해당 논문은 Voice Conversion 모델중 하나인 HiFi-VC 를 제안하는 논문이다.
HiFi-GAN 을 기반으로 제작된 이 모델은 이전에 리뷰한 StarGANv2-VC 와 다르게 any-to-any 가 가능하다. many-to-many 의 경우 반드시 학습된 음성만 Target 으로 둘 수 있다.(학습되지 않은 target 으로 변환할 경우 품질이 심각하게 저하된다.) 반면 any-to-any 의 경우 훈련중 학습되지 않은 '모든' 화자로의 음성 변환을 목적으로 한다.
때문에 any-to-any 는 모델 학습적인 관점에서 many-to-many 보다 어렵지만 실제로 사용할 때는 더 유용하게 사용할 수 있다. Hifi-VC 모델은 이러한 any-to-any 가 가능한 모델로서 활용성이 높다.
1. Introduce
VC 의 경우 텍스트 정보와 운율을 유지하면서 한 화자의 음성을 다른 화자의 음성으로 변환한다. VC를 구현하는 가장 간단한 방법은 ASR과 TTS를 결합하는 것이다. 그러나 이러한 접근 방식을 사용하면 텍스트 병목 현상이 발생하여 운율에 대한 중요한 정보를 잃을 수 있다. 이러한 문제를 해결하기 위해 여러(entertainment, speakingaid systems, data augmentation, anonymization) 특수한 VC 알고리즘들이 제안되었다.
* 병목 특징(bottlenect feature) : ASR, VC 과정 중간에, 다양한 음향학적, 언어학적 특징을 추출하는 여러 겹의 신경망 계층들이 존재한다. 병목 특징은 이런 계층들에서 추출한 표현으로, 상대적으로 작은 크기(차원)를 가지면서 원래 음성의 중요한 정보가 압축되어 있다.

결국 지난 10년간 TTS와 VC를 포함해서 여러 음성 합성 방법서 상당한 진전이 존재했다. 대부분의 작업은 세 단계로 음성 변환을 수행한다.
- 입력 샘플에서 콘텐츠 및 speaker feature 를 추출한다
- 추출한 정보들로 spectrogram 을 생성한다.
- vocoder 를 통해 파형(waveform) 으로 변환한다.
다른 여러 모델에서 neural waveform encoders 와 decoders 를 사용하며, 일부 방법들은 input coding(입력 음성 신호를 특정 표현(features)으로 변환하는 과정) 을 위해 voice pitch feature 및 ASR 기능을 적용하며(StarGANv2-VC). 많은 접근 방식들이 GAN을 활용한다.
기본적인 접근 방법들은 단일, 또는 다수의 미리 정의된 화자들의 음성을 단일 대상 화자의 음성으로 변환한다. 화자 세트에서 음성을 변환할 수 있는, 소위 Many-to-Many 방법들을 사용한다. 그러나 이러한 방법들은 미리 준비된 음성 세트를 예측하는데는 탁월하나, 훈련에 포함되지 않은 음성을 변환할 수 없다.(낮은 품질로 생성은 가능하다. 저자들도 생성은 가능하다고 명시 해 뒀는데, 사실 아무 의미 없는 수준이다.)
결국 VC에 대한 가장 실용적인 방법은 훈련데이터 세트에 포함되지 않은 임의의 음성으로 변환하는 것이다. 이 접근법은 any-to-any 또는 zero-shot 음성 변환이라고 지칭한다.
결론적으로 해당 논문에서는 아래와 같은 사항을 이야기한다.
- 논문에선 중간 feature에서 waveform을 직접 예측할 수 있는 새로운 조건부 GAN 아키텍처를 제안한다.
- 논문에선 ASR 기반 콘텐츠 인코딩의 아이디어를 GAN 생성 접근 방식과 결합하여 고품질의 any-to-any VC를 달성한다.
- 논문에선 객관적인 평가를 사용하여 제안된 방법을 비교한다. 실험에 따르면, 제안된 방법은 더 높은 음성 품질과 유사성(target) 을 달성한다.
2. Related Works
해당 섹터에서 VC 에 관해 전반적으로 유용한 많은 정보가 기재되어 있기에, 생략을 최소화 하였다.

음성 특징을 변경하려면 source sample 에서 화자에 구애받지 않는 콘텐츠 정보를 추출할 필요가 있다.
대부분의 방법들은 auto-encoder, variational auto-encoder 등을 기반으로 하고, 병목 계층을 사용하여 잠재 공간에서 화자정보를 제거하는 방식을 사용하기도 하며(병목계층을 거치며 운율 데이터가 사라지는 문제가 있지만, 화자 정보를 분리할 수 있다는 장점이 있다), 여기서 화자와 콘텐츠의 특징 분리를 개선하기 위해 추가적인 normalization layers를 추가하는 등 여러 방법을 사용한다.
