TRIAAN-VC 논문은 any-to-any voice conversion 을 수행하는 모델이다.
나는 IEEE 에서 여러 VC 논문들을 찾아보았다. 특히 2020년 이후에 제작된 any-to-any 모델들을 중점적으로 살펴보았다.
그간 VC 관련 논문들을 꽤 많이 읽어보았고, 그에 따른 결론은 '구조가 어떻게 되든 일단 성능이 최고인 것을 찾자' 였다. Speech 데이터를 생성하는 모델은 성능을 평가하기가 '까다롭다'. 보통 많은 청취자를 동원해서 직접 사람이 통계적으로 평가를 하는 MOS 지표를 토대로 평가한다. 좀 비 과학적으로 보일 수 있어도, MOS 점수가 내가 주관적으로 느끼는 모델의 실제 성능과 엇나간 적은 없다.
어쨋든 IEEE 에서 여러 논문들을 검색해 본 결과, 일부 모델들은 MOS 점수를 제공하지 않고, demo 조차도 제공하지 않아 모델의 직접적인 성능을 가늠하기 어려운 것들이 많았고, 기존 방법 대비 유의미하게 성능이 증대되지 않는것들도 꽤 있었다.
그러던 도중 발견한것이 바로 이 TRIAAN-VC 논문인데, 정말 뛰어난 성능을 보여준다. 이전 HiFi-VC 논문에서 말했던 여러 any-to-any 모델은 content 발화의 문제는 없었지만, 유사성에서 문제가 있었는데, 해당 모델은 content 의 발화 부분은 물론이고 VC 된 음성의 유사성 마저도 크게 개선되었다.
데모를 들어보길 바란다.
1. INTRODUCTION
VC는 source speaker 가 말하는 음성내용(content)을 유지한 채, target speaker 의 음성으로 변환하는 것이다.
논문에서 제시되는 모델은 any-to-any 변환이 가능하며, 훈련중 겪어보지 않은 speaker(unseen speakers)에 대해서도 적용할 수 있는 기술이다. 동시에 모델은 one-shot 기술이 적용되어 몇 초 분량의 target 음성만으로도 올바르게 변환될 수 있다.
저자들이 제안하는 방법과는 달리, 이전 방법들은 여러 문제가 있었다.
최초에 VC는 vector quantization(벡터 양자화) 방법을 통해 discrete codes 를 content 로, discrete features 와 continuous features 의 차이를 speaker 표현으로 사용하였다. 그러나 discrete codes 로 content 를 표현하면 시간 관계(time relationships) 가 손상되어 content 가 망가지는 문제점을 시작으로 여러 문제를 해결하기 위해 아래와 같은 과정이 있었다.
- vector quantization 사용함 → 시간 관계가 손상되어 content 손상되는 결과가 나타남.
- 그래서 attention-based conversion 으로 바꿈 → speaker 특성과 유사하게 잘 바뀌는데, 너무 결과가 'speaker 유사성' 에만 편향됨.(특정 speaker 에 집중되는 문제 및 content 쪽이 깨지는듯?)
- 그래서 AdaIN 도입함 → 높은 수준의 speaker 특징만 사용해서 결과가 speaker 유사성에 편향되게 만듬.
- 근데 AdaIN 은 충분한 speaker 특성을 나타낼 수 없다는 문제점이 존재함.
결론적으로 이전의 방법들은 any-to-any VC 에서 상당한 개선을 이뤘지만, source content 의 유지나, target 의 유사성만을 만족하는 결과를 가져왔다.
그래서 저자들은 Triple Adaptive Attention Normalization VC(TriAAN-VC) for non-parallel A2A(any-to-any) VC 를 제안한다.
encoder-decoder 구조를 기반으로 하는 TriAAN-VC 는 content 와 speaker의 특징을 분리하며, TriAAN Block 은 세부 및 전역 speaker features 를 추출하며, conversion 을 위한 정규화(normalization)를 사용한다. 추가로 source content 를 최대한 유지하기 위해 시간 마스킹을 갖는 샴(siamese) 손실이 적용된다.
결론적으로 TriAAN-VC 는 source content 의 유지, target speaker 와의 유사성 부분에서 모두 우수한 성능을 달성했다.
2. METHOD

S2VC 에서 제안한 CPC 특징이 VC 성능 향상에 기여하기에, TriAAN-VC 는 모델의 입력으로 이를 사용하며, 사전 훈련된 모델을 사용하여 원시 오디오 $x_{raw} \in \mathbb{R}^{t}$ 에서 CPC 특징 $x \in \mathbb{R}^{H \times T}$ 를 추출한다.
