
최근 DeepSeek 라는 중국 스타트업에서 제작한 LLM 모델이 뛰어난 성능으로 AI 업계에서 화두가 되고 있다. 해당 업체에서 만든 모델은 대표적으로 `R1` 모델과 `V3` 모델이 존재하는데, `V3` 모델의 경우 ChatGPT, Qwen, LLaMA 와 같은 일반적인 `Transformer` 기반의 LLM 모델이다.
반면 `R1` 모델은 논문의 제목을 보면 알 수 있듯 `Reinforcement Learning`을 기반으로 제작된 모델로, 해당 포스팅에서는 `R1` 모델과, 논문에 관해서 간략히 포스팅 하겠다.
1. 서론
강화학습을 LLM에 적용하자는 계념을 DeepSeek 사가 최초로 제안한것은 아니다. 최근 ChatGPT의 유료버전을 사용해 보았다면 `o1` 모델이 활성화 된 것을 확인할 수 있었을 것이다.

`GPT-4o` 모델은 Transformer 모델을 기반으로 작동하지만, `o1` 모델은 강화학습을 기반으로 작동한다. 이는 OpenAI 사의 Blog에 기재되어 있는 내용이다.
Our large-scale `reinforcement learning` algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of `o1` consistently improves with more `reinforcement learning` (train-time compute) and with more time spent thinking (test-tiChain of Thoughtme compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.
OpenAI 측에서는 강화학습을 기반으로 '사고의 연쇄(Chain of Thought, CoT)' 방식을 구현하여 큰 성능 향상을 이루어 내었다. 이를 통해 LLM 모델은 아래와 같은 작업들을 수행할 수 있다.
- 큰 문제를 작은 문제로 분할해서 생각하는 방법
- 실수를 인정하고, 이를 기반으로 수정하는 방법
- 현재 접근 방식이 작동하지 않을 때 다른 접근 방식을 시도하는 방법
이는 마치 인간이 사고하는 방법과 유사하다.
하지만 최근까지 어떤 다른 모델도 `o1` 모델과 동등한 수준의 성능을 달성하지 못했다. 반면 `R1` 모델은 최초로 `V3` 기반모델에 순수한 강화학습과 SFT를 적용하여 `o1`모델에 근접한 성능지표를 보여준다.

특히, 그래프에는 나타나있지 않지만 `V3` 기반모델에 순수한 강화학습을 적용하여 개발한 `DeepSeek-R1-Zero` 모델은 SFT(Supervised Fine-Tuning) 같은 작업 없이 `OpenAI-o1-0912` 와 유사한 성능지표를 보여주었으나, 가독성 저하 및 다국어 혼용 문제를 겪었다.
이러한 문제를 해결하기 위해 DeepSeek 사에서는 Qwen, LLaMA 모델을 통해 추론 능력을 '증류(Distill)' 한 뒤(32B) SFT를 적용하여 모델을 완성했다. 가장 왼쪽에 존재하는 `R1` 모델은 MoE 모델로서 증류 과정을 거치지 않고, 강화학습과 SFT 만을 통해 반복 학습되었다.
여기서 고무적인 사실은 강화학습 만으로 학습시킨 `R1-Zero` 모델이 매우 유망한 성능을 보여준다는 점이다. SFT는 매우 큰 인건비를 지출하게 된다.그런데 오직 소량의 Cold-Start Data 와 강화학습만으로 학습한 모델의 성능이, 최신 SFT 튜닝모델 대비 3개월 정도의 뒤쳐진 성능을 보여준다는건 매우 큰 성과이다.
이것이 해당 논문의 핵심적인 요약이다. 비록 chat.deepseek.com 에서 운용하는 모델은 SFT를 거친 모델이지만, 단순 강화학습 만으로도 이렇게 뛰어난 성능의 모델을 제작할 수 있음을 오픈소스로 증명해 낸 것이 `DeepSeek-R1-Zero` 모델이다.
