
해당 논문은 LoRA 를 개선한 버전인 AdaLoRA 에 대해 제안하는 논문이다.
1. 서론
기존 Full Fine-Tuning, LoRA 는 NLP 에서 중요한 패러다임이 되었으나, 일반적으로 '모든' parameter 를 미세 조정하기에 최적의 조정을 수행할 수 없다는 단점이 있다.
이러한 문제를 해결하기 위해 가중치 행렬 간 parameter 자원(budget) 을 중요도 점수에 따라 적응적으로 할당하는 AdaLoRA 를 제안한다. 특히 AdaLoRa 는 특이값 분해(Singular Value Decomposition, SVD)의 형태로 증분 업데이트를 parameter 화 한다. 이러한 접근 방식을 통해 중요하지 않은 업데이트의 특이값을 효과적으로 가지치기할 수 있으며, 이는 본질적으로 parameter 의 필요 자원을 줄이는 역할을 할 수 있다.
마지막으로 논문에서는 AdaLoRA 의 효과를 검증하기 위해 여러 광범위한 실험을 수행한다. 특히 AdaLoRA 가 저예산 환경에서 매우 큰 개선을 보여준다는 점을 확인할 수 있다.
2. 소개
논문 저자들은 모든 가중치 행렬을 업데이트 하는 것 보다 일부 가중치 행렬만 수정하는것이 더 높은 성능을 달성한다는것을 발견하였다.

이는 모든 가중치 행렬을 조정하는것이 최적이지 않다는 것을 의미한다. 즉 optimal 하지 않다. 그렇다면 어떤 가중치 행렬, 어떤 레이어를 선택해야지 가장 optimal 한 업데이트를 수행할 수 있을까?
즉.
모듈의 중요도에 따라 parameter 의 자원을 적응적으로 할당 할 수 있을까?
이 질문에 대한 답으로 저자들은 AdaLoRA 를 제안한다.
AdaLoRA 는 자원을 제어하기 위해 incremental matrices(증분행렬) 의 rank 를 조절한다. 중요한 증분행렬이라면 보다 세분화된 작업별 정보를 잘 캐치할 수 있도록 높은 rank 로 할당된다. 반면 덜 중요하다면 과적합 예방, 및 예산을 절약하기 위해서 낮은 rank로 할당할 수 있다.
기존 연구에서는 행렬의 rank를 제어하는 여러 방법들이 제안되었으며, 대부분은 행렬의 특이값 분해(SVD)를 직접 계산하여 가장 작은 특이값을 가지치기한다. 이러한 연산은 rank를 명시적으로 조작할 수 있게 만들며, 결과 행렬과 원래 행렬 간의 차이를 최소화한다.
그러나 대규모 모델을 미세 조정할 때는 이러한 연산이 고차원 가중치 행렬에 대해 반복적으로 SVD를 적용하는 것이 매우 비효율적이다.(SVD의 연산량은 정사각 행렬일 경우
이런 파라미터화를 통해 SVD의 계산량이 많은 부분을 피할 수 있고, 또 다른 이점으로 중요하지 않은 특이값을 감소시키면서도, 그렇지 않은 벡터는 유지시킬 수 있기에 전체적인 훈련과정을 안정화 시킬 수 있다.
결론적으로 AdaLoRA 는 SVD를 모방한 방식을 기반으로한 새로운 LoRA 방법으로, 가중치 행렬
2-1. SVD
SVD는 선형대수학에서 중요한 계념중 하나이다. 임의의 행렬을 특정 구조의 세가지 행렬의 곱으로 분해하는것을 말한다. 이는
이다.
참고로 여기서 중요하게 여겨지는 성질이 아래와 같다.
이 성립한다. (이 원리를 이용해 AdaLoRA 에 핵심적인 원리가 구동된다.)
이러한 SVD 기술을 사용함으로서 AI 분야에서는 아래와 같은 장점을 얻을 수 있다.
