큼 추상적으로 작성한 느낌이다)
어쨋든 해당 논문으로 알게 된 점은, TTS 영역에서 데이터가 부족할 시 'VC + FT' 를 통해서 처리할 수 있다는 점이다(사실 위에서 사용한 Copycat 모델이나, TTS 구조는 별로 궁금하지 않다... Data Augmentation 할 수 있는 모델은 많이 존재하고 내 관심사는 TTS가 아닌 STT 이기 때문이다.) 이는 고무적인 점으로, 음성쪽에서는 잘 준비된 데이터가 부족한 경향이 있다. 하지만 VC를 잘 이용해 데이터를 증강한다면 이러한 문제를 해결할 수 있다는 가능성을 보여준 논문이다.
이는 음성 데이터가 이미지 데이터보다 더 낮은 정밀도를 요구한다는 점으로 인해 발생한 장점이라고 추측된다. 이미지 데이터의 경우 어느 한 지점에 작은 오류가 있어도 쓰지 못하게 되는 경우가 많다. 예로 '강아지' 를 그리라고 했는데, 눈동자가 '고양이' 눈동자라면 이를 다시 학습용 데이터로 사용하기에 문제가 될 것이며, 많은 경우 특정 영역의 노이즈가 발생하면 아예 쓰지 못하게 되는경우도 흔하다.
하지만 VC로 생성된 음성 데이터의 경우 실제 발화 구간에 어느정도 노이즈가 발생하더라도 이를 데이터로 사용할 수 있을 정도이다. 사람이 듣기에 큰 이질감을 느끼지 못하는 노이즈가 대다수이기 때문이다.
물론 이러한 추측성 주장은 어디까지나 나의 경험적인 근거에 의한 추측이다.
해당 논문의 의의는 생각보다 클 수 있다.
AI 모델을 통해 생성해낸 데이터를 → 다시 AI 학습용으로 썻는데 성능이 올라가네? 라는 논리가 성립하기 때문이다. 아무쪼록 Voice 관련 AI 가 많이 발전해서 빠르게 자비스를 쓸 수 있게 될 날이 오기만을 고대하는 바이다.(물론 자비스는 단순 Voice AI 는 아니긴 하지만 뭐... 최종 테크는 결국 그쪽으로 수렴하지 않을까? ㅋㅋ..)
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] TRIAAN-VC (0) | 2024.02.23 |
|---|---|
| [리뷰] HiFi-VC: High Quality ASR-Based Voice Conversion (0) | 2024.02.20 |
| [리뷰] Make-A-Voice (0) | 2024.02.15 |
| [리뷰] Conformer (0) | 2024.01.22 |
| [리뷰] A comparative analysis between Conformer-Transducer, Whisper, and wav2vec2 for improving the child speech recognition (0) | 2024.01.11 |