또한, 많은 방법들은 ASR 모델을 사용한다. 일부는 언어 정보를 주출하기 위해 ASR을 통해 음소 확률을 적용하는 반면, 일부는 병목 특징을 활용한다. 병목 특징을 활용하는 방법의 경우, 병목 특징이 소스 화자에 대한 정보를 거의 포함하지 않는다는 것이 경험적으로 관찰되었다.
ASR의 또 다른 사용은 변환 중 언어 정보의 손실을 최소화하는 훈련 목표를 설계하는 것이다. ASR 기반 정보추출의 한 가지 단점은 운율 특징을 인코딩할 수 없는 ASR의 무능력이다.(당연히 content 정보 뽑을려고 쓰는거니 운율은 인코딩 못한다.) 이 문제를 처리하기 위해 소스 샘플에서 F0 를 추출한다. 화자 정보는 일반적으로 정규화(normalization)에 의해 F0에서 제거된다.(왜 StarGANv2-VC 에서 추가적인 ASR 모델과 F0 모델이 필요한지 알 수 있다.)
저자들의 방법은 TTS Skins와 유사한 ASR 및 F0 인코더를 사용하며, F0는 BNE-Seq2seqMoL에서와 유사한 네트워크에 의해 추가로 전처리된다.
콘텐츠 및 스피커 특징이 주어지면 대부분의 다른 방법들은 예측을 디코더와 보코더의 두 단계로 분해한다. 디코더의 목표는 출력 신호의 mel-spectrogram 을 예측하는 것인 반면 보코더는 예측된 spectrogram을 출력 파형으로 변환한다. 디코더는 RNN, Transformer 또는 FCN(fully convolution architecture)을 통해 구현될 수 있다. 인기 있는 보코더에는 STRAIT, Griffin-Lim 및 WaveGlow 및 HiFi-GAN과 같은 신경망 모델이 포함된다. 신경 접근 방식으로 더 나은 품질을 달성하려면 디코더 훈련 후에 추가 보코더 미세 조정 단계가 필요하다.
반면 HiFi-GAN 은 디코더만 사용한다. ASR 및 GAN 기반의 다른 모델과는 달리 중간 mel-spectrogram 예측 단계를 피하고 인코딩된 특징에서 직접 파형을 생성한다. 이러한 방법은 스피커 임베딩이 음성 변환에 영향을 미치는 방식이 다르다. 대부분의 다른 모델에서는 speaker 임베딩이 spectrogram 예측을 위해 decoder에 사용된다. 하지만 저자들의 방식은 생성 중에 스피커 임베딩으로 GAN 잔차 블록을 직접 조절한다. 이러한 접근 방식은 별도의 보코더를 제외하고 변환 파이프라인을 단순화한다. 따라서 이러한 방법은 디코더 훈련 후 보코더 미세 조정 단계가 필요하지 않다. VCRSS 및 NVC-Net과 같은 일부 이전 모델들도 별도의 보코더 사용을 피한다. 다만 해당 논문에선 VCRSS와 달리 더 나은 파형 예측을 위해 GAN 디코더를 사용한다. 이러한 저자들의 접근 방식은 ASR 인코더와 다른 GAN 아키텍처를 사용하기 때문에 NVC-Net과도 다르다.
3. Proposed Method
결국, 저자들이 제안하는 방식인 HiFi-VC 는 위의 그림 1과 같이 추가적인 화자의 embedder 가 있는 encoder-decoder 아키텍처를 기반으로 한다. 이러한 접근 방식은 TTS Skins, NVC-Net, BNE-Seq2seqMoL 에 영감을 받았다.
3-1. Model Architecture.
모델 아키텍쳐는 4가지로 요약할 수 있다.
- Linguistic encoder : 해당 인코더의 목표는 Source 음성 샘플로부터 Speaker 에 구애받지 않는 content 정보를 추출하는 것이다. 이를 위해 ASR 모델의 병목 현상을 활용하므로, TTS Skins 의 접근방식을 기반으로 한다. 최종적으로, NVIDIA 에서 제공해 주는 Pre-trained 된 Conformer 모델(Conformer-CTC) 을 사용한다. 이렇게 사전 학습된 ASR을 사용하면 ASR의 표현이 특정 VC 데이터 세트와 독립적이기 때문에 학습속도를 높일 수 있을 뿐만 아니라, 일반화도 개선할 수 있다.