- $H, T$ : $x_{raw}$ 의 hidden size 및 세그먼트 길이
- $t$ : $x_{raw}$ 의 신호길이
또한 DIO 알고리즘을 $x_{raw}$에 적용하여 소스 스피커의 피치 정보를 표현하기 위해 $\log F0$($x_{f0} \in \mathbb{R}^T$) 를 추출한다.
* CPC : Unsupervised Learing 방법론 중 데이터에 있는 Shared information을 추출하는 방법으로. Target Class를 직접적으로 추정하지 않고 Target 위치의 벡터와 다른 위치의 벡터를 비교하는 방식으로 학습한다. 또한 두 벡터 내에 공유정보인 shared information을 직접적으로 추출하는 함수를 구성하고 이를 최대화 할 수 있는 InfoNCE Loss를 제시한다. 이를 통해 비교적 짧은 시간동안 효율적으로 모델을 학습할 수 있으며, 모델로부터 다양한 용도에 활용할 수 있는 좋은 Representation Vector를 추출할 수 있다. 해당 방법론은 다양한 분야(이미지, 텍스트, 음성 등)에 활용이 가능하며 기존 Unsupervised 방법론과 비교했을 때 더 좋은 representation을 생성하는 것을 실험적으로 증명하였다.
그림과 같이 TriAAN-VC 는 두개의 encoder 와 decoder 로 구성되어 있다. encoder 는 각각 content와 speaker 정보를 추출하는 encoder 로 구성되어 있으며, encoder-decoder 는 botteneck layer 를 통해서 연결되고, 각각 $L$ 개의 layer 로 구성된다.
encoder 이전에 $x_{c,s} \in \mathbb{R}_{c,s}^{H \times T}$ 에 Convolution layer 를 적용하여 $H$ 를 채널 크기 $C$ 로 확장한다.($\mathbb{R}_{c,s}^{H \times T}$ - $c, s$ 에 대한 $H \times T$ 크기의 행렬)
- $x_{c,s}$ : 특징이 추출된 후 content, speaker 를 나타낸다.
Encoder

encoder 에서 각 encoder layer 는 convolution block 과 인스턴스 정규화로 구성되며, speaker encoder 에만 speaker attention 이 적용된다. 추가로 convolution block 은 kernel size - 3, stride - 1 인 두 개의 convolution layer 를 포함하는 residual block 으로 설계되었다.
Bottleneck Layer

병목계층(bottlenect layer)는 인코더 프로세스 이후에 source speaker $x_{f0} \in \mathbb{R}^{T}$의 f0 pitch 를 표현하는데 사용된다. 만약 $x_c^{'} \in \mathbb{R}^{C \times T}$ 가 content encoder 의 출력이라고 할 때, $x_c^{'}$ 와 $x_{f0}$ 사이에 연결된 출력들이 GRU 계층에 들어간다.
더하여 decoder 이전에 DuAN(Dual Adaptive Normalization) 을 콘텐츠 및 스피커 표현들에 적용함으로서 초기 변환 표현이 생성된다.
Decoder

각 decoder layer 는 encoder 가 가진 conv block 과 동일하게 conv block 을 가지고, TriAAN Block 을 포함한다.
TriAAN Block 은 이전 layer 의 content feature 를 사용하여 변환을 수행하고, speaker encoder 계층으로부터 수집된 feature map 을 사용한다.
최종적으로 docder 의 출력은 GRU 계층과 PostNet 에 의해 정제되어 log mel-spectrogram 을 예측한다.
추가로 아래서는 해당 모델의 핵심적인 부분인 Speaker Attention 과 TriAAN block 에 대해 간단히 설명한다.
2-1. Speaker Attention
AdaIN을 TIN(Time-wise IN) 으로 개선하고 TIN 기반 SA(Speaker Attention) 을 설계하였다. (AdaIN의 핵심적인 부분인 인스턴스 정규화(IN)을 시간 차원 정규화(TIN)으로 수정.)
TIN 의 경우 IN 과 달리 시간별로 평균 및 표준 편차로 정규화 되어 채널 관계를 보존할 수 있다.
$$ \begin{flalign}
Q=TIN(x_s)W_q,\quad K=x_sW_k,\quad V=x_s W_v \\
Attention(Q,K,V) = softmax(QK^\top / \sqrt{d})V \\
\end{flalign}
$$
- $x_s \in \mathbb{R}^{T \times C}$ : 화자 특징
- $W_{q, k, v} \in \mathbb{R}^{C \times C}$ : 가중치(SA 도 Attention 이므로 Q, K, V 가 사용된다.)
