![]()
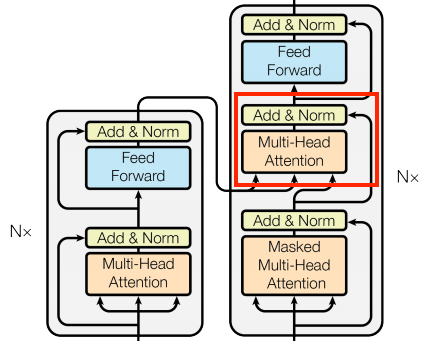
Attention Is All You Need 는 Transformer 기술을 소개하는 논문으로서, 이전에 한차례 리뷰한 바가 있다. 이 중 CrossAttention 에 대한 한국어 포스팅이 많지 않아보여 작성해본다. Transformer 는 Translation, VC, STT, TTS등 시계열 데이터를 처리하는데에 있어 사용할 수 있다. 즉 Decoder 의 출력은 Text 가 될수도 있고, Mel Spectrogram 형태가 될수도 있으며, 아마 '영상' 쪽으로도 출력을 내는게 가능할 것이다. (여기서는 번역을 기준으로 작성하겠다.) 붉은박스로 표시한 CrossAttention 은 좌측의 Encoder 단에서 나오는 출력이, 우측의 Decoder 단으로 들어가는 구조이다. 먼저 코드를 살펴보자. ..
![]()
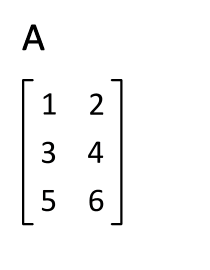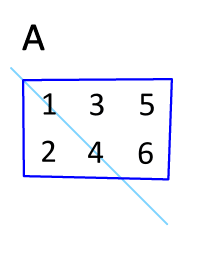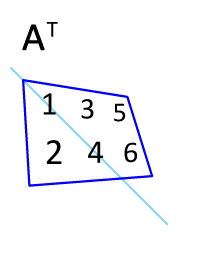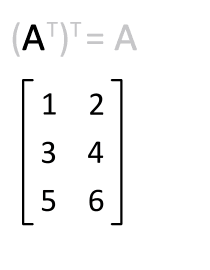
이전 포스팅의 주제인 AdaLoRA 는 행렬에 대해 잘 알지 못하면 그 원리를 근본까지 이해하기 힘든 구성을 지니고 있다. 최종적으로 이해는 했지만 이를 정리해 두지 않으면 한달만 지나면 다 까먹을 것이기 때문에 기록해 둔다. 행렬 역행렬 전치행렬 대칭행렬 항등행렬(단위행렬) 대각행렬 직교행렬 및 행렬연산 특성에 관해서 설명한다. 1. 행렬(matrix) $$ \begin{equation} \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{bmatrix} \end{equation} $$ 행렬에 관해서 모르는 사람은 없으리라 본다. Excel 을 다뤄본 경험이 있다면 행..
![]()
해당 논문은 LoRA 를 개선한 버전인 AdaLoRA 에 대해 제안하는 논문이다. 1. 서론기존 Full Fine-Tuning, LoRA 는 NLP 에서 중요한 패러다임이 되었으나, 일반적으로 '모든' parameter 를 미세 조정하기에 최적의 조정을 수행할 수 없다는 단점이 있다.이러한 문제를 해결하기 위해 가중치 행렬 간 parameter 자원(budget) 을 중요도 점수에 따라 적응적으로 할당하는 AdaLoRA 를 제안한다. 특히 AdaLoRa 는 특이값 분해(Singular Value Decomposition, SVD)의 형태로 증분 업데이트를 parameter 화 한다. 이러한 접근 방식을 통해 중요하지 않은 업데이트의 특이값을 효과적으로 가지치기할 수 있으며, 이는 본질적으로 p..
![]()
1. 서론 자연어 처리는 시간이 가면 갈수록 중요해지고 있다. Text to Speech, Speech to Text, Translation, GPT 에 이르기까지 그 발전 가능성은 무궁무진 하다. 특히 핵심적인 혁신은 모델 자체를 수정하거나, parameter 를 증가시키는 데에서 오는 경우가 많지만, 그럼에도 불구하고 fine-tuning 은 중요하다. 하지만 모델의 사이즈가 점점 커져감에 따라 전체 fine-tuning 은 매우 버거운 작업이 되었다. 예로 GPT-3 의 한 모델은 175B 개의 parameter 가 존재하는데, 이런 무지막지한 모델을 fine-tuning 하는것은 어지간한 대규모 연구소 수준이 아니면 버거운 일이다. 때문에 저자들은 pre-trainied 된 모델의 가중치를 'fr..
모델을 훈련할때 평가과정은 보통 epoch 로 진행하는데, 간혹 특정 예제들은 steps 로 진행되기도 한다. 예로 Seq2SeqTrainingArguments 의 설정 옵션을 살펴보면 evaluation_strategy (str or IntervalStrategy, optional, defaults to "no") - The evaluation strategy to adopt during training. Possible values are: "no": No evaluation is done during training. "steps": Evaluation is done (and logged) every eval_steps. "epoch": Evaluation is done at the end of e..
여러 모델을 학습시키는데에는 batch_size 옵션을 지정해 주어야 한다. 나의 경우 Transformer 를 학습시킬때 사용되는 Seq2SeqTrainingArguments 의 batch_size 옵션을 지정하기 위해 batch_size 의 계념에 관해 살펴보았다. Seq2SeqTrainingArguments 에서 batch_size 옵션은 per_device_train_batch_size (int, optional, defaults to 8) : The batch size per GPU/XPU/TPU/MPS/NPU core/CPU for training. 로서, 이는 '모델이 한번에 학습하는 데이터 샘플수' 이다. 이러한 batch_size 를 지정하는데는 아래와 같은 장, 단점이 존재한다. 큰 b..
