해당 논문은 Alibaba Group 내 Alibaba Cloud 가 구축한 Open LLM 인 Qwen 의 기술 리포트 이다.
이 모델에 관심을 가지게 된 계기는 몇몇 중국 기업, 특히 알리바바에 관심이 있어서가 첫째이고,
최근 나온 Qwen 2.0 의 성능이 GPT 4 에 근접한 성능지표를 보여주었기 때문이다.
실제로 모델을 사용 해 보았을 때 한국어 기준 LLaMA3 보다 더 우수하다고 느꼇다.
더 과감하게 발언하자면,
24년 6월 기준 모든 Open LLM 기준, Qwen 2.0 의 성능이 가장 우수하다.
모든 LLM 으로 범위를 넓히면, Qwen 2.0 보다 더 우수한 성능을 보유하다고 느낀 모델은 GPT-4o 가 유일하다.
참고로 해당 논문은 Qwen 2.0 모델에 관해 설명하는것이 아닌,
시초가 된 Qwen 1 모델에 관해 설명하고 있으며
설계적인 관점에서 상세하게 설명하고 있지는 않다.
논문 자체도 비교적 쉽게 작성되어 있기에, 한번 직접 읽어보는걸 추천한다.
해당 리뷰는 가볍게 훑고 요약하는 느낌으로 작성 하였다.
1. 소개

- Qwen : 수조 개의 토큰이 포함된 대규모 데이터세트로 Pre-Trained 한 모델
- Qwen-Chat : Qwen을 기반으로 SFT(Supervised Fine-Tuning)하여 제작된 모델
- Qwen-RLHF : Qwen을 기반으로 RLHF(Reinforcement Learning from Human Feedback)하여 제작된 모델
- Qwen-Code : 코딩관련 데이터를 추가하여 개발된 모델
- Math-Qwen-Chat : 수학관련 데이터를 추가하여 SFT된 모델
- Qwen-VL : multimodal LLM 으로서 학습된 모델