결론적으로 Speaker Attention 은 쿼리정보를 Time-wise IN(TIN)의 결과로 사용하여, Speaker Attention(SA)를 통해 확대하고 변환에 사용된 스피커 특성의 채널 관계를 강조하고 보존한다.
2-2. TriAAN block
decoder 내부에 존재하는 TriAAN Block 의 구조는 아래와 같다.
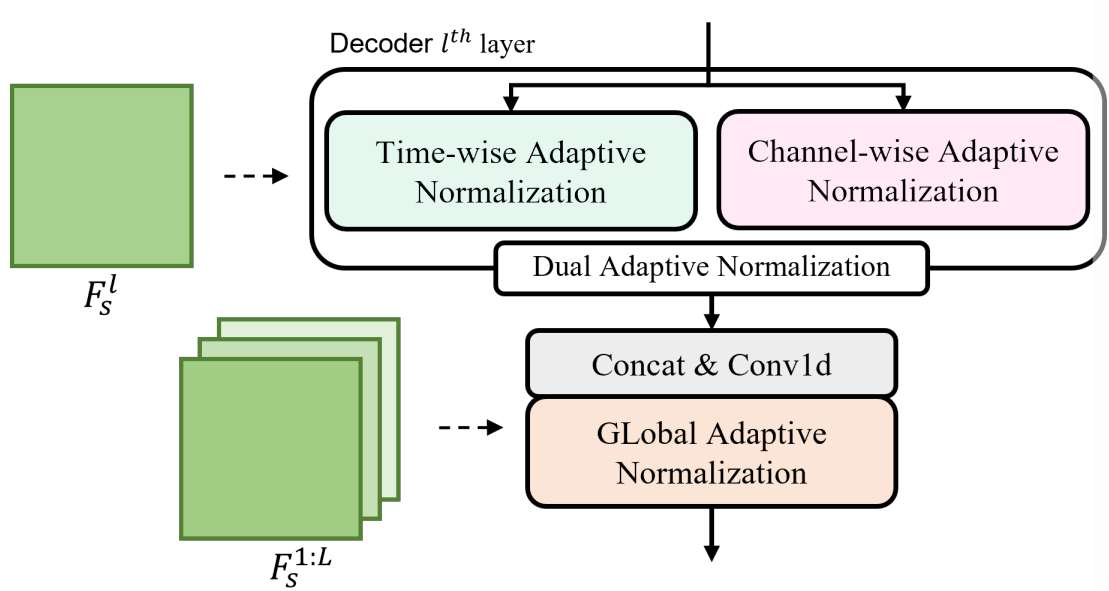
TriAAN Block 은 DuAN 과 GLAN 으로 구성되어 있다. 해당 블록은 각 $I$번째 speaker encoder layer 에서 수집된 feature map 을 사용하며, DuAN 은 이중 뷰(time, channel) $F_s^l$(speaker s의 l번째 레이어에서 추출한 특성 맵) 에서 layer 별 세부 speaker 특징을 추출하고 적응형 정규화를 수행한다.
특히 DuAN 은 이미지 스타일 전송에서 adaptive attention normalization 에서 영감을 받아 제작한 것으로, layer 별 화자 특징 $F_s^l$ 에 대한 통계를 만들어 낸다.(attention 기반) 이 때 지나치게 세부적인 화자의 특징으로 편향된 결과를 방지하기 위한 기법들 역시 사용된다.
반면 GLAN 은 speaker encoder 의 모든($F_s^{1:L}$) feature map 을 사용하여 global speaker 정보를 추출한다. 이는 추측하기론, 하나의 특정한 스피커 뿐만 아니라, 다양한 스피커들에 공통적으로 적용될 수 있는 목소리 특징을 포괄적으로 파악하는 것이라 생각한다. 이를 통해 특정 speaker 의 목소리 변환 뿐만 아니라, 보다 범용적인 다양한 speaker 에 적용 가능한 목소리 변환 모델 구축이 가능해 진다.
외에도 논문 2,3 페이지에서는 DuAN과 GLAN의 동작 원리를 상세하게 설명하고 있다.
3. EXPERIMENTS
3-1. Experimental setup
- dataset : VCTK
- train, validation, test : 6:2:2
변환 시나리오는 20명의 speaker 를 선택하고 See-to-Seen(S2S) Unseen-to-Unseen(U2U) 시나리오당 600쌍을 생성한다.