- 데이터 압축, 차원 축소
- 잠재 의미 분석
- 모델 파라미터 정규화
- 네트워크의 복잡도 감소
특이값 분해(SVD) - 공돌이의 수학정리노트 (Angelo's Math Notes)
angeloyeo.github.io
최종적으로 SVD는 임의의 행렬 A를 정보량에 따라 여러 layer로 분할하기 위해서 사용된다.
3. AdaLoRA Method
3-1. SVD-Based Adaptation
위에서 언급된 바와 같이, AdaLoRA 는 pre-trained 가중치 행렬의 증분 업데이트를, 특이값 분해 형태로 매개변수화 한다.
이는 LoRA와 비교시
사전 훈련된 가중치 행렬의 업데이트를 제한하기 위해, row-rank 분해를 로 표현한다. 여기서 각 기호는 다음과 같은 의미를 지닌다. , , 그리고 rank 은 값을 가진다.
훈련중는 동결되며, 기울기 업데이트를 받지 않는다. 반면 는 trainable parameters 이다. 와 는 모두 동일한 입력값으로 곱해진다.
따라서 LoRA 는 아래와 같은 수식을 지닌다.
여기서
그냥 고전적인 LoRA 에서
이 질문에 대해서 저자들은 아래와 같이 답변한다.
- 만약
반면 AdaLoRA 는
더하여 SVD를 계산하기 위해 모든
이를 통해 점진적으로 업데이트 해 가며 SVD와 비슷한 효과를 낼 수 있다.
직교 행렬은 전치 행렬과 곱하였을때 항등행렬인
직교행렬의 전치행렬은 역행렬과 같다. 따라서
더하여 '더 작아질수록' 이라는 말에 집중해 보면, 결국 필요없는 부분을 '점진적으로' 제거해가며 이 최종 값을 작아지도록 만들 수 있는 것이다.
3-2. Importance-aware Rank Allocation
위에서
LoRA 와 비교해서
저자들은
최종적으로 아래와 같은 수식을 통해 스탭
아래는 수식에 대한 직접적인 설명이다.
아래는 수식에 대한 참고 내용이다.
- 중요도 점수를
- 매개변수 집합
- 정규화과정(
아래 수식은 특이값 분해에서 행렬
이하 수식에 대한 설명은 아래와 같다.
