1. 서론
자연어 처리는 시간이 가면 갈수록 중요해지고 있다. Text to Speech, Speech to Text, Translation, GPT 에 이르기까지 그 발전 가능성은 무궁무진 하다. 특히 핵심적인 혁신은 모델 자체를 수정하는 데에서 오는 경우가 많지만, 그럼에도 불구하고 fine-tuning 은 중요하다.
하지만 모델의 사이즈가 점점 커져감에 따라 전체 fine-tuning은 매우 버거운 작업이 되었다. 예로 GPT-3 의 한 모델은 175B 개의 parameter가 존재하는데, 이런 무지막지한 모델을 fine-tuning 하는것은 어지간한 대규모 연구소 수준이 아니면 버거운 일이다.
때문에 저자들은 pre-trainied 모델의 가중치를 'freeze' 하고 transformer 아키텍처의 각 계층에 훈련 가능한 행렬을 주입하여 down stream 작업에 대한 훈련 가능한 매개변수의 수를 크게 줄이는, LoRA를 제안한다. 예로 GPT-3 175B fine-tuning 에 비해 LoRA 는 훈련 가능한 parameter 의 수를 10,000배, GPU 메모리 요구사항을 3배 가까이 줄일 수 있다.
LoRA 는 RoBERTa, DeBERTa, GPT-2, GPT-3에서 모델 품질 면에서 미세 조정과 동등하거나 더 나은 성능을 보이며, 학습 가능한 파라미터가 적음에도 불구하고, 높은 학습 처리량을 달성하고 어댑터와 달리 추가적인 추론(inference) 지연 시간 없이 작동한다.
2. 소개
자연어 처리의 많은 응용 프로그램들은 하나의 대규모 pre-trained 모델을 이용해 여러 다운스트림 응용 프로그램에 적응시키는데 의존한다. (실제 현재의 GPT가 그렇다. Python 코드 분석 특화용, 요리 특화용, 소설 시나리오 특화용 등등..)
이러한 '적응' 과정은 일반적으로 pre-trained 모델의 모든 parameter 를 업데이트하는, 즉 fine-tuning 을 통해서 이뤄진다. 하지만 fine-tuning 모든 parameter 를 업데이트 하여야 한다는 단점이 있다. 더 큰 모델이 계속해서 훈련됨에 따라 이러한 작업은 점점 힘들어 졌다. 예로, 위에서 언급했듯이 GPT-3 의 경우 1,750 억개의 파라미터가 존재한다.
이러한 문제점으로 인해 과거에 일부 parameter만 조정하거나, 외부 모듈을 학습시켜 이러한 점을 완화하려고 하였다. 이로인해 소수의 parameter만 저장, 로드하면 되므로 배포 운영의 효율성이 크게 향상되었다. 하지만 이러한 방법이 종종 fine-tuning 기준선과 일치하지 못해 모델의 품질 저하가 발생한다는 문제점이 있다.(즉 fine-tuning 과는 같은 수준의 성능을 달성하지 못한다.)
결국 모델의 크기나 복잡도를 줄이기 위해 일부 파라미터만 조정하거나, 외부 모듈을 추가하는 방법은 운영상의 효율성을 향상시킬 수 있으나, 이러한 접근방식이 모델의 전반적인 성능이나 작업 수행 능력을 저하시킬 수 있다. 때문에 결국 모델의 효율성과 품질 사이에서 균형을 찾아야 한다는 선택의 문제로 이어진다.

이미지의 변수들에 대한 설명은 아래와 같다.
- $h$ : hidden state
- $x$ : input data
- $W \in \mathbb{R^{d \times d}}$ : pre-trained 모델의 가중치 행렬, 해당 가중치는 '고정' 되어있고 업데이트 되지 않는다.
- $A, B$ : LoRA에 의해 도입된 새로운 행렬, $A$는 정규분포 $\mathcal{N}(0, \sigma^2)$ 을 사용해 초기화되며, $B$ 는 0 로 초기화된다. 해당 행렬들은 각각 $r$ 차원의 낮은 랭크를 가지며, 해당 차원은 모델의 본래 차원인 $d$에 비해 낮다.
보다 쉽게 설명하면 아래와 같다.