- Seen-to-Seen : 모델은 훈련 과정에서 두 스피커의 목소리를 모두 접했기 때문에 변환을 비교적 쉽게 수행할 수 있다.
- Unseen-to-Unseen : 모델은 훈련 과정에서 변환 대상인 두 스피커의 목소리를 전혀 접해보지 않은 상태이기에, 변환의 난이도가 매우 높다.
오디오 샘플링은 16kHz, 25ms 의 프레임 크기, 10ms 의 홉 크기, 80멜빈을 기반으로 한 CPC, f0, mel-spectrogram feature 를 추출한다.
- 훈련 세부사항
- batch size : 64
- epoch : 400
- optimizer : Adam
- learning rate : $10^{-5}$
- 모델 파라미터
- $H$ : 256
- $C$ : 512
- $L$ : 6
추가로 log mel-spectrogram 을 waveform 으로 변환하기 위해 VCTC 데이터 세트에서 사전 훈련된 parallel WaveGAN vocoder 를 사용한다.
3-2. Evaluation metrics
해당 논문에서는 평가를 위해 objective(객관적인) 방식과 subjective(주관적인) 방법을 모두 사용한다.
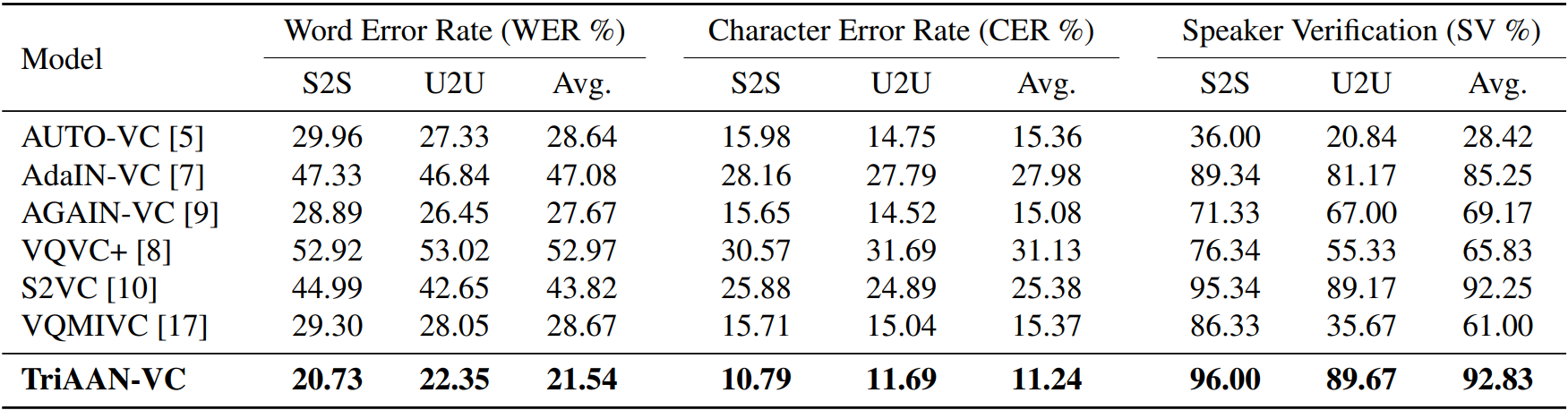
objective 한 방법으로는 WER와 CER을 통해 테스트한다. pre-trained 된 wav2vec 2.0 을 사용한다고 하는걸 보니, VC한 결과를 ASR 을 통해 다시 체크하는 방식이며, 화자 검증 모델(Speaker Verification) 에 기반하여 자체적인 합격률을 계산한다. 합격률은 변환된 음성과 target 음성간의 코사인 유사성, SV모델에 의해 추출된 임계값, VCTK 데이터 세트의 동일한 오류율을 기반으로 계산된다.
subjective 한 방법에서는 자연스러움, 유사성에 대해서 MOS 테스트를 실시한다. S2S 및 U2U 에 대해 무작위로 선택된 20쌍의 발화를 사용하여 테스트한다.