![]()
TRIAAN-VC 논문은 any-to-any voice conversion 을 수행하는 모델이다. 나는 IEEE 에서 여러 VC 논문들을 찾아보았다. 특히 2020년 이후에 제작된 any-to-any 모델들을 중점적으로 살펴보았다. 그간 VC 관련 논문들을 꽤 많이 읽어보았고, 그에 따른 결론은 '구조가 어떻게 되든 일단 성능이 최고인 것을 찾자' 였다. Speech 데이터를 생성하는 모델은 성능을 평가하기가 '까다롭다'. 보통 많은 청취자를 동원해서 직접 사람이 통계적으로 평가를 하는 MOS 지표를 토대로 평가한다. 좀 비 과학적으로 보일 수 있어도, MOS 점수가 내가 주관적으로 느끼는 모델의 실제 성능과 엇나간 적은 없다. 어쨋든 IEEE 에서 여러 논문들을 검색해 본 결과, 일부 모델들은 MOS ..
![]()
해당 논문은 Voice Conversion 모델중 하나인 HiFi-VC 를 제안하는 논문이다. HiFi-GAN 을 기반으로 제작된 이 모델은 이전에 리뷰한 StarGANv2-VC 와 다르게 any-to-any 가 가능하다. many-to-many 의 경우 반드시 학습된 음성만 Target 으로 둘 수 있다.(학습되지 않은 target 으로 변환할 경우 품질이 심각하게 저하된다.) 반면 any-to-any 의 경우 훈련중 학습되지 않은 '모든' 화자로의 음성 변환을 목적으로 한다. 때문에 any-to-any 는 모델 학습적인 관점에서 many-to-many 보다 어렵지만 실제로 사용할 때는 더 유용하게 사용할 수 있다. Hifi-VC 모델은 이러한 any-to-any 가 가능한 모델로서 활용성이 높다. 1..
![]()
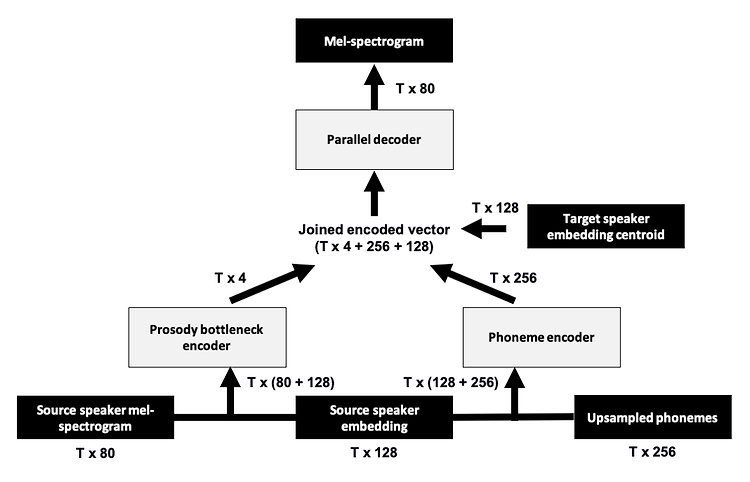
해당 논문은 진행중인 연구와 매우 밀접한 연관이 존재하여 읽게 되었다. Amazon Alexa 팀에서 2021년 발표한 논문으로 Voice Conversion 을 통해 Data Augmentation 하여 TTS 를 제작, 데이터 부족 환경에서 VC로 생성된 데이터가 유용하게 사용될 수 있다고 가능성을 보여준 논문이다. 1. 요약 최근의 Text To Speech(TTS) 시스템은 매우 잘 작동하지만, 원하는 발화 스타일로 TTS 하려면 상당한 양의 녹음이 필요하다. 해당 논문에서는 불과 15분의 녹음으로 표현 스타일 음성을 구축하기 위해 새로운 3단계 방법론을 제시한다. 다른 화자의 원하는 발화 스타일의 녹음을 사용하여 Voice Conversion 을 적용해 Data augment 한다.(합성 데이터..
![]()
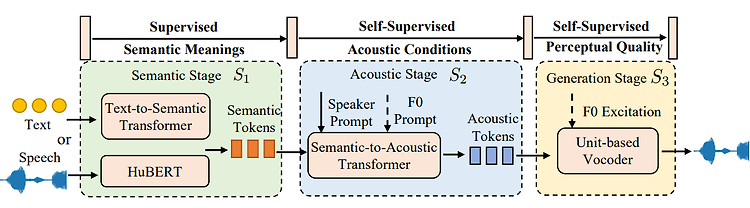
Make-A-Voice 논문에 관해 간단히 분석하는 포스팅이다. 해당 논문에 대한 몇몇 리뷰는 openreview.net 에서 확인 해 볼 수 있다. 해당 리뷰들을 참고하며 개인 의견 몇가지를 이야기하고자 한다. 1. 소개 음성합성은 인간의 음성을 생성하는 것을 목표로 하며, 특히 제로샷 성능을 향상시키기 위해서 수많은 데이터를 기반으로 인간의 음성 다양성을 캡처, 표현을 예측하는 방법이 많이 개발되었다. 하지만 이러한 방법들은 ‘음성 생성’ 이라는 공통 목표를 둠에도 불구하고 독립적으로 개발되었다. 때문에 각 애플리케이션에 대해 개발된 방법론은 여전히 ‘독립적’ 이며, 별도로 각 모델을 최적화해야 하기에 비 효율적이다. 이 논문은 뭔가 새로운 모델을 제시하지는 않는다. 결국 Make-A-Voice 라는..