2. 중요한 내용은 명시되어 있지 않다.
논문에서 DeepSeek 모델의 '보상함수' 와 같은 상세한 구현 방법을 기재하지 않았다. 대략적으로 `2.2.2. Reward Modeling` 섹션에서는 아래와 같이 기술되어 있는데.
Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box), enabling reliable rule-based verification of correctness. Similarly, for LeetCode problems, a compiler can be used to generate feedback based on predefined test cases.
수학문제나, LeetCode 문제와 같은 작업의 경우 최종적인 정답 여부를 rule-base 기반하에 판단한다고 기재되어 있다.
하지만 위와 같이 대략적으로만 기재해 두었을 뿐, 구체적으로 어떻게 구현하는지, 또 왜 이러한 접근 방식이 효율적인지 심층적인 원리나 분석은 논문에 밝히지 않고 있다. 물론, 아래와 같은 GRPO 수식은 나열하고 있지만.
$$ \mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E}\left[ \frac{1}{G} \sum_{i=1}^{G} \left( \min\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip}\left( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) - \beta \mathbb{D}_{\text{KL}}(\pi_\theta || \pi_{\text{ref}}) \right) \right] $$
GRPO의 목표는 새로운 정책($\pi_\theta(o_i|q)$)이 이전 정책($ \pi_{\theta_{\text{old}}}(o_i|q)$) 보다 높은 보상을 얻도록 업데이트 하는 과정을 유도하여 좋은 결과를 내도록 하는것이 목적이다. 그런데 문제는 '어떤 판단 기준으로 새로운 정책에 더 높은 보상을 줄 것인가?' 에 대한 내용이 누락되어 있다. 보상로직이 핵심인데, 이 부분이 논문에 명시되어 있지 않다.
3. MoE
부가적으로 해당 모델에서는 MoE가 적용되었다.

4번 테이블에서 DeepSeek 의 모델들을 살펴보면 재미있는 부분이 눈에 띈다. 바로 MoE 라고 하는 부분으로서, 총 파라미터 양은 671B로 매우 거대하지만, 실제로 순간적으로 활성화 되는 Activated Params 는 37B에 불과하다.
MoE 기술을 간단하게 요약하자면 아래와 같다.
하나의 연산과정을 여러개의 전문가(expert) 하위 네트워크로 분할하는 방법.
분할된 네트워크는 각각 독립적으로 자체적인 연산을 수행하며, 그 결과를 결합하여 MoE 레이어의 최종 출력을 생성한다.
AI를 공부해 보았다면 '앙상블 기법' 이라는 기법을 들어 보았을것이다. 앙상블 기법의 경우 관여하는 모든 모델이 전체 입력에 참여해서 최종적인 추론결과를 내놓는 다소 고전적인 기법이라면, MoE 기법은 입력 토큰마다 특정 하위 네트워크가 선택적으로 활성화되어 보다 효율적인 추론이 가능하다.
적절한 비유가 아니라고 지적할 수도 있겠지만, MoE 기법은 앙상블 기법을 크게 고도화하여 하나의 신경망 내에 구현한 구조라고 비유할 수 있겠다.