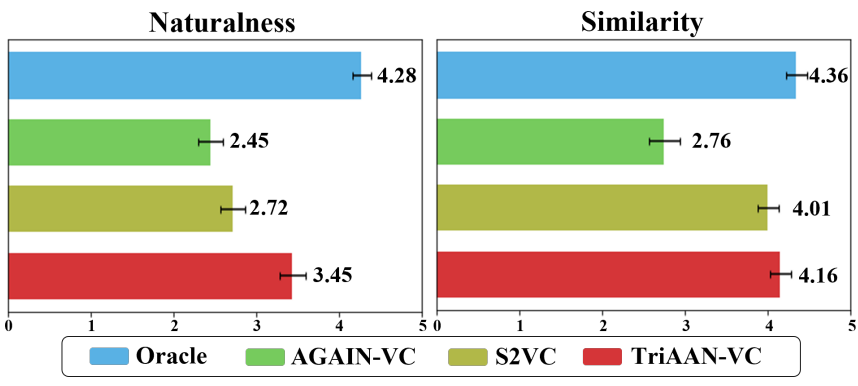
MOS 기준 자연스러움 - 3.45, 유사도 - 4.16 이라는 뛰어난 지표를 보여준다.
객관적인 평가 방법에서도 기존 모델들 대비해서 많은 성능 향상을 보여준다.
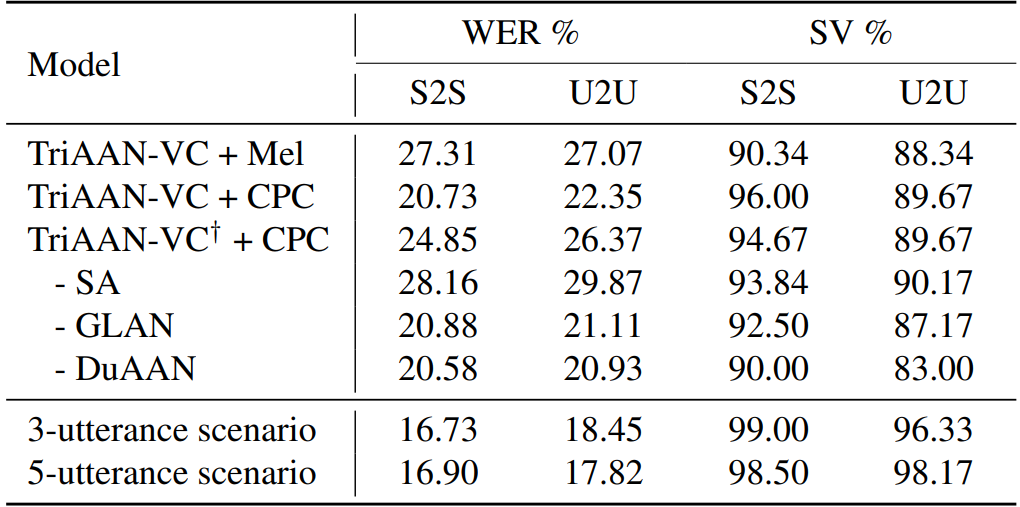
마지막으로 제공된 표 2 에서는 샴 손실이 얼마나 영향을 미치는지 확인할 수 있다.
4. 실제 모델 테스트 및 느낀점.
전반적인 테스트 결과는 아래와 같다.
한국어 기준이던, 영어 기준이던 미리 준비된 Vocoder 와 CPC 를 사용하는것 만으로 우수한 변환 성능을 보여준다. 하지만 기본적으로 '잡음 저항' 이 낮다. 한국어나 영어 음성 데이터를 제공하는 AI Hub, common-voice 데이터셋에는 가정 내 IOT 기기들로 녹음되어 제공된 음성들이 다수 존재하여 잡음이 섞인 경우가 잦다.
해당하는 데이터셋에서 잡음이 없고, 상대적으로 깔끔한 음성들은 성공적으로 변환되나, 그렇지 못한 음성들은 잘 변환되지 못하는 경향을 보여준다. 여기서 잡음은 정말 사람이 듣지 못할정도의 심각한 잡음이 아니라, 상대적으로 작은 노이즈, 음성이 다소 불분명하게 들리는 특정구간에 해당된다. 이는 이 모델의 가장 치명적인 문제점이다.
결국 현실적으로 충분히 사용할만 하지만, target 데이터의 잡음 여부에 매우 민감하기 때문에 신중히 데이터를 선정할 필요성이 있겠다.
위에서 저자들이 제시한 MOS, WER, CER 지표도 잡음이 거의 완벽에 가깝게 제거된 데이터로부터 나오는 지표이다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning (0) | 2024.03.31 |
|---|---|
| [리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.03.19 |
| [리뷰] HiFi-VC: High Quality ASR-Based Voice Conversion (0) | 2024.02.20 |
| [리뷰] Low-resource expressive text-to-speech using data augmentation (0) | 2024.02.18 |
| [리뷰] Make-A-Voice (0) | 2024.02.15 |