이를 통해 중요도가 낮은 정보는 제하고, 중요한 특성을 갖는 특이값을만 보존하여 다음 단계의 훈련에 사용함으로서, 계산 효율성을 높이는데 도움을 준다.
최종적으로 AdaLoRA 는 아래와 같은 과정을 따른다.
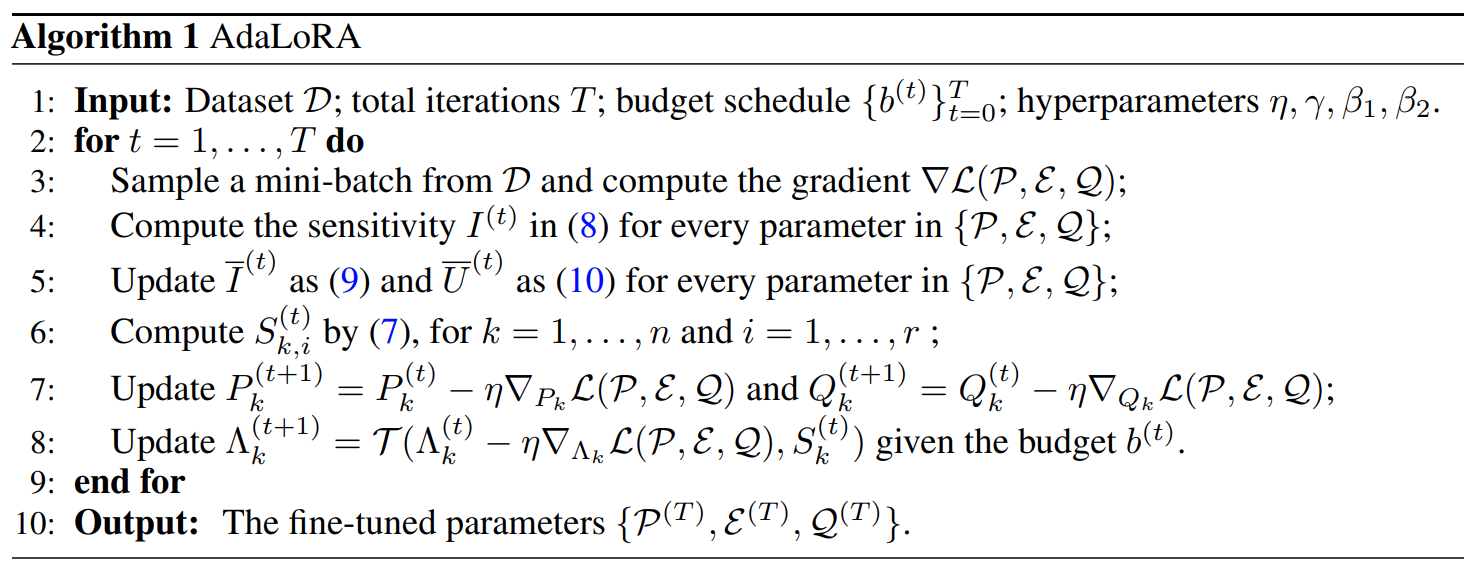
간단히 요약하면 아래와 같다.
, 는 각각 민감도(파라미터가 얼마나 민감한가, 작은 변화가 얼마나 큰 영향을 미치는가(다만 지수이동 평균을 통해 smoothing 되어있음))와, 정량화된 불확실성( 와 사이의 국부적 변동에 의해 정량화된 불확실성, 민감도의 추정치가 얼마나 정확한가, 불확실성이 높다면 민감도 추정치를 조심히 다뤄야함)을 의미함.
- 데이터셋에서 미니배치 샘플링, 해당 배치에 대한 기울기를 계산.
- 파라미터에 대해 민감도, 중요도를 갱신한다.
- 이를 통해
- 이를 반복-파라미터를 조절한다.
- 최종적으로 미세 조정된 파라미터를 출력한다.
결국, LoRA 와 AdaLoRA 의 차이는
AdaLoRA 는 중요도를 기반으로 가중치를 업데이트 할 수 있다. LoRA 는 모든 파라미터에 대해 동일 업데이트 적용하지만 AdaLoRA 는 특이값의 중요도를 평가하기에, 더 중요한 파라미터에 더 많은 '자원(budget)' 을 할당할 수 있으며, 상대적으로 중요하지 않은 파라미터의 가중치 행렬을 점진적으로 제거하여 과적합 방지, 일반화 성능 향상 등에 기여한다.
3-3. Global Budget Scheduler
rank 를 조정하는 이유는, low-rank adaptive 맥락에서 매개변수의 예산을 제어하기 위해서이다. 이러한 예산의 조절은 미세 조정중 반복적으로 수행되며, 논문 내에서는 교육을 용이하게 하기 위해 Global Budget Scheduler 를 제안한다.
목표 예산
이러한 방식을 통해 AdaLoRA 는 먼저 매개변수 공간을 탐색한 다음, 나중에는 가장 중요한 가중치에 집중할 수 있다.
4. Experiments
이렇게 구현된 AdaLoRA 에 대한 테스트 결과를 보여주는 섹션이다.