3. 결론

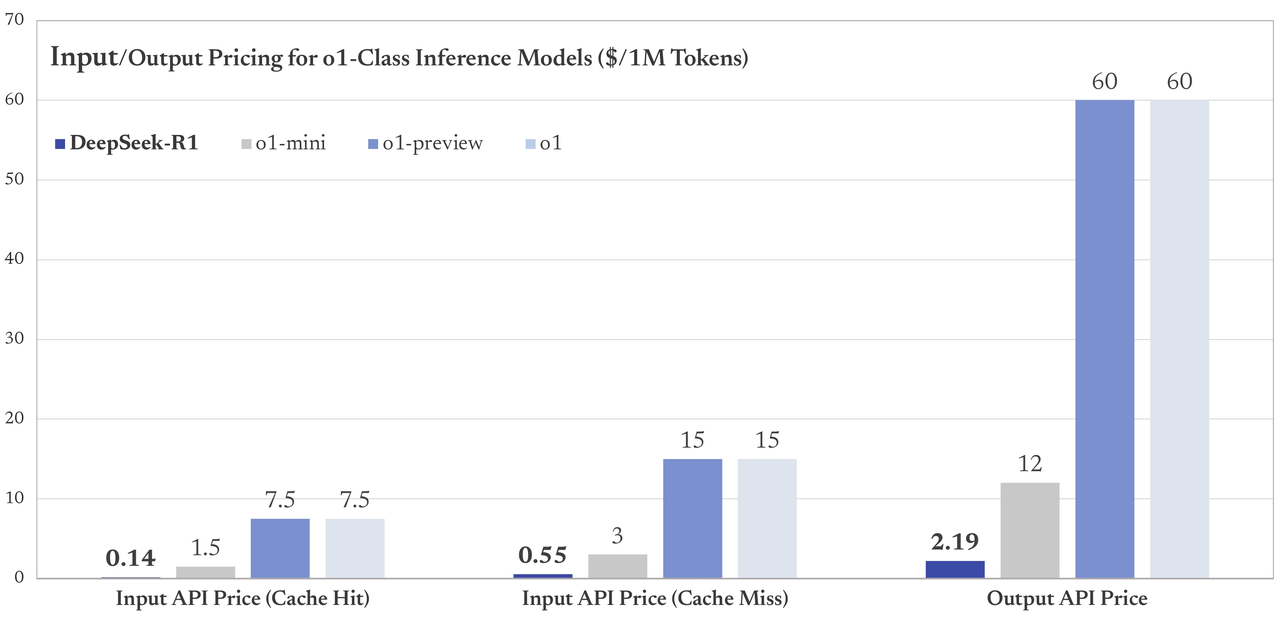
DeepSeek R1 모델은 o1 모델과 동등한 성능을 제공하며, 추론 비용은 ${1 \over 27.3}$ 이다.
이는 기반이 되는 V3 모델의 추론 비용이 저렴한것이 가장 큰 원인으로 추정된다.(Chain of Thought)
4. 소감
결론적으로 논문을 읽어보며, 반쪽짜리 라는 감을 지울 순 없었지만(모델은 훌륭하다. 많은 제작 과정을 숨겼을뿐...), Transformer 기반 모델에 강화학습을 적용하여 튜닝을 거친것 만으로 이렇게 뛰어난 성능이 도출된다는점이 흥미로웠다. 실제로 DeepSeek 모델을 테스트 해 본 결과 OpenAI 사의 GPT 모델과 성능 차이를 느끼지 못했다.
추가로 나는 이 논문의 초입부를 읽기 시작한 뒤, 이제 Transformer 기반 모델이 더이상 LLM에서 필요 없어진것이 아닐까? 라는 생각을 잠깐 했었지만. 아래와 같은 장단점들이 존재한다.
- Transformer 모델이 더 효율적이며(without using CoT), 창의적인 결과물을 내 놓을 수 있다.
- 강화학습 기반의 모델들은 정답이 명확히 정해진 작업들에서 더 우수한 성능을 보여주나, 그 원리 특성상(CoT) 속도가 느리다.
더하여 강화학습으로 만들어진 LLM 모델은, Transformer 모델을 기반으로 강화학습을 통해 튜닝을 거친것이므로 여전히 씨앗 역할을 하는 Transformer 모델은 중요하다.
'Artificial Intelligence > Article' 카테고리의 다른 글
| [리뷰] DeepSeek-V3 Technical Report (0) | 2025.01.26 |
|---|---|
| [리뷰] A Comprehensive Evaluation of Quantization Strategies for Large Language Models (2) | 2024.09.29 |
| [리뷰] QWEN TECHNICAL REPORT (0) | 2024.06.14 |
| [리뷰] AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning (0) | 2024.03.31 |
| [리뷰] LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.03.19 |