여러가지로 요약해서 모델을 설명하고 있다. 전반적으로 GPT-4 대비해서는 성능이 뒤쳐진다는 것을 논문 저자들도 인정하고 있으며, Math-Qwen-Chat 모델의 성능은 GPT-3.5 수준이라고 밝혔다. Qwen-VL, Qwen-VL-Chat 은 당시의 오픈소스 비전 언어 모델보다 성능이 뛰어나다.
2. 사전학습(Pre-Trained)
여러 기존 연구에서 데이터의 양은 강력한 LLM을 개발하는데에 매우 중요한 요소임이 입증되었다. 따라서 효과적인 사전학습 데이터셋을 구축하기 위해서, 데이터가 다양하고 광범위하게 존재하는지 확인해야 한다.
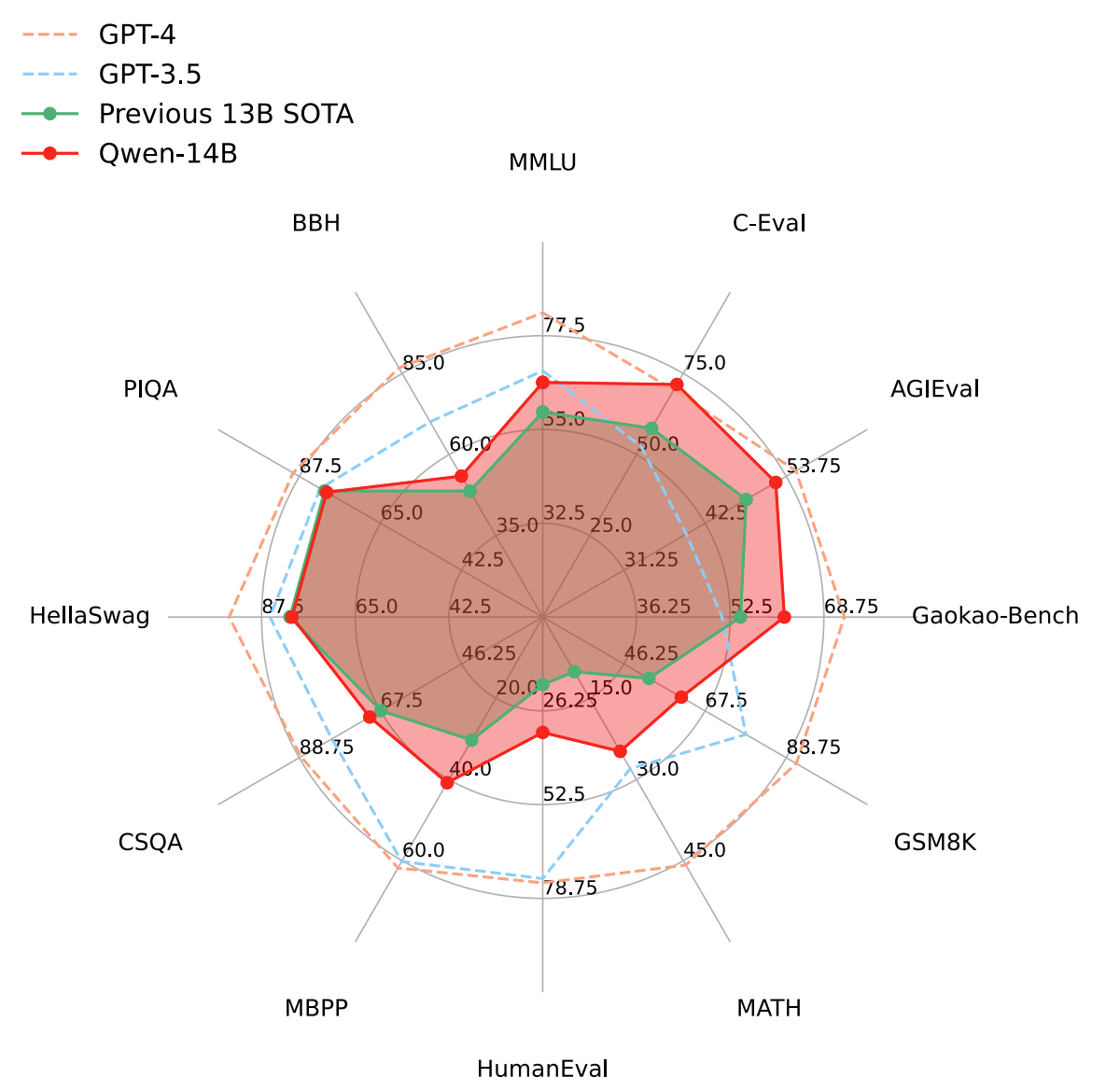
위는 Qwen-14B 와 GPT 4, 3.5 간의 성능평가를 진행한 결과이다. 14B 모델인 점을 감안해도 성능적으로 꽤나 떨어지는 모습을 보여진다. 이러한 Qwen 을 학습하는데에 있어 저자들은 데이터세트를 공개된 웹 문서, 백과사전, 책, 코드 등을 중국어와 영어 데이터 위주로 수집하였으며, 수집된 데이터를 여러 전처리 절차를 거쳐 처리하였다.
또한 인코딩 압축률에 있어서 타 모델대비 큰 개선을 이루었다고 한다. 참고로 인코딩 압축률 개선은 GPT 역시 GPT4o 에 와서 큰 개선을 이뤘기에, 이러한 Qwen 의 능력은 현재 기준으로 그다지 '특출난' 수준은 아닐것으로 추측된다.
더하여 Qwen 의 구조에 관해 설명하고 있다. Qwen은 Transformer 구조를 수정해서 설계되었으며, 특히 LLaMA 를 훈련하는 접근 방식을 채택하였다고 한다.
Qwen 1 모델은 최대 14B 규모로 학습되었다. 여러 Hyper-Parameters를 확인할 수 있다.
