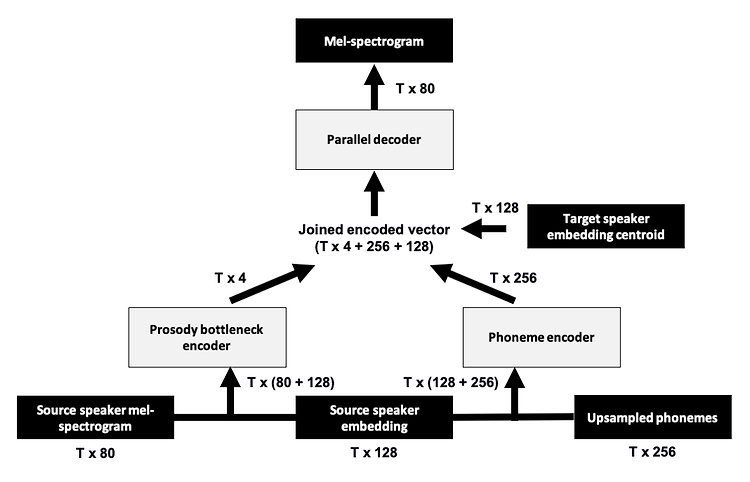
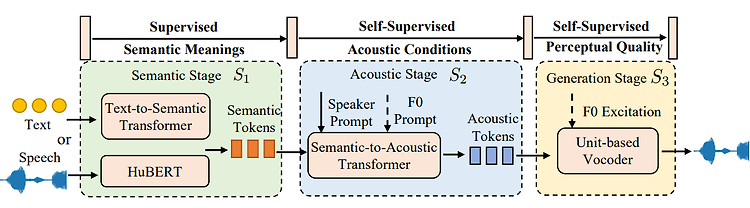
batch_size 란?
·
Artificial Intelligence/Basic
여러 모델을 학습시키는데에는 batch_size 옵션을 지정해 주어야 한다. 나의 경우 Transformer 를 학습시킬때 사용되는 Seq2SeqTrainingArguments 의 batch_size 옵션을 지정하기 위해 batch_size 의 계념에 관해 살펴보았다. Seq2SeqTrainingArguments 에서 batch_size 옵션은 per_device_train_batch_size (int, optional, defaults to 8) : The batch size per GPU/XPU/TPU/MPS/NPU core/CPU for training. 로서, 이는 '모델이 한번에 학습하는 데이터 샘플수' 이다. 이러한 batch_size 를 지정하는데는 아래와 같은 장, 단점이 존재한다. 큰 b..