fine-tuning 방식은 왼쪽과 같다. Weight update 를 수행하는데, 만약 $\Delta W$ 에 10,000 개의 행과, 20,000 개의 열이 있다면, 200,000,000 개의 parameter 가 저장된다.
하지만 만약 $r = 8$ 인 $A$와 $B$를 선택한다면 $A$ 는 10,000 개의 행 8개의 열을 가지고, $B$ 8개의 행 20,000 개의 열을 가진다. 이는 곧 $10,000 \times 8 + 8 \times 20,000 = 240,000$ 개의 매개변수를 지니며, 이는 본래 매개변수인 0.2B 와는 830배 작은 수준이다.
결론적으로 LoRA 는 아래와 같은 특징을 지닌다.
- pre-trained 모델을 공유하여 다양한 작업을 위한 많은 작은 LoRA 모듈을 구축할 수 있다. $\Delta W$ 를 행렬 $A$와 $B$를 로 대체하여 공유 모델을 동결하고 효율적으로 작업을 전환할 수 있어 저장 요구 사항과 작업 전환 오버헤드를 크게 줄일 수 있다.
- LoRA는 대부분의 매개변수에 대해 기울기를 계산하거나 옵티마이저 상태를 유지할 필요가 없기 때문에 적응형 옵티마이저를 사용할 때 훈련을 더 효율적으로 만들고 하드웨어 요구사항을 최대 3배까지 낮춘다.
- 간단한 선형 설계를 통해 배포 시 학습 가능한 행렬과 동결 가중치를 병합할 수 있으며, 구성에 따라 완전히 미세 조정된 모델에 비해 추론 지연 시간(어댑터 레이어를 사용하는 경우, 이들의 추가적인 계산이 모델의 전체 추론 속도를 느리게 만들 수 있다.)이 도입되지 않는다
- LoRA는 이전의 많은 방법들과 직교하며, prefix-tuning 과 같은 많은 방법들과 결합될 수 있다.
대규모 신경망은 지연시간을 낮게 유지하기 위해 하드웨어 병렬처리에 의존하지만, 어댑터 계층은 순차적으로 처리되어야 한다. 이로 인해서 배치 크기가 1과 같이 작은 경우나, GPU 같은 하드웨어가 병렬처리를 충분히 활용하지 못하는 설정에서는 이러한 지연 시간이 특히 문제가 될 수 있다.
따라서 추론 성능을 극대화하고 싶을 때는 어댑터 레이어의 사용이 지연시간을 증가시킬 수 있다는 점을 고려하여야 한다.
3. LoRA 의 설계 및 장점
사전 학습된 가중치 행렬 $W_0 \in \mathbb{R^{d \times k}}$ 의 경우, 후자를 낮은 순위 분해. $W_0 + \Delta W = W_0 + BA$ 로 업데이트를 제한하며, 여기서 $B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k}$ 및 rank $r \ll min(d,k)$ 이다.
훈련중에 $W_0$ 는 기울기 업데이트를 수신하지 못하는 반면, $A, B$ 는 업데이트 된다.
$W_0$ 와 $\Delta W = BA$ 는 모두 동일한 입력으로 곱해지고, 각각의 출력벡터는 좌표 단위로 합산된다. $h = W_0 x$ 의 경우 forward pass 는 다음과 같이 산출된다.
$$ h = W_0 x + \Delta W x = W_0 x + BA_x $$
추가로 코드에서 살펴볼 수 있는 $\alpha$ 에 관한 내용이 여기서 나온다.

훈련과정을 시작할 때 $\Delta W$ 를 스케일링 하기 위해 스케일 인자 $\alpha$ 를 사용하며, 이는 가중치 변화의 크기를 조절하며, rank $r$ 에 따라 조정된다. Adam 옵티마이저를 사용할 때 $\alpha$ 를 조정하는것은 learning rate 를 조정하는 것과 같은 효과를 얻을 수 있다.
Understanding alpha parameter tuning in LORA paper
I was reading the LORA paper https://arxiv.org/pdf/2106.09685.pdf a thing I don’t understand is section 4.1, where the updates are updated by alpha, where alpha is a constant in r. It is said that ...
datascience.stackexchange.com
결론적으로 LoRA 는 기존 $\Delta W$ 와 병렬로 훈련 가능한 소규모 행렬을 추가하는 기법이다.
3. 실험.
저자들은 이러한 설계를 검증하기 위해서 여러 테스트를 진행했다. NVIDIA Tesla V100 을 사용하였다고 언급한다.

전체적인 지표를 보면 Fine-tuning 보다 LoRA 가 더 좋은 지표를 보이는것이 많다. Fine-Tuning 과 유사하거나, 더 우수하다고도 평할 만 하다.

GPT-2 테스트에서도 비슷한 결과를 보여준다. LoRA 는 더 적은 Trainable-Parameters 를 가지고 더 우수한 성능을 보여준다.
외에도 저자들은 여러 테스트를 거쳐 어떤 옵션을 조절하는것이 가장 좋은 성능을 내는지 기재하였다.

$W_q, W_v$ 를 모두 적용하면 전반적으로 최고의 성능을 얻을 수 있다고 언급한다. 물론 말이 그렇다는것이고, 엄밀히 보면 $W_q, W_k, W_v, W_o$ 를 모두 적용하는것이 평균적인 성능은 가장 좋을것이다.