OPEN LLM 기준 비슷한 파라미터를 보유한 Open LLM 기준 성능은 Qwen 1 이 가장 우수하다.
3. 정렬(Alignment)
더하여 최초 사전학습된 LLM 은 인간의 행동과 정렬(aligned) 되지 않기에 대부분의 경우 AI 비서 역할을 하기에 부적합하다. 논문 작성 다시 연구에 따르면 SFT 나 RLHF 의 강화 학습과 같은 정렬 기술을 사용하면 언어 모델이 자연스러운 대화에 참여할 수 있는 능력을 크게 상승시킬 수 있다.
3.1 Supervised Fine-Tuning
첫 번째 단계는 SFT를 수행하여 인간의 행동을 이해하고 질의와 응답을 포함한 채팅 스타일의 데이터에 대해 사전 훈련된 LLM을 미세 조정하는 것이다. 이는 대화에 주석을 다는 방식으로 달성되었으며 폭력, 편견, 포르노 등과 같은 안전 문제와 관련된 데이터에도 주석을 달아 모델의 안전성을 우선시하였다.
3.2 Reinforcement Learning From Human Feedback
더하여 SFT가 효과적인 것으로 입증되었지만, SFT의 일반화 및 창의성 능력이 제한적일 수 있고 과적합되기 쉽다. 이 문제를 해결하기 위해 SFT 모델을 인간 선호도와 더욱 일치시키기 위해 RLHF을 구현했다.
대규모 언어 모델(LLM) 구축과 같은 성공적인 보상 모델을 만들기 위해서는 먼저 Pre-Trained를 거친 다음 미세 조정을 수행하는 것이 중요하다. 이러한 유형의 비교 데이터에 대해서도 미세 조정이 수행되지만 품질 주석이 있기 때문에 더 높은 품질로 수행된다.
미세 조정 단계에서는 다양한 프롬프트를 수집하고 QWEN 모델의 응답에 대한 사람의 피드백을 기반으로 보상 모델을 조정한다. 사용자 프롬프트의 다양성과 복잡성을 적절하게 고려하기 위해 약 6600개의 세부 태그로 분류 시스템을 만들고 보상 모델의 주석 요청을 선택할 때 다양성과 복잡성을 모두 고려하는 균형 잡힌 샘플링 알고리즘을 구현했다