- F0 encoder : 결국 '언어(Linguistic) 인코더' 는 ASR 역할을 수행한다. 위에서도 언급했듯 이러한 ASR 은 Content 정보는 잘 뽑아내지만 운율을 포착 하는데에는 문제가 있다. 이러한 한계를 극복하기 위해 BNE-Seq2seqMoL any-to-many 접근법과 유사한 F0 예측기를 추가한다.
- Speaker embedder : any-to-any VC 작업은 speaker embedder 네트워크를 사용해야 한다. 이러한 speaker embedder 는 5개의 layer 의 residual fully-connected network 를 사용하여 오디오 샘플에서 화자의 특징 벡터 분포를 예측한다.
- Decoder : 저자들이 제안한 Decoder 방식은 GAN 기반 방식을 확장한다. 기존에 다른 방법들에서 사용하는 방법은, 최종 디코딩을 위한 보코더로 HiFi-GAN 을 확장해서 사용한다.(보코더의 목표는 mel-spectrogram 을 waveform 으로 변환하는 것). 즉 이전 방식에선 디코딩을 위한 보코더가 따로 있고 보코더에서 나온 출력물을 가지고 Decoding 하는 Decoder가 따로 존재했었다는 것이다. 하지만 HiFi-VC 에서는 이러한 모듈을 '하나의 모듈' 로 결합한다. 때문의 그림 2 를 보면 별도의 Vocoder 가 존재하지 않는 모습을 살펴볼 수 있다.
3-2. Training Objectives
훈련중에는 ASR 모델을 동결하고(아마 pre-trained 를 무조건 사용하는 형태의 설계일듯), F0 encoder, speaker embedder, decoder network 및 GAN discriminator 를 동시에 최적화한다. 이를 HiFi-GAN과 NVC-Net의 speaker embedder 정규화(regularization) 손실을 결합하여 수행한다. 결국 이러한 방법을 사용했을 때 중간 mel-spectrogram 표현을 사용하지 않는다!(spectrogram 과 mel-spectrogram 은 다르다!)

원래 TTS 던 STT 건 보통 encoder-decoder 구조로 구성되어 있다. 위의 이미지는 TTS의 예제인데, 중간에 mel-spectrogram 표현을 vocoder 측에서 입력으로 받는 모습을 확인할 수 있다.
STT 도 마찬가지로 encoder 에서 mel-spectrogram 형태의 출력값을 내보내고, 이를 decoder 에서 받아 최종적인 text 로 출력하는 것이다.
마찬가지로 VC도 같은 매커니즘을 이용하기에 왠만한 모델들이 중간형태인 mel-spectrogram 을 만들어 처리한다. 하지만 저자들이 제안한 HiFi-VC 는 vocoder 와 decoder 를 합쳐 decoder 로 통합했기 때문에 이러한 mel-spectrogram 이 필요가 없다.
이미지를 함께 보면서 세부 손실 함수 항목들에 관해서 파악해 보자.
본래의 HiFi-GAN 과는 달리, 예측된 음성 샘플의 spectrogram 간 reconstruction loss 를 계산한다.
$$\mathcal{L}_{Rec} = ||\mathbf{M}_{source} - \mathbf{M}_{pred}||_1$$
- $||...||_1$: L1 Norm(Manhattan distance)을 의미. 벡터의 각 요소 간 절댓값 차이의 합을 계산.
- $M_{source}$ : 원본 음성의 spectrogram
- $M_{pred}$ : 예측 음성의 spectrogram.
HiFi-GAN 은 GAN 인 만큼 적대적 손실을 사용하여 예측 파형(HiFi-GAN 이 생성한 waveform)을 자연 파형(인간이 녹음한 waveform)과 구분할 수 없게 만든다.
예측 변수 최적화에 사용되는 손실은 아래와 같이 정의된다.
$$\mathcal{L}_{AdbP}(s) = (D(s)-1)^2$$
- $s$ : 예측파형(예측된 waveform)
- $x$ : 자연파형(실제 인간의 waveform)
- $D$ : 판별 네트워크
- $D(s)$ :판별자의 출력이기도 하며, 파형 $s$ 를 판별자가 평가한 값이다.
- \mathcal{L}_{AdbP}(s) 가 1에 가깝다면 생성된 데이터, 0에 가깝다면 진짜 데이터로 판단한다.
과정을 정리해 보면
- 판별자 $D$는 예측된 음성파형 $s$를 입력으로 받는다.
- 판별자 $D$는 해당 파형이 진짜인지 가짜인지 판단해서 확률값을 출력한다.($D(s)$)
- 예측기는 이 $D(s)$ 값이 커지도록(즉, 실제 데이터로 판단되도록) 한다.