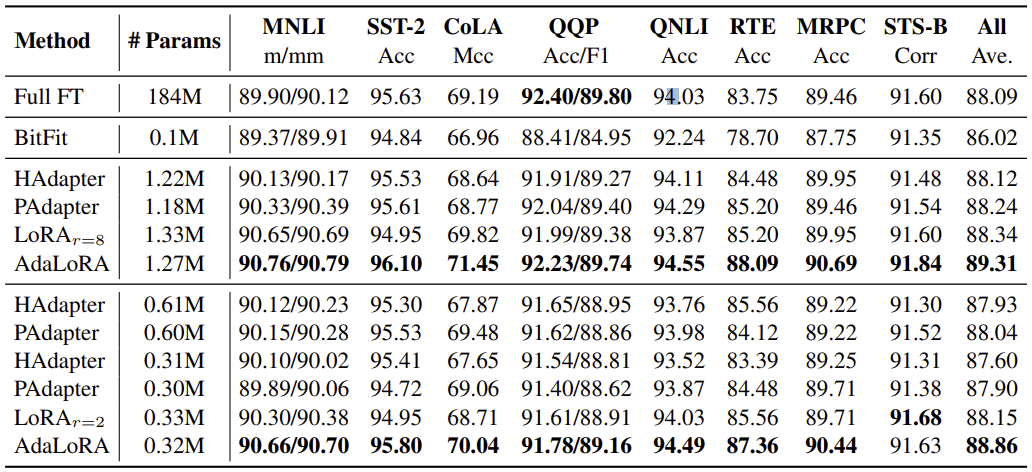
위 표에서 중요한건 Full FT 와 LoRA, 그리고 AdaLoRA 간의 성능 비교이다. 단발적으로 테스트한것이 아닌 무작위 seed 의 5번 실행의 평균을 보고하고 있다. 전반적으로 거의 모든 경우에서 AdaLoRA 가 가장 우수한 결과를 보여주는 모습을 확인할 수 있다.
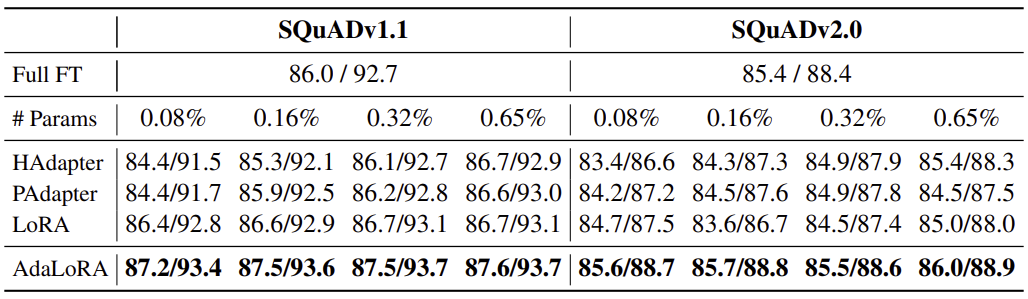
기본적으로 Params 를 늘린다고 극적인 성능변화는 존재하지 않지만, 그래도 미세하게 성능이 상승하긴 한다.
더하여 모든 params 에서 Adapter, LoRA 대비 항상 우수한 성능을 보여준다는 것도 확인할 수 있으며, Fine-Tuning 대비 우수한것도 마찬가지이다.
5. 마치며
AdaLoRA 는 아마 또다른 혁명이 되지 않을까? 한다. 아쉽게도 나의 수학적인 지식이 부족해 원리를 근본까지 이해하진 못 했지만, 그 효과는 충분히 체감할 수 있었다. 개인적으로 진행하는 연구에 적용해 본 결과, 성능이 Fine-Tuning 은 물론이고 LoRA 를 상회하였으며, 저자들이 논문에서 지나가듯 언급한 '과적합 예방' 효과도 확인해 볼 수 있었다.
전반적으로 Fine-Tuning 대비 성능도 높게 뽑히고, 메모리도 적게 먹고... 대단히 좋은 기술이 아닌가 한다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] A Comprehensive Evaluation of Quantization Strategies for Large Language Models (2) | 2024.09.29 |
|---|---|
| [리뷰] QWEN TECHNICAL REPORT (0) | 2024.06.14 |
| [리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.03.19 |
| [리뷰] TRIAAN-VC (0) | 2024.02.23 |
| [리뷰] HiFi-VC: High Quality ASR-Based Voice Conversion (0) | 2024.02.20 |