대충 보면 알겠지만 $r$ 값을 증가시킨다고 해서 극적인 성능변화는 발생하지 않는다.
$r$ 과 $W_q, W_k, W_v, W_o$ 간의 관계를 한눈에 파악할 수 있어서 유용한 표이다.
4. 여담.
LoRA-PEFT - HuggingFace examples - LoRA does not train faster/nor does it allow a bigger batch size (essentially no improvement)
System Info Platform system: Windows-10-10.0.22621-SP0 Python version: 3.9.13 Available RAM : 31.872 GB CPU count: 20 CPU model: Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz GPU count: 1 GPU model: 1 ...
github.com
개인적으로 LoRA 를 테스트 해 보는데 여러 궁금증이 있어서 찾아보았고, 해당 답변에서 재미있는 내용을 들을 수 있었다.
논문에서 말하는 '효율성' 과 같은 단어들은 'training time' 단축을 의미하지 않는다.
따라서 계산 측면에서 고정되지 않은 모델과 비교할 때 차이가 거의 없습니다. 실제 절약되는 유일한 자원은 메모리입니다(고정된 가중치에 대해 grads+optim 상태를 할당할 필요가 없기 때문입니다). 따라서 훈련 속도 향상은 많은 요인에 따라 달라지며 이는 PEFT가 개선하겠다고 약속하는 것이 아닙니다. 이를 통해 기존 하드웨어에 대규모 모델을 맞추거나 더 큰 배치를 맞추는 동시에 전체 미세 조정과 비슷한 성능을 얻으려고 노력할 수 있습니다. 양자화 기술과 그래디언트 체크포인트는 메모리 요구 사항을 더욱 낮춥니다.
결론적으로 LoRA 와 같은 PEFT 는 '메모리 절약' 관점에서 이점이 있고, 기존 가중치를 유지하는데에서 의의를 찾을 수 있다.(무엇보다 fine-tuning 대비 성능저하가 거의 없다시피 한 것이 특징이다.)
요즘 크게 느끼는 점이, 사실 ASR 이던, 일반적인 LLM 이던, AI 분야의 뭐든 최근에 등장한 모델들은 parameter 를 많이 때려박고, 대용량의 데이터를 있는대로 다때려박으면 성능은 얼마든지 올라갈 수 있다. 실제로 많은 예제들을 살펴보면 알 수 있다.
하지만 안타깝게도 전력과 데이터의 양에는 한계가 있다. 얼핏 무한 해 보일수 있지만 그렇지 않다는것이다.

AMD 의 CEO 인 리사 수 박사는 최근 관련 프레젠테이션에서 이 문제점에 대해 언급했다.
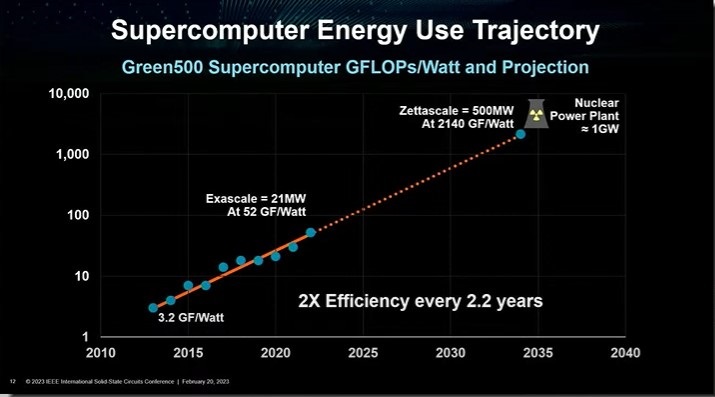
현재 발전 속도라면 2035년에 슈퍼컴퓨터를 구동하는데 원자력 발전소 한기와 맞먹는 전력이 필요할 것이다.
마찬가지로, AI 기술에서 중요한점은 '얼마나 좋은 성능을 낼 수 있느냐? 따위가 아니다.
'좋은 성능을, 얼마나 적당한 전력 선에서 낼 수 있는가?' 이다.
(이는 training, inference 관점에서 모두 포함된다.)
LoRA는 그 중 Training 전력 소모 관점에서 충분히 이점을 제공할 수 있는 기술이다.
추후 저전력 HW, AI 등의 발전이 더욱 크게 일어나서 휴대폰에서도 GPT 5 최고 파라미터를 구동하는 날이 오기를 기대한다. (아마 20년은 걸릴듯 싶다.)
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] QWEN TECHNICAL REPORT (0) | 2024.06.14 |
|---|---|
| [리뷰] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning (0) | 2024.03.31 |
| [리뷰] TRIAAN-VC (0) | 2024.02.23 |
| [리뷰] HiFi-VC: High Quality ASR-Based Voice Conversion (0) | 2024.02.20 |
| [리뷰] Low-resource expressive text-to-speech using data augmentation (0) | 2024.02.18 |