- 수식에서 $(D(s) -1)^2$ 를 계산하기에 $D(s)$ 는 1에 가까울수록 adversarial loss 는 최소화된다.
Discriminator 최적화를 위한 손실은 아래와 같이 정의된다.
$$\mathcal{L}_{AdbD}(s, x) = (D(x)-1)^2 + (D(s))^2$$
과정을 정리하면
- 첫 번째 항 $(D(x) - 1)^2$ : 자연 파형 'x' 에 대한 판별 오류를 나타낸다.
- $D(x)$ 가 1에 가까울수록(판별자가 'x' 를 진짜라고 판단할수록) 이 항은 0에 가까워진다.
- $D(x)$ 가 1에서 멀어질수록(판별자가 'x'를 진짜라고 판단하지 못할수록) 이 항은 커진다.
- 두 번째 항 $(D(s))^2$ : 예측 파형 's' 에 대한 판별 오류를 나타낸다.
- $D(s)$가 0에 가까울수록(즉, 판별자가 's'를 가짜라고 판단할수록) 이 항은 0에 가까워진다.
- $D(s)$가 0에서 멀어질수록(즉, 판별자가 's'를 진짜라고 판단할수록) 이 항은 커진다.
- 두 항을 더하여 Discriminator의 최적화 목표를 정의한다.
- Discriminator는 자연 파형 'x'를 가능한 한 진짜라고 판단하고(첫 번째 항 최소화)
예측 파형 's'를 가능한 한 가짜라고 판단하도록 학습된다(두 번째 항 최소화). - 결과적으로, Discriminator는 자연 파형과 예측 파형을 효과적으로 구별하는 능력을 향상시키게 된다.
- Discriminator는 자연 파형 'x'를 가능한 한 진짜라고 판단하고(첫 번째 항 최소화)
더하여 GAN 에 대한 훈련은 feature matching loss 를 통해서 안정화 할 수 있다(GAN은 훈련이 불안정하다.) $i$번째 Discriminator layer 의 출력을 $Ni$ 차원 백터 $Di$ 라고 가정하면 아래와 같이 계산할 수 있다.
$$\mathcal{L}_{FM}(s, x) = \sum_{i=1}^T{1 \over N_i} || D_i(x) - D_i(s) ||_1$$
위에서 NVC-Net 의 손실을 결합하여 사용한다고 언급했었다. 이와 유사하게 speaker embedding 정규화(regularization)손실도 존재한다. reference record $r$ 이 있다고 가정하고, 임베딩에 의해 예측된 평균 및 대각 공분산 행렬을 $\mu(r)$ 및 $\sum(r)$ 로 정의하면 정규화 손실은 아래와 같이 정의될 것이다.
$$\mathcal{L}_{Spk}(r)=D_{KL}(\mathcal{N}(x;\mu(r), \sum(r) || \mathcal{N}(x;0,I))$$
최종적으로, $\mathcal{L}_P$ 의 최종손실은 위의 모든 손실을 더하면 된다.
$$\mathcal{L_P} = \lambda_{Rec}\mathcal{L}_{Rec} + \lambda_{AdbP}\mathcal{L}_{AdbP} + \lambda_{FM}\mathcal{L}_{FM} + \lambda_ {Spk}\mathcal{L}_{Spk}$$
- $\lambda$ : 각 손실값을 조정하는 hyper-parameter.
저자들은 $\lambda$ 값으로 $\lambda_{Rec} = 45$, $\lambda_{AdvP}=1$, $\lambda_{FM} = 1$, $ \lambda_{Spk} = 0.01$ 을 사용하였다고 한다.
3-3. Implementation Details
해당 섹터에서는 여러 구현하는데에 있어 부가적인 내용들을 설명하고 있다.
- 훈련중 모든 음성 샘플은 24kHz 로 변환된다.
- ASR은 40ms 주기로 특징을 생성한다.
- F0 예측기는 10ms 마다 특징을 생성한다.
등등 세부적인 여러 내용에 대해서 이야기하고 있다.
4. Experiments
해당 링크에서 HiFi-VC 의 성능을 체험해 볼 수 있다.
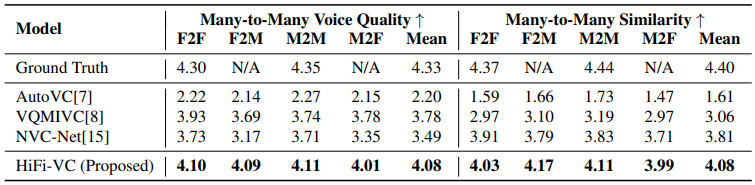
기본적으로 다른 방법들 대비 높은 점수를 보여준다. 하지만 나는 HiFi-GAN 의 핵심은 any-to-any 라고 생각해서 사실 many-to-many 방법에 관해서는 큰 관심이 없다.