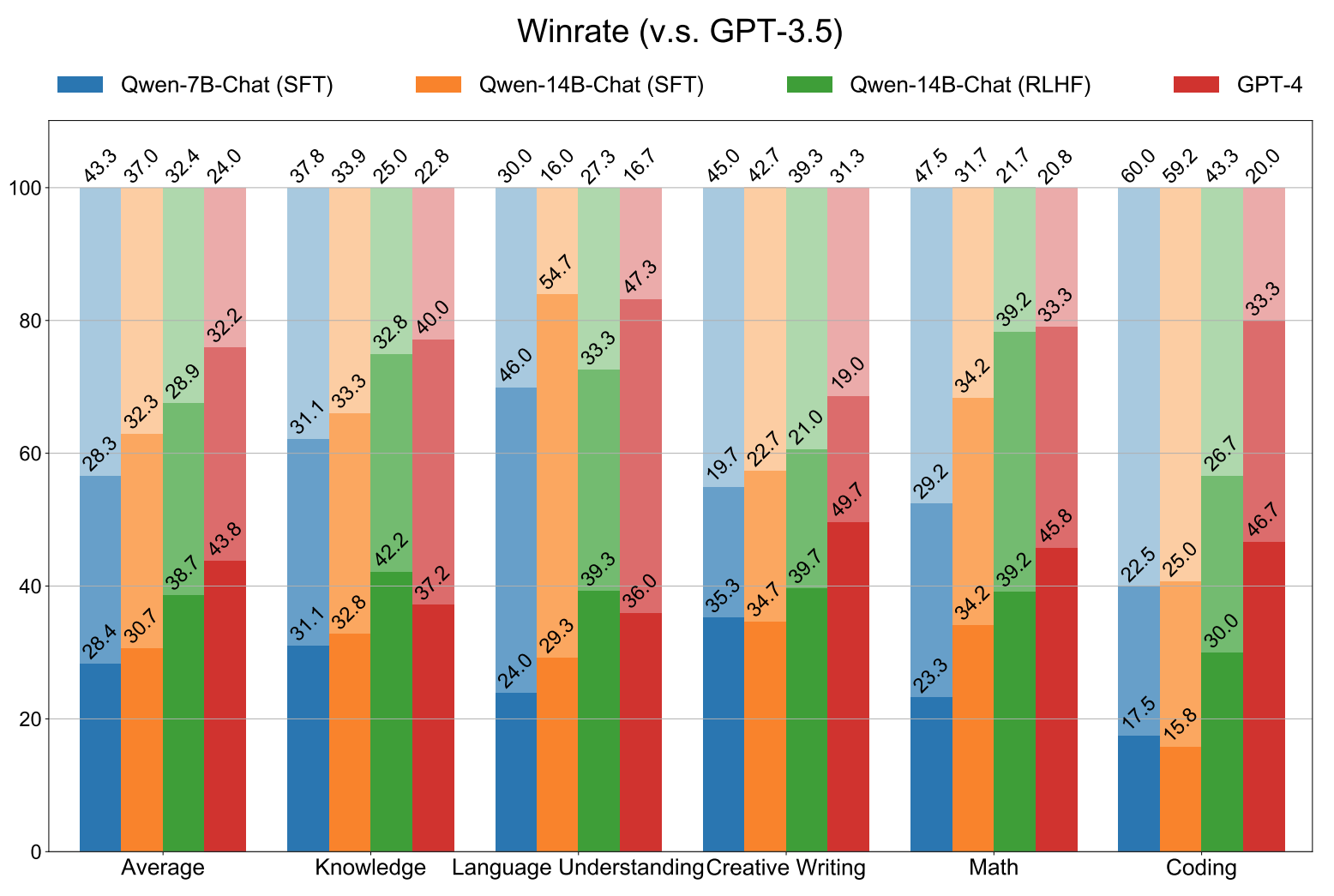
그렇게 완성된 채팅 모델에 대한 인간 평과 결과 그래프이다. GPT 3.5 와 각 모델들을 비교하였으며, 지시사항은 중국어로 입력되었다. 평균적을 QWEN 1 은 GPT 3.5 급 으로 보는것이 타당할듯 하다. GPT 4 보다는 확실히 열세라는 것을 확인할 수 있다.
4. 마치며
논문 내부에서는 데이터 처리 과정에 대해서 보다 상세히 설명되어 있으며, 요약해서 리뷰한 내용들도 풀어 설명되어 있다. 관심있다면 논문을 직접 보는것을 추천한다.
무엇보다 놀라운것은 이렇게 시작된 Qwen 1 → Qwen 1.5 → Qwen 2 의 성능변화인데, Qwen 2 에 와서는 LLaMA 3 를 확실히 이기는 성능지표를 보여주고 있고, 실제로 내 감상도 동일하다. GPT 4 에 비해서는 미세하게 열세로 보이나, Open LLM 기준해서는 가장 우수한 성능을 보여주는것이 Qwen 2 이다.
직접 사용하고 싶다면 Hugging-face 에서 Demo Site 를 운용중이므로 직접 체험해 보길 바란다. 다만 이 모델의 단점이라면 아무래도 중국 기업, 알리바바에서 학습된 모델이라 시진핑과 관련된 정보를 묻는다면 에러를 뿜는다(.....)
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (0) | 2025.01.22 |
|---|---|
| [리뷰] A Comprehensive Evaluation of Quantization Strategies for Large Language Models (2) | 2024.09.29 |
| [리뷰] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning (0) | 2024.03.31 |
| [리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.03.19 |
| [리뷰] TRIAAN-VC (0) | 2024.02.23 |