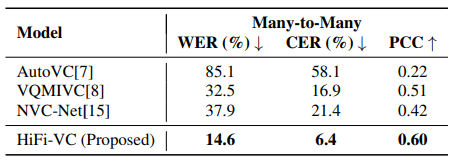
그리고 asr 을 통해서 생성된 음성의 정확도를 평가하는데, 다른 방법들 대비해서 월등히 높은 지표를 보여준다. asr의 경우 훈련용도로 사용된 pre-trained conformer-ctc 가 아닌 다른 asr 을 사용하였다고 하는데 뭘 사용했는지는 자세히 적혀있지 않다.
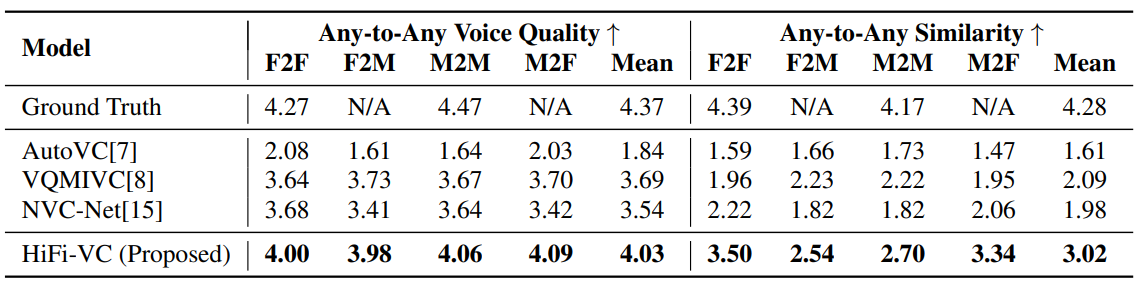
여담으로 many-to-many 부분에서 좀 이상한게, StarGANv2-VC 에 대한 비교표를 왜 작성하지 않았을까... 생각 해 보면 아마 StarGANv2-VC 의 성능이 더 우수해서 그렇지 않을까? 하는 의심이 든다. 데모 링크에 가면 StarGANv2-VC 에 대해서 테스트를 진행한 흔적이 보이지만 위 결과표에는 포함되어 있지 않은걸로 봐서는 아마 저자들이 원하는 결과가 도출되지 않아서 StarGANv2-VC 를 배제 하였다고 생각한다.
5. Conclusion.
매우 고무적인 성능을 보여준다.
다만 한국어 VC 기준, 내장되어 있는 Linguistic encoder, F0 encoder가 영어에 맞게끔 훈련되어 있기에 VC 작업을 진행하면 마치 외국인이 이야기 하는것 처럼 말투 자체가 변해버린다. 영어와 영어간 변환을 수행하면 상당히 비슷하지만, 그래도 many-to-many 방식인 StarGANv2-VC 만 못한것이 사실이다.(물론 StarGANv2-VC 는 any-to-any 가 불가하다는 결함이 있다) 데모에서는 상대적으로 StarGANv2-VC 가 더 안좋게 들리나, 실제 결과가 그렇다면 표 1에 결과를 첨부하지 않을 이유가 없었을 텐데 넣지 않은 이유가 있을것이다.
그래서 나는 Linguistic encoder, F0 encoder 를 한국어용으로 변경해서 테스트 해 보려 하였으나, 아쉽게도 학습에 관련된 소스코드가 공개되어 있지 않아서 이미 완성된 모델을 사용만 할 수 있다.
결론적으로, 나는 HiFi-VC 를 매우 우수한 성능을 지닌 모델이라고 인식하며, 추가로 학습시간도 합리적이라고 생각한다.(저자들의 학습시간은 단일 GPU로 70분씩 120 epoch) 한번 직접 학습시켜보고 이것 저것 커스텀 해 사용해 보고 싶었는데 아쉬운 상황이다. github 를 뒤져보니 어떤 서약 때문에 훈련모델을 공개하지 못하는 듯 하다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.03.19 |
|---|---|
| [리뷰] TRIAAN-VC (0) | 2024.02.23 |
| [리뷰] Low-resource expressive text-to-speech using data augmentation (0) | 2024.02.18 |
| [리뷰] Make-A-Voice (0) | 2024.02.15 |
| [리뷰] Conformer (0) | 2024.01.22 |